linux内核之进程管理详解
1、进程描述符
(1)进程与线程
进程是处于执行期的程序以及相关资源的总称。线程在linux上称为轻量级进程,没有独立的地址空间,一个进程下的所有线程共享地址空间、文件系统资源、文件描述符、信号处理程序等。
(2)进程描述符task_struct
内核把进程的列表存放在叫做任务队列的双向循环链表中。链表中的每一个项都是类型为task_struct(即进程描述符的结构),它包含了一个具体进程的所有相关信息。通过slab分配器分配task_struct结构,这样方便对象复用和缓存着色。该结构体有些大,下图只是指出其中比较重要的成员部分。
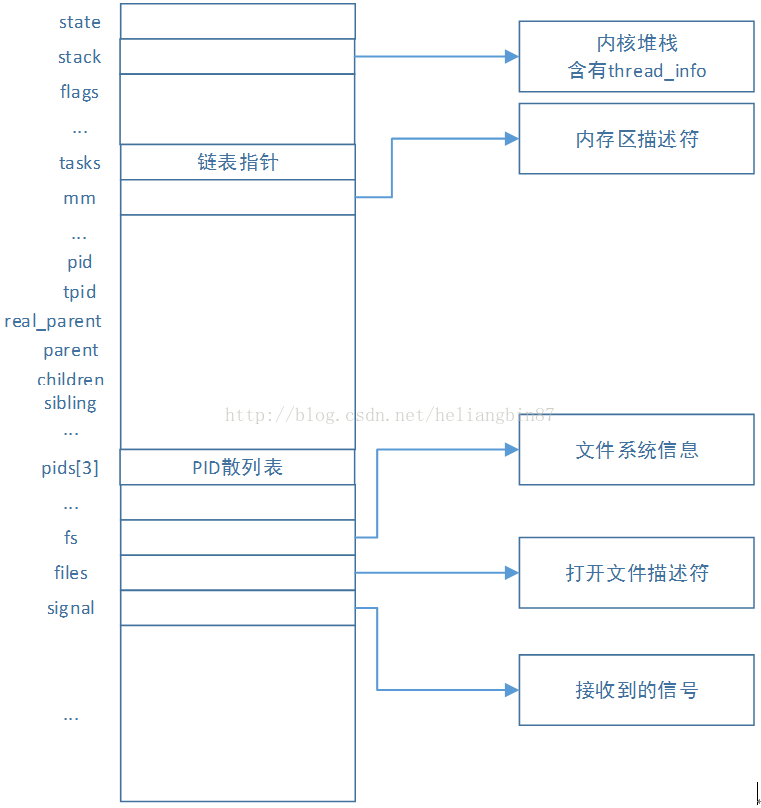
A.state状态
TASK_RUNNING表示进程要么正在执行,要么正要准备执行。
TASK_INTERRUPTIBLE表示进程被阻塞(睡眠),直到某个条件变为真。条件一旦达成,进程的状态就被设置为TASK_RUNNING。
TASK_UNINTERRUPTIBLE的意义与TASK_INTERRUPTIBLE类似,除了不能通过接受一个信号来唤醒以外。
__TASK_STOPPED表示进程被停止执行。
__TASK_TRACED表示进程被debugger等进程监视。
EXIT_ZOMBIE表示进程的执行被终止,但是其父进程还没有使用wait()等系统调用来获知它的终止信息。
EXIT_DEAD表示进程的最终状态。
EXIT_ZOMBIE和EXIT_DEAD也可以存放在exit_state成员中
B.进程标识符
内核通过一个唯一的进程标示值或PID来标识每一个进程。
C.内核堆栈stack
内核通过thread_union联合体来表示进程的内核栈,其中THREAD_SIZE宏的大小为8192(首地址按照8192对齐),包含thread_info大小,实际可用栈小于8192字节(见下节分析)。
当进程从用户态切换到内核态时,进程的内核栈总是空的,所以ARM的sp寄存器指向这个栈的顶端。因此,内核能够轻易地通过sp寄存器(因为对齐,低13位置0即首地址)获得当前正在CPU上运行的进程。
D.进程亲属关系成员
在Linux系统中,所有进程之间都有着直接或间接地联系,每个进程都有其父进程,也可能有零个或多个子进程。拥有同一父进程的所有进程具有兄弟关系。
real_parent指向其父进程,如果创建它的父进程不再存在,则指向PID为1的init进程。
parent指向其父进程,当它终止时,必须向它的父进程发送信号。它的值通常与real_parent相同。
children表示链表的头部,链表中的所有元素都是它的子进程。
sibling用于把当前进程插入到兄弟链表中。
group_leader指向其所在进程组的领头进程
E.进程调度
实时优先级范围是0到MAX_RT_PRIO-1(即99),而普通进程的静态优先级范围是从MAX_RT_PRIO到MAX_PRIO-1(即100到139)。值越大静态优先级越低。
static_prio用于保存静态优先级,可以通过nice系统调用来进行修改。
rt_priority用于保存实时优先级。
normal_prio的值取决于静态优先级和调度策略。
prio用于保存动态优先级。
policy表示进程的调度策略,目前主要有以下五种:
SCHED_NORMAL用于普通进程,通过CFS调度器实现。
SCHED_BATCH用于非交互的处理器消耗型进程
SCHED_IDLE是在系统负载很低时使用。
SCHED_FIFO(先入先出调度算法)和SCHED_RR(轮流调度算法)都是实时调度策略
F.进程地址空间
mm指向进程所拥有的内存描述符,而active_mm指向进程运行时所使用的内存描述符。对于普通进程而言,这两个指针变量的值相同。但是,内核线程不拥有任何内存描述符,所以它们的mm成员总是为NULL。当内核线程得以运行时,它的active_mm成员被初始化为前一个运行进程的active_mm值。
G.信号处理
signal指向进程的信号描述符。
sighand指向进程的信号处理程序描述符。
blocked表示被阻塞信号的掩码,real_blocked表示临时掩码。
pending存放私有挂起信号的数据结构。
sas_ss_sp是信号处理程序备用堆栈的地址,sas_ss_size表示堆栈的大小。
