
深入浅出linux内核源代码之双向链表list_head(上)
原创文章,转载请注明出处,谢谢!
作者:清林,博客名:飞空静渡
前言: 在linux 源代码中有个头文件为list.h 。很多linux 下的源代码都会使用这个头文件,它里面定义了一个结构, 以及定义了和其相关的一组函数,这个结构是这样的:
struct list_head{
struct list_head *next, *prev;
};
那么这个头文件又是有什么样的作用呢,这篇文章就是用来解释它的作用,虽然这是linux 下的源代码,但对于学习C 语言的人来说,这是算法和平台没有什么关系。
一、双向链表
学习计算机的人都会开一门课程《数据结构》,里面都会有讲解双向链表的内容。
什么是双向链表,它看起来是这样的:
struct dlist
{
int no;
void* data;
struct dlist *prev, *next;
};
它的图形结构图如下:

如果是双向循环链表,那么就加上虚线所示。
现在有几个结构体,它们是:
表示人的:
struct person
{
int age;
int weight;
};
表示动物的:
struct animal
{
int age;
int weight;
};
如果有一组filename 变量和filedata 变量,把它们存起来,我们会怎么做,当然就用数组了,但我们想使用双向链表,让它们链接起来,那该怎么做,唯一可以做的就是给每个结构加如两个成员,如下:
表示人的:
struct person
{
int age;
int weight;
struct person *next, *prev;
};
表示动物的:
struct animal
{
int age;
int weight;
struct animal *next, *prev;
};
现在有一个人的一个链表的链头指针person_head (循环双向链表)和动物的链表的链头指针ainimal_head ,我们要获得特定年龄和特定体重的人或动物(假设不考虑重叠),那么代码看起来可能是这样:
struct person * get_percent(int age, int weight)
{
…....
struct person *p;
for(p = person_head->next; p != person_head; p=p->next)
{
if(p->age == age && p->weight == weight)
return p;
}
…...
}
那同理, 要获得一个特定年龄和重量的动物的函数get_animal(int age, int weight) 的代码也是和上面的类似。
如果我们定义这样的两个函数,它们基本一样,会不会觉得有点冗余,如果是c++ 就好了,但这里只说c 。
如果我们仔细观察一下这两个结构,我们会发现它们出了类型名字不一样外,其它的都一样。那么我们考虑用一个宏来实现,这个宏看起来可能是这样的。
#define get_one(list, age, weight, type, one) /
do /
{/
type *p;/
for(p = ((type*)list)->next; p != (type*)list; p=p->next)/
if (p->age == age && p->weight == weight)/
{/
one = p;/
break;/
}/
}while(0)
那么我们获得一个年龄50 ,体重60 的人可以这样:
struct person *one = NULL;
get_one(person_head, 50, 60, struct person, one);
if(one)
{
// get it
…...
}
同样获得一个年龄20 ,体重130 的动物可以这样:
struct animal *one = NULL;
get_one(animal_head, 50, 60, struct animal, one);
if(one)
{
// get it
…...
