字符指针与字符数组真正的区别
字符指针与字符数组真正的区别
问题缘起
先看一个示例
示例1
上面的例子会给出这样的输出
p: hello
q: hello
这样看,char *p 和 char q[] 好像没什么区别, 那么我们再看一个例子
示例2
如果你在Linux下,运行时可能得到这样的结果
Segmentation fault (core dumped)
这时候你看到了区别,出现了段错误, 你一定想明白,到底发生了什么, 经过几个小实验,你可能会发现使用 char *p 定义时,p指向的数据是无法改变的。 然后你Google, 别人可能会告诉你
- char 指针指向的数据不能修改
- char 指针指向的数据没有分配
- ...
你听了还是一头雾水,不能修改是什么意思,没有分配?没有分配为什么能输出?
作为一个好奇心很重的人,你是绝对不能容忍这些问题的困扰的,且听我慢慢道来
深入理解
首先,你的程序代码和程序数据都在内存里放着,也就是说 p 指向的 hello 和 q 指向的 hello, 都是内存中的数据。从两个示例的比较中,你发现,同样是内存中的数据,都可以读,但是有的可以写, 有的不能写。从这可以看出,问题的关键在于,内存是如何组织的。
写好的程序代码放在硬盘上。程序代码的运行需要CPU一条指令一条指令地执行。
在硬盘上读东西是慢的,CPU是快的,所以有了内存。
因此程序代码如果要运行,需要先载入内存。这时候,问题又出现了,系统中同时有许多程序要运行, 你想要这块内存,我也想要这块内存,那这块内存给谁呢? 何况,写程序的时候,我是不知道哪块内存 被占用,哪块没有被占用的。总不能每次我想放数据,都检查一下吧。那程序员的负担也太大了。
一件事如果大家都需要,肯定会出现专门做这件事的人。
于是,操作系统接管了内存。程序A说,我要12号内存单元。程序B说,我要12号内存单元。 操作系统表示很为难。不能都给,要不就冲突了,也不能不给,内存还有好大地方呢。
操作系统是聪明的,聪明人是会抽象的。
所谓抽象,就是看不到具体的东西了,只能看到上层的东西。当程序A和程序B都请求12号内存单元时, 操作系统把3号内存单元给了A,5号内存单元给了B。但是为了让程序中对内存的访问保持一致性, 并不让程序知道给他们的不是12号内存单元,否则程序中凡是和12号内存单元相关的,都要作修改, 又变成了程序自己维护内存。操作系统为每个程序维护一个映射表。在映射表中, 对于程序A来说,12号内存单元对应3号内存单元,对于程序B来说12号内存单元对应5号内存单元。 这时候程序看到的12号内存单元和操作系统实际给出的3,5号内存单元,就变成了两种不同的事物。 12号内存单元只是程序看到的,3,5号是真实的内存单元。我们把前者称为虚拟内存单元,后者指为物理 内存单元。
有了虚拟内存的概念后,程序就无法无天了,全部的内存我都可以用,想访问哪块访问哪块,至于 实际上真正访问的是内存哪个位置,我可不关心,那是操作系统的事,我只要把一个虚拟内存号告诉 操作系统就可以了。所以,从程序看来,他拥有整个内存空间。
严格来说,程序这个词是不准确的, 程序一般就是指的代码本身。但是代码一旦运行起来, 和这段代码相关的东西就太多了,比如指令,数据,映射表,用到的内存。另一方面, 系统中有多个程序在执行,有时候程序A执行,有时候程序B执行,操作系统从A切换到B时, 肯定要记下来A执行到哪里了,这也和程序相关。所以这时候,我们又抽象出一个概念,叫进程。 这时候,程序就表示硬盘上那块代码,进程表示正在运行的程序,进程不仅包含代码, 还包含一些运行时相关的东西。
现在,当你启动一个程序时,操作系统会先创建一个进程,为这个进程建立一个私有的虚拟的内存空间, 把程序代码加载进来。进程代表一个运行中的程序,程序在运行时要使用内存,并且使用内存的方式多种多样, 程序有有些数据放在内存中是不变的,有些是一开始就分配好的,还有一些会根据需要分配。所以, 我们需要对进程的虚拟内存空间进行良好的组织,以便操作系统和程序配合,高效地完成任务。
下图是一个Linux进程的虚拟内存空间
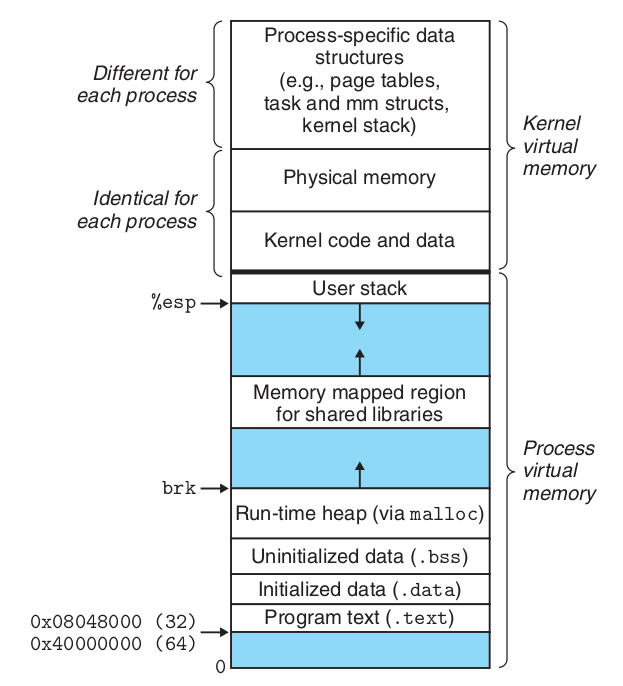
所有的Linux进程的虚拟内存空间都是以这种方式组织的,只不过不同进程因为映射表不同,所以 同一虚拟地址对应不同的物理地址。如果进程需要共享一块内存区,只需要在映射表中把同一虚拟内存 地址映射到相同物理地址就可以了,比如上图中的Kernel virutal memory区域,这个区域是操作系统 内核的代码,所有进程都需要共享,所以操作系统就可以把所有进程的这一区域映射到相同物理地址处。