设备驱动程序常用notifier指向的函数来阻塞进程的某些信号(notifier_mask是这些信号的位掩码),notifier_data指的是notifier所指向的函数可能使用的数据
(3)thread_info
在2.6以前的内核中,各个进程的task_struct存放在它们内核栈的尾端,目的是为了让那些像X86那样寄存器较少的硬件体系结构只要通过栈指针就能计算出它的位置,而避免使用额外的寄存器专门记录。现在用slab分配器动态生成task_struct,所以只需在栈底(对于向下增长的栈来说)或栈顶(向上增长的栈来说)创建一个thread_info,通过它指向该进程的task_struct。内核栈的实现在上面已经提到,如下:
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
总大小8192,其中包含了thread_info大小,实际可用栈<8192字节。
/*
*low level task data that entry.S needs immediate access to.
*__switch_to() assumes cpu_context follows immediately after cpu_domain.
*/
struct thread_info {
unsigned long flags; /* low level flags */
int preempt_count; /* 0 => preemptable, <0 => bug */
mm_segment_t addr_limit; /*address limit */
struct task_struct *task; /* main task structure*/指向task_struct
struct exec_domain *exec_domain; /* executiondomain */
__u32 cpu; /* cpu */
__u32 cpu_domain; /* cpudomain */
struct cpu_context_save cpu_context; /* cpu context */存放CPU寄存器内容,在任务切换时加载或保存
__u32 syscall; /* syscall number */
__u8 used_cp[16]; /* thread used copro */
unsignedlong tp_value;
#ifdef CONFIG_CRUNCH
structcrunch_state crunchstate;
#endif
union fp_state fpstate__attribute__((aligned(8)));
union vfp_state vfpstate;
#ifdef CONFIG_ARM_THUMBEE
unsigned long thumbee_state; /* ThumbEE HandlerBase register */
#endif
struct restart_block restart_block;
};
struct cpu_context_save { //各个寄存器的值
__u32 r4;
__u32 r5;
__u32 r6;
__u32 r7;
__u32 r8;
__u32 r9;
__u32 sl;
__u32 fp;
__u32 sp;
__u32 pc;
__u32 extra[2]; /* Xscale 'acc' register, etc */
};
初始的task_struct和thread_info见下一章节分析
2、进程创建
(1)普通进程
Linux创建进程分解到两个单独的函数中去执行:fork()和exec()。首先,fork()通过拷贝当前进程创建一个子进程,子进程与父进程的区别仅仅在于PID、PPID和某些资源和统计量。exec()函数负责读取可执行文件并载入地址空间开始运行。
fork()使用写时拷贝页实现,那么实际开销就是复制父进程的页表以及子进程创建唯一的进程描述符。
vfork()与fork()功能相同,唯一的不同是vfork不拷贝父进程的页表项(理想情况下,尽量不要用vfork防止exec失败情况)。
fork()、vfork()和__clone()库函数都根据各自需要的参数标志调用clone()系统调用,然后由clone调用内核do_fork()接口。
do_fork(kernel/fork.c)完成了创建中的大部分工作,主体实现函数copy_process()。copy_process主要完成以下工作:
