
解决Scrapy性能问题——案例一(CPU饱和)
linux-dash
A beautiful web dashboard for Linux
项目地址:https://gitcode.com/gh_mirrors/li/linux-dash
·
症状:有时你增加并发水平,但是性能没有增长。下载器的利用也很充分,但是似乎每个请求的平均时间都很长。在Unix/Linux上使用top命令或者在Power Shell上使用ps或者在Windows上面使用任务管理器时,发现发现CPU的负载很高。
示例:假设你运行了以下的命令:
$ for concurrent in 25 50 100 150 200; do
time scrapy crawl speed -s SPEED_TOTAL_ITEMS=5000 -s CONCURRENT_REQUESTS=$concurrent
done然后就能得到抓取5000个URL所需的时间,如下面的表格所示,Expected栏是基于前面的分析得到的公式得来的,CPU负载是由top命令观察到的。
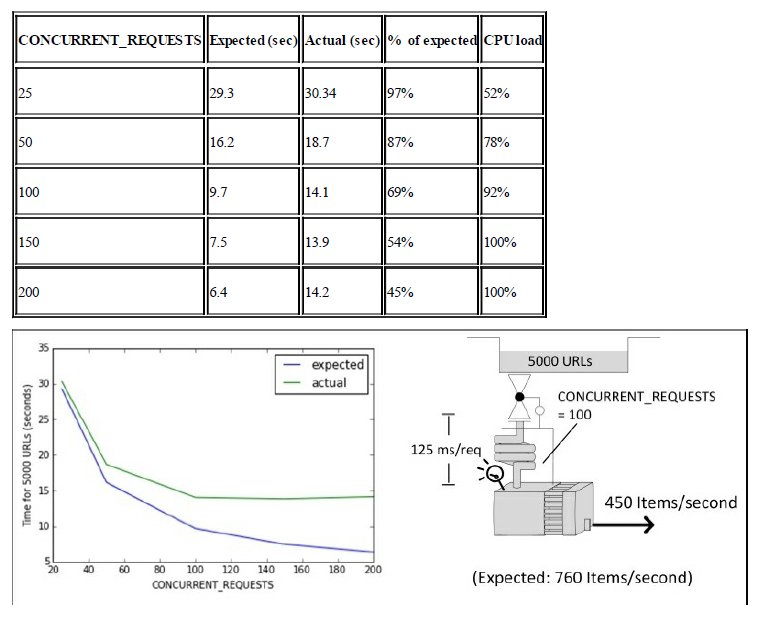
在我们的实验中,没有进行任何的处理,这是我们能够使用如此高的并发的原因,在一个更复杂的系统中,这种情况在低一些的并发时就会出现。
讨论:Scrapy只使用一个线程,当你达到高并发的水平时,CPU就有可能变成了瓶颈。如果你没有使用线程池,那么Scrapy建议只使用80%-90%的CPU。其他的系统资源也有可能出现相同的问题,比如网络带宽、内存和磁盘吞吐量,但是所有的这些资源出现问题的可能性没有CPU那么大,而且就算出现了也是普通的系统管理方面的研究内容了,所以此处不会再涉及。
解决方案:假设你的代码写得还算是有效率,你可以通过在相同的服务器上面运行多个Scrapy爬虫来得到比CONCURRENT_REQUESTS更大的并发水平。如果其他的服务器或者你程序中的pipeline衍生出去的线程对CPU的要求不高的话,这样可以更好地利用CPU。如果你还是需要更高的并发,那就可以多个服务器来做个分布式的爬虫,在这种情况下你也会同时需要更多的内存、网络带宽和硬盘的吞吐量。一定要记得高并发水平下,CPU是主要的限制因素。
A beautiful web dashboard for Linux
最近提交(Master分支:2 个月前 )
186a802e
added ecosystem file for PM2 4 年前
5def40a3
Add host customization support for the NodeJS version 4 年前

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)