上图的下半部分是Process virtual memory,代码进程使用的虚拟内存空间,可以看出他们被分成了 几个块,这些块代表了程序使用内存的不同方式。我们先来看一段代码,并结合上图说明一下程序使用 内存的不同方式。
示例3
我们先用gcc将这段代码编程成汇编语言
gcc -S tchar.c -o tchar.s
示例3汇编版本(含注释, 只含关键代码)
从上述汇编代码可以看出p,q,r三种使用内存的方式。从初始化上看, p指向的"hello",初始化时,直接指向了一个固定的位置,这意味着代码执行的时候, 这个位置已经有数据了。q指向的"world",初始化是由代码完成的,你把"world"经ASCII码转化成数字形式, 对比一下就会发现,那两个数字,1819438967,100,对应的就是"world"。而r的初始化,是调用malloc得到的。
从这段汇编代码。我们从直觉上会感觉到这三种使用内存方式的不同,接下来,我们再来看一下Linux运行时存储器映像。
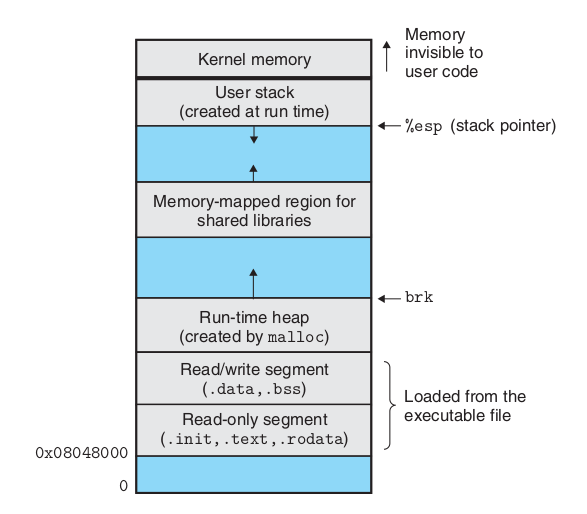
.text 段放着已经编译的程序机器代码。
.rodata 段放着只读数据,printf函数参数中的字符串,p指向的"hello", 都在这存着。正因为这个段是只读的,所以不能修改,代码
执行时就会出现段错误。
.data 段放着已经初始化的全局变量,.bss 段变着没有初始化的全局变量。
再往上是 Run-time heap, 我们用malloc分配的内存空间都在这一段。
接着是User Stack,程序中的局部变量都在这一段,我们q指向的"world"就存储在这里。 从图中也可以看到,%esp指向栈顶,再回头看一下汇编代码,你可能就明白之前相对于(%esp)地址所做的操作意味着什么。
这里特别要区分 地址与数据 。
p,q,r是局部变量,它们的值都是地址,这个地址作为局部变量的值,在User Stack里存储。
p表示的地址指向数据"hello",这是不可变量,在.rodata段中存储。q表示的地址指向的数据"world",作为局部变量的数据,在User Stack段存储。 r表示的地址指向的数据,在Run-time heap中存储。
为了验证我们的想法,我们做一个实验,把p,q,r三者地址打印出来, 再把三者指向的数据的地址打印出来。 然后查看内存分配。
示例4
为了便于观察,我们引入scanf,同时放在后台运行,这样只要我们不输入数据, 进程就不会终止,我们就可以观察它。运行它,
$ ./tcharp &
[2] 3461
addr of p:0xbfaa91d8
addr of q:0xbfaa91e6
addr of r:0xbfaa91dc
addr of p's data:0x8048670
addr of q's data:0xbfaa91e6
addr of r's data:0x87ad008
从这里,我们可以看出:p,q,r本身的值,以及q指向的数据,存储的位置离的很近,我们猜测, 所以0xbfXXXXXX这一块应该是User Stack区域,0x8048XXX这一块是.rodata区域, 0x87XXXXX这一块是Run-time heap区域。
接下来,我们使用 readelf 命令,得到各个区域的实际位置,进一步明确我们的猜想。
$ readelf -a tcharp > tcharp_elf.txt
从tcharp_elf.txt中截取关键数据, 得到
[11] .init PROGBITS 08048318 000318 00002e 00 AX 0 0 4
[12] .plt PROGBITS 08048350 000350 000060 04 AX 0 0 16
[13] .text PROGBITS 080483b0 0003b0 00023c 00 AX 0 0 16
[14] .fini PROGBITS 080485ec 0005ec 00001a 00 AX 0 0 4
[15] .rodata PROGBITS 08048608 000608 000077 00 A 0 0 4
[16] .eh_frame_hdr PROGBITS 08048680 000680 000034 00 A 0 0 4
[17] .eh_frame PROGBITS 080486b4 0006b4 0000c4 00 A 0 0 4
[18] .ctors PROGBITS 08049f14 000f14 000008 00 WA 0 0 4