A.调用dup_task_struct()为新进程创建一个内核栈、thread_info结构和task_struct,这些值与当前进程值相同。此时,子进程和父进程的描述符完全相同。
B.检查并确保新创建这个子进程后,当前用户拥有的进程数目没有超出给它分配的资源限制。
C.子进程着手是自己与父进程区别开来。
D.子进程状态被设置为TASK_UNINTERRUPTIBLE,防止它投入运行
E.调用copy_flags()更新task_struct的flags成员
F.调用alloc_pid()为新进程分配一个有效的PID
G.根据参数标志,拷贝或共享打开的文件、文件系统信息、信号处理函数、进程地址空间和命名空间等。
H.扫尾工作并返回一个指向子进程的指针。
再回到do_fork()函数,如果copy_process()函数成功返回,新创建的子进程被唤醒并让其投入运行,内核有意选择子程序首先执行。一般子进程都会马上调用exec()函数,这样可以避免写时拷贝的额外开销。
(2)内核线程
内核经常需要在后台执行一些操作(如刷磁盘,空闲页回收等),这种任务可以交给内核线程。内核线程有一下几点不同:
没有独立的地址空间,所有内核线程共享地址空间。
只运行在内核态,从不切换到用户空间
只能使用大于PAGE_OFFSET的线性地址空间
但是和普通进程一样,可以被调度,可以被抢占。
内核线程可以通过kernel_thread和kthread_create创建,两者主要不同点:
A.kthread_create创建的内核线程有干净的上下文环境,适合于驱动模块或用户空间的程序创建内核线程使用,不会把某些内核信息暴露给用户程序。
B.二者创建的父进程不同:kernel_thread创建的进程可以是init或其他内核线程,其中kernel_init(1号进程)和kthreadd(2号进程)就是该方法创建;kthread_ctreate创建的进程的父进程被指定kthreadd。
C.kthread_create是kthread_create_on_node的宏定义,该函数主要是将要创建的线程放到队列里,然后唤醒kthreadd内核线程调用create_kthread接口创建,在完成创建之前kthread_create_on_node一直等待。
(3)进程0、1、2
所有进程的祖先叫做进程0(idle进程),它是在linux的初始化阶段从无到有创建的一个内核线程,唯一使用静态分配数据结构的进程(所有其他进程的数据结构都是动态分配),所以这些静态分配的数据结构也顺其自然的变成链表的头。在init/init_task.c定义:
struct task_struct init_task =INIT_TASK(init_task) //进程描述符
.stack = &init_thread_info
.mm = NULL //内核线程没有独立内存地址空间
.active_mm = &init_mm
.tasks = LIST_HEAD_INIT(tsk.tasks) 自己指向自己
.real_parent = &tsk
.parent = &tsk
.children = LIST_HEAD_INIT(tsk.children)
.sibling = LIST_HEAD_INIT(tsk.sibling)
.group_leader = &tsk
.fs = &init_fs
.files = &init_files
.signal = &init_signals
.sighand = &init_sighand
union thread_union init_thread_union__init_task_data = { INIT_THREAD_INFO(init_task) }; 在《linux内核之启动过程详解》一文中讲过在进入start_kernel之前的汇编代码,将sp堆栈指向这个静态内核堆栈。
#define INIT_THREAD_INFO(tsk) \
{ \
.task = &tsk, //指向进程描述符 \
.exec_domain =&default_exec_domain, \
.flags = 0, \
.preempt_count = INIT_PREEMPT_COUNT, \
.addr_limit = KERNEL_DS, \