}
我们再回过头来看这两个结构,它们的指向前和指向后的指针其实都差不多,那把它们综合起来吧,所以看起来如下面:
struct list_head{
struct list_head *next, *prev;
};
表示人的:
struct person
{
int age;
int weight;
struct list_head list;
};
表示动物的:
struct animal
{
int age;
int weight;
struct list_head list;
};
现在这个两个结构看起来就更差不多一样了。现在为了方便,我们去掉那些暂时不用的数据,如下:
struct person
{
struct list_head list;
};
表示动物的:
struct animal
{
struct list_head list;
};
可能又会有些人会问了,struct list_head 都不是struct persion 和struct animal 类型,怎么可以做链表的指针呢?其实,无论是什么样的指针,它的大小都是一样的,32 位的系统中,指针的大小都是32 位(即4 个字节),只是不同类型的指针在解释的时候不一样而已,那么这个struct list_head 又是怎么去做这些结构的链表指针呢,那么就请看下一节吧:)。
二、struct list_head 结构的操作
首先,让我们来看下和struct list_head 有关的两个宏,它们定义在list.h 文件中。
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) struct list_head name = LIST_HEAD_INIT(name)
#define INIT_LIST_HEAD(ptr) do { /
(ptr)->next = (ptr); (ptr)->prev = (ptr); /
} while (0)
这两个宏是用了定义双向链表的头节点的,定义一个双向链表的头节点,我们可以这样:
struct list_head head;
LIST_HEAD_INIT(head);
又或者直接这样:
LIST_HEAD(head);
这样,我们就定义并初始化了一个头节点。
#define LIST_HEAD_INIT(name) { &(name), &(name) }
就是用head 的地址初始化其两个成员next 和prev ,使其都指向自己。
我们再看下和其相关的几个函数,这些函数都作为内联函数也都定义list.h 中,这里要说明一下linux 源码的一个风格,在下面的这些函数中以下划线开始的函数是给内部调用的函数,而以符开始的函数就是对外使用的函数,这些函数一般都是调用以下划线开始的函数,或是说是对下划线开始的函数的封装。
2.1 增加节点的函数
static inline void __list_add();
static inline void list_add();
static inline void list_add_tail();
其实看源代码是最好的讲解了,这里我再简单的讲一下。
/**
* __list_add - Insert a new entry between two known consecutive entries.
* @new:
* @prev:
* @next:
*
* This is only for internal list manipulation where we know the prev/next
* entries already!
*/
static __inline__ void __list_add(struct list_head * new,
struct list_head * prev, struct list_head * next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
这个函数在prev 和next 间插入一个节点new 。
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static __inline__ void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
这个函数在head 节点后面插入new 节点。
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static __inline__ void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
这个函数和上面的那个函数相反,它在head 节点的前面插入new 节点。
2.2 从链表中删除节点的函数
/**
* __list_del -
* @prev:
* @next:
*
* Delete a list entry by making the prev/next entries point to each other.
*
* This is only for internal list manipulation where we know the prev/next
* entries already!
*/
static __inline__ void __list_del(struct list_head * prev,
struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
/**
* list_del - deletes entry from list.
* @entry: the element to delete from the list.
*
* Note: list_empty on entry does not return true after this, the entry is in
* an undefined state.
*/
static __inline__ void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
}
/**
* list_del_init - deletes entry from list and reinitialize it.
* @entry: the element to delete from the list.
*/
static __inline__ void list_del_init(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
INIT_LIST_HEAD(entry);
}
这里简单说一下,list_del(struct list_head *entry) 是从链表中删除entry 节点。list_del_init(struct list_head *entry) 不但从链表中删除节点,还把这个节点的向前向后指针都指向自己,即初始化。
那么,我们怎么判断这个链表是不是空的呢!上面我说了,这里的双向链表都是有一个头节点,而我们上面看到,定义一个头节点时我们就初始化了,即它的prev 和next 指针都指向自己。所以这个函数是这样的。
/**
* list_empty - tests whether a list is empty
* @head: the list to test.
*/
static __inline__ int list_empty(struct list_head *head)
{
return head->next == head;
}
讲了这几个函数后,这又到了关键了,下面讲解的一个宏的定义就是对第一节中,我们所要说的为什么在一个结构中加入struct list_head 变量就把这个结构变成了双向链表呢,这其中的关键就是怎么通过这个struct list_head 变量来获取整个结构的变量,下面这个宏就为你解开答案:
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*/
#define list_entry(ptr, type, member) /
((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member)))
乍一看下,不知道这个宏在说什么,没关系,我举个例子来为你一一解答 :)
首先,我们还是用上面的结构:
struct person
{
int age;
int weight;
struct list_head list;
};
我们一看到这样的结构就应该知道它定义了一个双向链表,下面来看下。
我们有一个指针:
struct list_head *pos;
现在有这个指针,我们怎么去获得这个指针所在的结构的变量(即是struct person 变量,其实是struct person 指针)呢?看下面这样使用:
struct person *one = list_entry(pos, struct person, list);
不明白是吧,展开一下 list_entry 结构如下:
((struct person *)((char *)(pos) - (unsigned long)(&((struct person *)0)->list)))
我慢慢的分解,首先分成两部分(char *)(pos) 减去(unsigned long)(&((struct person *)0)->list) 然后转换成(struct person *) 类型的指针。
(char *)(pos) :是将pos 由struct list_head* 转换成char* ,这个好理解。
(unsigned long)(&((struct person *)0)->list) :先看最里面的(struct person *)0) ,它是把0 地址转换成struct person 指针,然后(struct person *)0)->list 就是指向list 变量,之后是&((struct person *)0)->list 是取这个变量的地址,最后是(unsigned long)(&((struct person *)0)->list) 把这个变量的地址值变成一个整形数!
