easyexcel1.0导出excel(大数据量100万以内分页查询)
easyexcel
快速、简洁、解决大文件内存溢出的java处理Excel工具
项目地址:https://gitcode.com/gh_mirrors/ea/easyexcel
·
准备工作:
开发环境:maven3.5+springmvc4.0+spring4.0+mybatis3
版本:easyexcel1.0
maven依赖:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>1.1.2-beta5</version>
</dependency>以下案例为工作中运用导出大数据量100万以内,分页查询数据
controller层:
@CrossOrigin
@RestController
@RequestMapping("/mip/export")
public class ExportController {
/**
* 用户洞察中心App导出
* @param request
* @param response
*/
@GetMapping("/downLoadApp")
public void downLoadApp(HttpServletRequest request, HttpServletResponse response) {
exportService.downLoadInsightApp(response);
}
}service层:
/**
* 用户洞察中心App导出
* long start = System.currentTimeMillis()//单位毫秒ms
* long start = System.currentTimeMillis() / 1000 //单位秒s
* @param response
*/
public void downLoadInsightApp(HttpServletResponse response) {
String fileName="用户洞察中心App报表"+DateUtils.getCurrentDateStr("yyyyMMddHHmmss");
String sheetName="用户洞察中心App报表";
try {
OutputStream out = getOutputStream(response, fileName, ExcelTypeEnum.XLSX);
//这里指定需要表头,因为model通常包含表信头息
ExcelWriter writer = new ExcelWriter(out, ExcelTypeEnum.XLSX, true);
//写第一个sheet,数据全是List<String> 无模型映射关系
Sheet sheet = new Sheet(1, 0, ExportAppVo.class);
//设置自适应宽度
sheet.setAutoWidth(Boolean.TRUE);
//设置表格样式
sheet.setTableStyle(createTableStyle());
//设置sheetName
sheet.setSheetName(sheetName);
//分页查询数据
int pageNumber = 1;
int pageSize = 5000;
int dataLength = pageSize;
long start = System.currentTimeMillis() / 1000;//单位秒
Map<String, Object> condition=new HashMap<>();
List<ExportAppVo> resultList=null;//置list为空,清空内存
while(dataLength == pageSize){
int startIndex = (pageNumber - 1) * pageSize;
condition.put("pageNo", startIndex);
condition.put("pageSize", pageSize);
resultList=queryInsightApp(condition);
if(resultList==null || resultList.isEmpty()){
//写数据
writer.write(resultList, sheet);
break;
}
dataLength = resultList.size();
pageNumber++;
//写数据
writer.write(resultList, sheet);
}
//关闭writer的输出流
writer.finish();
long end = System.currentTimeMillis() / 1000;
LOGGER.info("导出耗时:" + (end - start) +" 秒");
} catch (Exception e) {
LOGGER.error("导出异常",e);
}
}
/**
* 数据库查询
* @param condition
* @return
*/
private List<ExportAppVo> queryInsightApp(Map<String,Object> condition){
return dalClient.queryForList("export.queryInsightAppByPage",condition,ExportAppVo.class);
}
/**
* 得到流
* @param response 响应
* @param fileName 文件名
* @param excelTypeEnum excel类型
* @return
*/
private OutputStream getOutputStream(HttpServletResponse response, String fileName,
ExcelTypeEnum excelTypeEnum) {
try {
// 设置响应输出的头类型
if (Objects.equals(".xls", excelTypeEnum.getValue())) {
//导出xls格式
response.setContentType("application/vnd.ms-excel;charset=GBK");
} else if (Objects.equals(".xlsx", excelTypeEnum.getValue())) {
//导出xlsx格式
response.setContentType(
"application/vnd.openxmlformats-officedocument.spreadsheetml.sheet;charset=GBK");
}
// 设置下载文件名称(注意中文乱码)
response.addHeader("Content-Disposition",