.cpu_domain = domain_val(DOMAIN_USER, DOMAIN_MANAGER) | \
domain_val(DOMAIN_KERNEL,DOMAIN_MANAGER) | \
domain_val(DOMAIN_IO,DOMAIN_CLIENT), \
.restart_block = { \
.fn = do_no_restart_syscall, \
}, \
}
主内核页全局目录存放在swapper_pg_dir中,该变量arch/arm/kernel/head.S中开头出定义,细节见《linux内核之启动过程详解》一文。
Start_kernel完成内核相关的所有初始化之后,最后执行rest_init函数,该函数会创建两个线程:
kernel_thread(kernel_init, NULL, CLONE_FS |CLONE_SIGHAND);
pid = kernel_thread(kthreadd, NULL,CLONE_FS | CLONE_FILES);
同进程0共享所有的内核数据结构。
kernel_init线程调用run_init_process—>do_execve系统调用装入可执行程序/sbin/init(ps命令看到的1号进程就是这个init),完成内核态到用户态的切换,拥有自己的地址空间和数据结构,执行/etc下面的各种脚本,实现程序启动。
Kthreadd线程不停查看内核线程创建队列,看是否有内核线程需要创建,这也就有了上面kthread_create内核线程的父进程都指向它。
在多处理器系统中,每个CPU都有一个进程0。开机时先启动CPU0,同时禁用其他CPU,在CPU0上初始化好后,再激活其他的CPU。
3、进程切换
(1)arm简介
ARM微处理器共有37个32位寄存器,其中31个为通用寄存器,6个为状态寄存器。但是这些寄存器不能被同时访问,具体哪些寄存器是可以访问的,取决ARM处理器的工作状态及具体的运行模式。但在任何时候,通用寄存器R14~R0、程序计数器PC、一个状态寄存器都是可访问的。
通用寄存器:不分组寄存器(R0-R7) 、分组寄存器(R8-R14)(r13-sp,r14-lr) 、程序计数器R15(PC)。如下图所示:
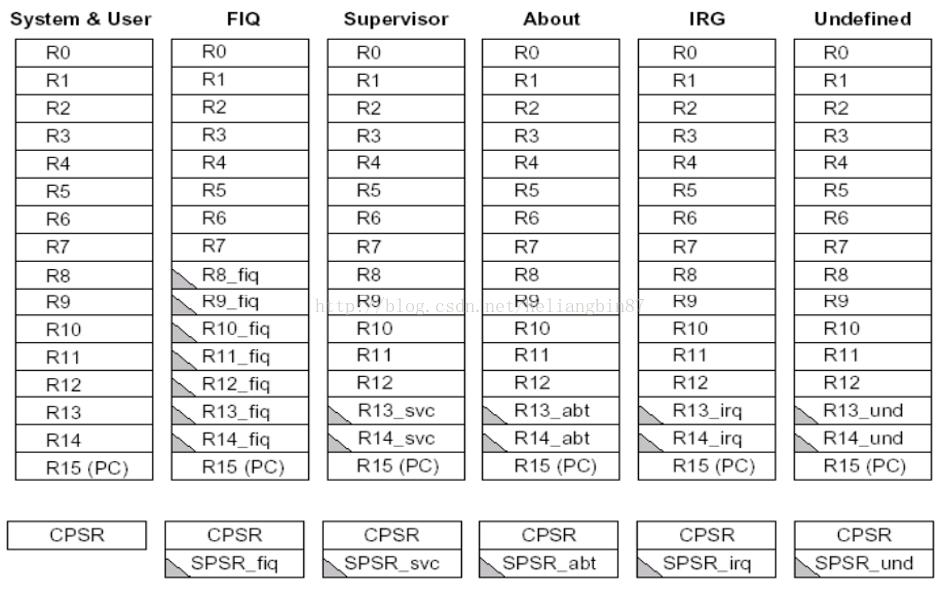
Arm在linux下一般运行在两个模式:usr(用户态)和svc(内核态)。从上图可知usr和svc有各自独立的r13(sp)、r14(lr)、SPSR寄存器,这样用户空间和内核空间可以保存各自的堆栈,方便进程切换。
进程切换只在内核态进行,可以通过系统调用、异常、中断方式进入内核态。
(2)进程间切换
进程切换:为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。尽管每个进程可以拥有属于自己的地址空间,但所有进程必须共享CPU寄存器。因此,在恢复一个进程的执行前,必须确保每个寄存器装入挂起进程时的值,这组寄存器数据称为硬件上下文。
从本质上说,每个进程切换由两部组成:
A.切换页全局目录以安装一个新的地址空间(在进程地址空间一节会有讲述)
B.切换内核态堆栈和硬件上下文,因为硬件上下文提供了内核执行新进程所需的所有信息,包含CPU寄存器。
进程切换的核心函数:schedule()—>__schedule()—>context_switch()—>switch_to()(由各自平台实现)—>__switch_to()(在arm上这是一个汇编代码)源码如下。
__switch_to(prev, task_thread_info(prev),task_thread_info(next))
r0=prev //任务
r1= task_thread_info(prev) //内核栈
r2= task_thread_info(next) //内核栈
#define task_thread_info(task) ((struct thread_info *)(task)->stack)
/*
*Register switch for ARMv3 and ARMv4 processors
* r0= previous task_struct, r1 = previous thread_info, r2 = next thread_info
*previous and next are guaranteed not to be the same.