[19] .dtors PROGBITS 08049f1c 000f1c 000008 00 WA 0 0 4
[20] .jcr PROGBITS 08049f24 000f24 000004 00 WA 0 0 4
[21] .dynamic DYNAMIC 08049f28 000f28 0000c8 08 WA 6 0 4
[22] .got PROGBITS 08049ff0 000ff0 000004 04 WA 0 0 4
[23] .got.plt PROGBITS 08049ff4 000ff4 000020 04 WA 0 0 4
[24] .data PROGBITS 0804a014 001014 000008 00 WA 0 0 4
[25] .bss NOBITS 0804a01c 00101c 000008 00 WA 0 0 4
[26] .comment PROGBITS 00000000 00101c 00002a 01 MS 0 0 1
[27] .shstrtab STRTAB 00000000 001046 0000fc 00 0 0 1
[28] .symtab SYMTAB 00000000 0015f4 000430 10 29 45 4
[29] .strtab STRTAB 00000000 001a24 00022c 00 0 0 1
从这里,我们可以验证对 .rodata 段的猜测,p指向的 "hello", 确实是存储在这一段。
然后,我们查看其它段的位置
$ cat /proc/3461/maps
08048000-08049000 r-xp 00000000 08:0a 4981409 /home/zhaoxk/test/tcharp
08049000-0804a000 r--p 00000000 08:0a 4981409 /home/zhaoxk/test/tcharp
0804a000-0804b000 rw-p 00001000 08:0a 4981409 /home/zhaoxk/test/tcharp
087ad000-087ce000 rw-p 00000000 00:00 0 [heap]
b75fc000-b75fd000 rw-p 00000000 00:00 0
b75fd000-b77a1000 r-xp 00000000 08:07 412678 /lib/i386-linux-gnu/libc-2.15.so
b77a1000-b77a3000 r--p 001a4000 08:07 412678 /lib/i386-linux-gnu/libc-2.15.so
b77a3000-b77a4000 rw-p 001a6000 08:07 412678 /lib/i386-linux-gnu/libc-2.15.so
b77a4000-b77a7000 rw-p 00000000 00:00 0
b77c1000-b77c5000 rw-p 00000000 00:00 0
b77c5000-b77c6000 r-xp 00000000 00:00 0 [vdso]
b77c6000-b77e6000 r-xp 00000000 08:07 403838 /lib/i386-linux-gnu/ld-2.15.so
b77e6000-b77e7000 r--p 0001f000 08:07 403838 /lib/i386-linux-gnu/ld-2.15.so
b77e7000-b77e8000 rw-p 00020000 08:07 403838 /lib/i386-linux-gnu/ld-2.15.so
bfa8b000-bfaac000 rw-p 00000000 00:00 0 [stack]
看到stack和heap段的位置了吧,再一次印证了我们的想法。
好了,我们的探索到这里就结束了。
文后的话
从上面的过程可以看出,要想真正理解C语言,你需要了解汇编,需要了解操作系统, 而Linux提供了一系列工具,方便你探索整个系统的运行机制。如果你也想了解它, 请开始使用它。
还是那句话。
既然看起来不错,为什么不试试呢?
文中图片均来自《深入理解计算机系统》一书。
转载请注明出处: http://blog.csdn.net/on_1y/article/details/13030439

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 33
33 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)