这么复杂啊,其实说白了,这个(unsigned long)(&((struct person *)0)->list) 的意思就是取list 变量在struct person 结构中的偏移量。
用个图形来说(unsigned long)(&((struct person *)0)->list ,如下:
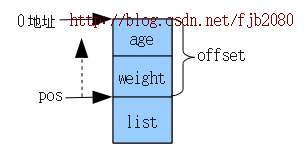
而(unsigned long)(&((struct person *)0)->list 就是获取这个offset 的值。
((char *)(pos) - (unsigned long)(&((struct person *)0)->list))
就是将pos 指针往前移动offset 位置,即是本来pos 是struct list_head 类型,它即是list 。即是把pos 指针往struct person 结构的头地址位置移动过去,如上图的pos 和虚箭头。
当pos 移到struct person 结构头后就转换成(struct person *) 指针,这样就可以得到struct person * 变量了。
所以我们再回到前面的句子
struct person *one = list_entry(pos, struct person, list);
就是由pos 得到pos 所在的结构的指针,动物就可以这样:
struct animal *one = list_entry(pos, struct animal, list);
下面我们再来看下和struct list_head 相关的最后一个宏。
2.3 list_head 的遍历的宏
/**
* list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop counter.
* @head: the head for your list.
*/
#define list_for_each(pos, head) /
for (pos = (head)->next; pos != (head); pos = pos->next)
/**
* list_for_each_safe - iterate over a list safe against removal of list entry
* @pos: the &struct list_head to use as a loop counter.
* @n: another &struct list_head to use as temporary storage
* @head: the head for your list.
*/
#define list_for_each_safe(pos, n, head) /
for (pos = (head)->next, n = pos->next; pos != (head); /
pos = n, n = pos->next)
list_for_each(pos, head) 是遍历整个head 链表中的每个元素,每个元素都用pos 指向。
list_for_each_safe(pos, n, head) 是用于删除链表head 中的元素,不是上面有删除链表元素的函数了吗,为什么这里又要定义一个这样的宏呢。看下这个宏后面有个safe 字,就是说用这个宏来删除是安全的,直接用前面的那些删除函数是不安全的。这个怎么说呢,我们看下下面这个图,有三个元素a ,b ,c 。

现在,我们要删除b 元素,下面是删除的算法(先只用删除函数):
struct list_head *pos;
list_for_each(pos, myhead)
{
if (pos == b)
{
list_del_init(pos);
//break;
}
。。。
}
上面的算法是不安全的,因为当我们删除b 后,如下图这样:

上删除pos 即b 后,list_for_each 要移到下一个元素,还需要用pos 来取得下一个元素,但pos 的指向已经改变,如果不直接退出而是在继续操作的话,就会出错了。
而 list_for_each_safe 就不一样了,如果上面的代码改成这样:
struct list_head *pos, *n;
list_for_each_safe(pos, n, myhead)
{
if (pos == b)
{
list_del_init(pos);
//break;
}
。。。
}
这里我们使用了n 作为一个临时的指针,当pos 被删除后,还可以用n 来获得下一个元素的位置。
说了那么多关于list_head 的东西,下面应该总结一下,总结一下第一节想要解决的问题。请看下章分析。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)