*/
ENTRY(__switch_to)
UNWIND(.fnstart )
UNWIND(.cantunwind )
add ip, r1, #TI_CPU_SAVE //IP指向上一个线程thread_info的cpu_context成员地址
ldr r3, [r2, #TI_TP_VALUE] //r3=下一个线程tp_value的值(即TLS寄存器)
//保存现场,存储r4 - sl,fp, sp, lr到上一个线程的cpu_context里。
ARM( stmia ip!, {r4 - sl, fp, sp, lr} ) @ Store most regs on stack
THUMB( stmia ip!, {r4 - sl, fp} ) @ Store most regs on stack
THUMB( str sp, [ip], #4 )
THUMB( str lr, [ip], #4 )
#ifdef CONFIG_CPU_USE_DOMAINS //未定义
ldr r6, [r2, #TI_CPU_DOMAIN]
#endif
set_tls r3, r4, r5 //设置TLS寄存器,TLS线程局部存储
#if defined(CONFIG_CC_STACKPROTECTOR)&& !defined(CONFIG_SMP) //未定义
ldr r7, [r2, #TI_TASK]
ldr r8, =__stack_chk_guard
ldr r7, [r7, #TSK_STACK_CANARY]
#endif
#ifdef CONFIG_CPU_USE_DOMAINS //未定义
mcr p15, 0, r6, c3, c0, 0 @Set domain register
#endif
mov r5, r0 //临时保存上一个线程的task_struct
add r4, r2, #TI_CPU_SAVE //r4指向下一个线程的cpu_context
// thread_notify_head通知链
ldr r0,=thread_notify_head
mov r1, #THREAD_NOTIFY_SWITCH
bl atomic_notifier_call_chain
#if defined(CONFIG_CC_STACKPROTECTOR)&& !defined(CONFIG_SMP) //未定义
str r7, [r8]
#endif
THUMB( mov ip, r4 ) //ip=r4:指向下一个线程的cpu_context
mov r0, r5 //恢复r0重新指向上一个线程的task_struct(未使用)
//恢复现场,将下一个线程寄存器加载到CPU,pc=cpu_context->pc,刚好对应上面保存现场时的lr(即下一个线程要执行的地方)
ARM( ldmia r4, {r4 - sl, fp, sp,pc} ) @ Load all regs saved previously
THUMB( ldmia ip!, {r4 - sl, fp} ) @ Load all regs saved previously
THUMB( ldr sp, [ip], #4 )
THUMB( ldr pc, [ip] )
UNWIND(.fnend )
ENDPROC(__switch_to)
(3)同一进程用户态和内核态切换
这里主要介绍系统调用引发的用户态和内核态切换,其他方式类似。
每个进程会有两个栈,一个用户栈,存在于用户空间,一个内核栈,存在于内核空间。当进程在用户空间运行时,CPU堆栈指针寄存器里面的内容是用户堆栈地址;当进程在内核空间时,CPU堆栈指针寄存器里的内容是内核栈空间地址,使用内核栈。
当进程通过系统调用陷入内核态时,进程使用的堆栈也要从用户栈转到内核栈。进程陷入内核态后,先把用户态堆栈的地址保存在内核栈之中,然后设置堆栈指针寄存器的内容为内核栈的地址,这样就完成了用户栈向内核栈的转换;当进程从内核态恢复到用户态之行时,在内核态之行的最后将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了内核栈和用户栈的互转。
在进程从用户态转到内核态的时候,进程的内核栈总是空的。这是因为,当进程在用户态运行时,使用的是用户栈,当进程陷入到内核态时,内核栈保存进程在内核态运行的相关信息,但是一旦进程返回到用户态后,内核栈中保存的信息无效,会全部恢复,因此每次进程从用户态陷入内核的时候得到的内核栈都是空的。所以在进程陷入内核的时候,直接把内核栈的栈顶地址给堆栈指针寄存器就可以。
进程调用系统调用通过swi指令产生中断发起内核服务请求,从而陷入内核。内核的相应入口点为ENTRY(vector_swi),执行这个函数前,硬件已经完成了如下事情:
A.将CPSR寄存器保存到SPSR_svc寄存器中,将返回地址(用户空间执行swi指令的下一条指令)保存在lr_svc。
B.设定CPSR寄存器的值。具体包括:CPSR.M = '10011'(svc mode),CPSR.I = '1'(disable IRQ),CPSR.IT = '00000000'(TODO),CPSR.J = '0'()等
C.PC设定为swi异常向量的地址
源码(去掉无关宏)如下:
.align 5
ENTRY(vector_swi)
sub sp, sp, #S_FRAME_SIZE //前面已经提到过用户态进入内核态,内核堆栈是空的,sp指向内核堆栈栈顶(这里sp_svc,不是sp_usr所以不会冲突,thread_info在远离栈顶的低地址)
