
python爬虫之scrapy中user agent浅谈(两种方法)
user agent简述
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
开始(测试不同类型user agent返回值)
手机user agent 测试:Mozilla/5.0 (Linux; U; Android 0.5; en-us) AppleWebKit/522 (KHTML, like Gecko) Safari/419.3
电脑user agent 测试:Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36
1.新建一个scrapy项目(以百度做案例):
scrapy startproject myspider
scrapy genspider bdspider www.baidu.com
2.在settings中开启user agent
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'testspider (+http://www.yourdomain.com)'将手机与电脑user agent 分别修改(手机访问返回的内容比电脑访问的要少,所以随便拿个len()判断一下就可以)
3.spider编写与user agent对比
class MyspiderSpider(scrapy.Spider):
name = 'myspider'
allowed_domains = ['www.baidu.com']
start_urls = ['http://www.baidu.com/']
def parse(self, response):
print(len(response.text))

那么重点来了,对于爬虫来说为了防止触发反爬 一个user agent肯定不行了
那么该如何挂大量的user agent呢
处理方法有很多,这里主要介绍两种:
一、在setings中写一个user agent列表并设置随机方法(让setings替我们选择)
二、在settings中写列表,在middleware.py中创建类,在downloadmiddleware中调用(让中间件完成选择)
一、settings 随机选择user agnet(第一种方法)
settings创建user agent表,
导入random,随机用choise函数调用user agent
import random
# user agent 列表
USER_AGENT_LIST = [
'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23',
'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)',
'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)',
'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)',
'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)',
'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0',
'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)',
'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)'
]
# 随机生成user agent
USER_AGENT = random.choice(USER_AGENT_LIST) 编写spider:
# -*- coding: utf-8 -*-
import scrapy
class MyspiderSpider(scrapy.Spider):
name = 'myspider'
allowed_domains = ['www.baidu.com']
start_urls = ['http://www.baidu.com']
def parse(self, response):
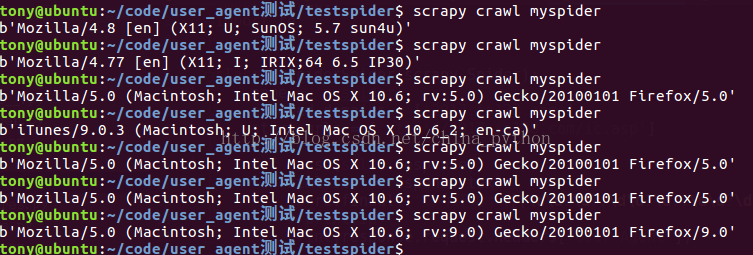
print(response.request.headers['User-Agent'])结果对比
运行结果可以明显发现每次调用的user agent不一样
二、在middleware中调用user agent(第二种方法)
在setting中注释user agent 防止干扰
在middlewares中创建类
import random
class UserAgentMiddleware(object):
def __init__(self):
self.user_agent_list = [
'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23',
'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)',
'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)',
'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)',
'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)',
'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0',
'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)',
'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)'
]
def process_request(self,request,spider):
request.headers['USER_AGENT']=random.choice(self.user_agent_list)启用downloader middleware
DOWNLOADER_MIDDLEWARES = {
'testspider.middlewares.UserAgentMiddleware': 300
}开始测试,对别结果
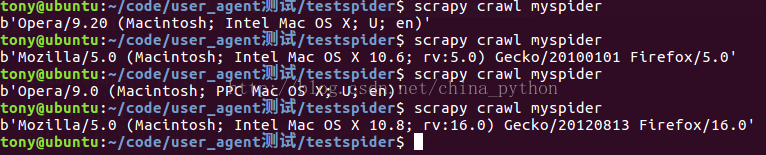
好了 两种方法结束了...........................

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)