stmia sp, {r0 - r12} @ Calling r0 - r12 //r0-r12用户和内核共用,将用户空间的寄存器r0-r12压栈;而上一节内核线程切换CPU信息则保存thread_info—>cpu_context
ARM( add r8, sp, #S_PC )
ARM( stmdb r8, {sp, lr}^ ) @ Calling sp, lr
THUMB( mov r8, sp )
THUMB( store_user_sp_lr r8, r10, S_SP ) @calling sp, lr
mrs r8, spsr @ calledfrom non-FIQ mode, so ok.
str lr, [sp, #S_PC] @ Savecalling PC //保存用户空间的lr即返回的pc地址到内核栈
str r8, [sp, #S_PSR] @ Save CPSR //保存保存cpsr到内核堆栈
str r0, [sp, #S_OLD_R0] @ SaveOLD_R0
zero_fp
#ifdef CONFIG_ALIGNMENT_TRAP
ldr ip, __cr_alignment
ldr ip, [ip]
mcr p15, 0, ip, c1, c0 @update control register
#endif
enable_irq
ct_user_exit
get_thread_info tsk //内核栈按照8192对齐,thread_info在内核栈的首地址,所以通过sp的低13位设置为0编程首地址即thread_info存放的地方。
//获取系统调用号
#if defined(CONFIG_OABI_COMPAT)
/*
* If we have CONFIG_OABI_COMPAT then we need to look at the swi
* value to determine if it is an EABI or anold ABI call.
*/
#ifdef CONFIG_ARM_THUMB
tst r8, #PSR_T_BIT
movne r10, #0 @ no thumb OABI emulation
USER( ldreq r10, [lr, #-4] ) @ get SWI instruction
#endif
#endif
adrtbl, sys_call_table @ load syscalltable pointer 获取syscall表首地址
#if defined(CONFIG_OABI_COMPAT)
/*
* If the swi argument is zero, this is an EABI call and we do nothing.
*
* If this is an old ABI call, get the syscall number into scno and
* get the old ABI syscall table address.
*/
bics r10, r10, #0xff000000
eorne scno, r10,#__NR_OABI_SYSCALL_BASE
ldrne tbl, =sys_oabi_call_table
#endif
local_restart:
ldr r10, [tsk, #TI_FLAGS] @check for syscall tracing
stmdb sp!, {r4, r5} @ push fifth and sixth args 将swi后面的参数入栈
tst r10, #_TIF_SYSCALL_WORK @are we tracing syscalls?
bne __sys_trace
cmp scno, #NR_syscalls @check upper syscall limit
adr lr, BSYM(ret_fast_syscall) @ return address
ldrcc pc, [tbl, scno, lsl#2] @ call sys_* routine //执行相应的系统调用
add r1, sp, #S_OFF
2: mov why, #0 @ nolonger a real syscall
cmp scno, #(__ARM_NR_BASE - __NR_SYSCALL_BASE)
eor r0, scno, #__NR_SYSCALL_BASE @ put OS number back
bcs arm_syscall
b sys_ni_syscall @ not private func
#if defined(CONFIG_OABI_COMPAT) ||!defined(CONFIG_AEABI)
/*
* We failed to handle a fault trying to access the page
* containing the swi instruction, but we're not really in a
* position to return -EFAULT. Instead, return back to the
* instruction and re-enter the user fault handling path trying
* to page it in. This will likely result in sending SEGV to the
* current task.
*/
9001:
sub lr, lr, #4
str lr, [sp, #S_PC]
b ret_fast_syscall //系统调用结束返回处理
#endif
ENDPROC(vector_swi)
.align 5
/*
*This is the fast syscall return path. Wedo as little as
*possible here, and this includes saving r0 back into the SVC
*stack.
*/
ret_fast_syscall:
UNWIND(.fnstart )
UNWIND(.cantunwind )
disable_irq @ disableinterrupts
ldr r1, [tsk, #TI_FLAGS]
tst r1, #_TIF_WORK_MASK
bne fast_work_pending
asm_trace_hardirqs_on
/* perform architecture specific actions before user return */
arch_ret_to_user r1, lr //未实现
ct_user_enter
restore_user_regs fast = 1, offset = S_OFF //恢复用户空间的CPU信息
UNWIND(.fnend )
//恢复用户空间CPU寄存器信息宏定义
.macro restore_user_regs, fast = 0, offset = 0
ldr r1, [sp, #\offset + S_PSR] @get calling cpsr //获取用户的CPSR
ldr lr, [sp, #\offset + S_PC]! @get pc //获取用户空间PC
msr spsr_cxsf, r1 @ savein spsr_svc
clrex @ clearthe exclusive monitor
.if \fast
ldmdb sp, {r1 - lr}^ @ get calling r1 – lr //将之前压栈的用户寄存器出栈到寄存器
.else
ldmdb sp, {r0 - lr}^ @ get calling r0 - lr
.endif
mov r0, r0 @ ARMv5Tand earlier require a nop
@ after ldm {}^
add sp, sp, #S_FRAME_SIZE - S_PC //内核堆栈指针sp_svc重新指向栈顶
movs pc, lr @ return & move spsr_svc intocpsr //切换到usr返回到用户空间执行
.endm
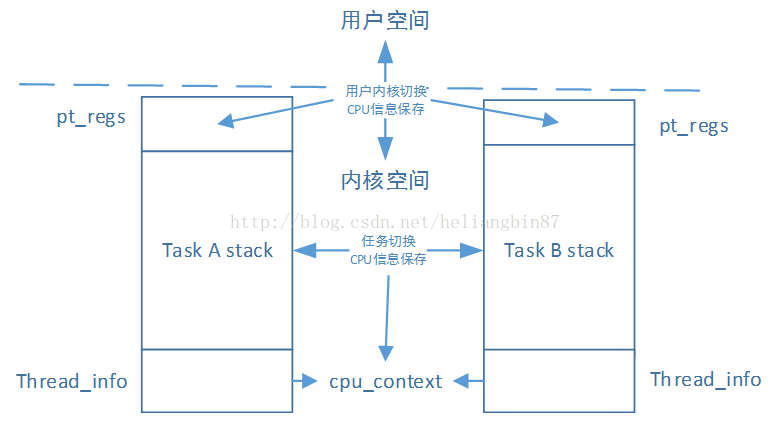
进程切换只能发生在内核,切换时CPU的信息存放在thread_info结构题的cpu_context中;进程从用户态到内核态,进程的用户态CPU信息则存放在内核态堆栈空间pt_regs地方。
4、进程销毁
进程终止的一般方式是调用exit()系统调用,即可能显式地调用,也可能隐式的从某个主函数返回;当进程接收到它既不能处理也不能忽略的信号或异常时,还可能被动终结。不管如何,在内核都是通过do_exit完成工作。
调用了do_exit()之后,尽管线程已经僵死不能再运行,但是系统还保留了它的进程描述符,这样可以让系统有办法在子进程终结后仍能获得它的信息。所以,进程终结时所需的清理工作和进程描述符的删除被分开执行。在父进程获得已终结的子进程的信息后,或者通知内核它并不关注那些信息后,子进程的task_struct结构才被释放。
如果父进程在子进程之前退出,必须有机制来保证子进程能找到一个新的父进程,否则这些进程退出时永远处于僵死状态,白白耗费内存。对于这个问题,解决方法是给子进程在当前线程组内找一个线程作为父亲,如果不行,就让init做它们的父进程。

新一代开源开发者平台 GitCode,通过集成代码托管服务、代码仓库以及可信赖的开源组件库,让开发者可以在云端进行代码托管和开发。旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)