"attachment;filename=" + new String((fileName).getBytes("GB2312"), "ISO8859-1") + excelTypeEnum
.getValue());
response.addHeader("Pragma", "No-cache");
response.addHeader("Cache-Control", "No-cache");
response.setCharacterEncoding("utf8");
return response.getOutputStream();
} catch (IOException e) {
LOGGER.error("EasyExcelUtil-->getOutputStream exception:", e);
}
return null;
}
/**
* 设置表格样式
* @return
*/
private TableStyle createTableStyle() {
TableStyle tableStyle = new TableStyle();
Font headFont = new Font();
headFont.setBold(true);
headFont.setFontHeightInPoints((short) 20);
headFont.setFontName("楷体");
tableStyle.setTableHeadFont(headFont);
tableStyle.setTableHeadBackGroundColor(IndexedColors.LIGHT_GREEN);
Font contentFont = new Font();
contentFont.setFontHeightInPoints((short) 12);
contentFont.setFontName("黑体");
tableStyle.setTableContentFont(contentFont);
return tableStyle;
}
数据库查询:
<sql id="queryInsightAppByPage">
<![CDATA[
SELECT
brand_code,
collect_time,
insight_percent,
grail_percent,
compare_percent
FROM
t_mip_insight_app
LIMIT :pageNo, :pageSize
]]>
</sql>数据库查询返回Vo实体:
@Getter
@Setter
public class ExportAppVo extends BaseRowModel {
/**
* 品牌编码
*/
@ExcelProperty(value = {"品牌编码"}, index = 0)
private String brandCode;
/**
* 采集时间
*/
@ExcelProperty(value = {"采集时间"}, index = 1)
private String collectTime;
/**
* 占比
*/
@ExcelProperty(value = {"占比/量级"}, index = 2)
private String insightPercent;
/**
* 大盘
*/
@ExcelProperty(value = {"大盘"}, index = 3)
private String grailPercent;
/**
* 对比大盘
*/
@ExcelProperty(value = {"对比大盘"}, index = 4)
private String comparePercent;
}postman测试:
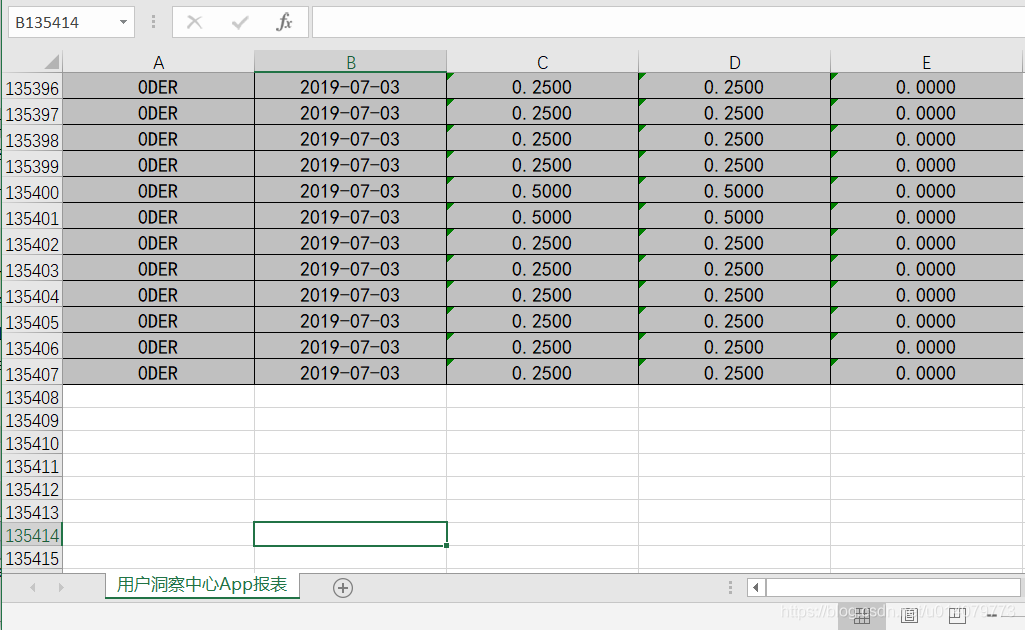
excel导出效果:
备注:
1.根据测试导出这么多数据大概需要4秒,这个sql的性能有关,索引是否全面覆盖,表数据量非常大,是否进行了分区,只要控制sql执行效率高,基本导出不会太慢
2.该表设置的主键非自增,设计的是业务主键,若数据库设计的是自增主键或者用snowflake规则生成的主键,则分页查询sql可以这么写
案例:(分页查询加条件即每次查询返回的最后一次id值)
sql:
<sql id="queryOrderDetailList">
<![CDATA[
SELECT
io.id,
io.activity_id AS activityId,
io.member_id AS memberId
FROM
im_leader_service_order io
LEFT JOIN bm_order o ON o.b2cOrdItemId = io.b2c_ord_item_id
LEFT JOIN bm_settlement bs ON bs.b2cOrderItemId = o.b2cOrdItemId
LEFT JOIN bm_order_stateAmt_detail bsd ON o.b2cOrdItemId = bsd.b2cOrdItemId
WHERE 1=1
<#if primaryId?exists && primaryId!='' >
AND io.id > :primaryId
</#if>
LIMIT :pageSize
]]>
</sql>service层:
public List<ImLeaderServiceOrderVo> queryOrderDetailList(Map<String, Object> paramMap) {
List<ImLeaderServiceOrderVo> dataList = dalClient
.queryForList("imActivityCollect.queryOrderDetailList", paramMap, ImLeaderServiceOrderVo.class);
return dataList;
}控制层:
//封装查询条件
Map<String, Object> paramMap = new HashMap<String, Object>();
int pageSize = 5000;
int dataLength = pageSize;
long start = System.currentTimeMillis() / 1000;//单位秒
List<ImLeaderServiceOrderVo> resultList = null;//查询最后置list为空,清空内存
while (dataLength == pageSize) {
paramMap.put("pageSize", pageSize);
resultList = commanderReportService.queryOrderDetailList(paramMap);
if (CollectionUtils.isEmpty(resultList)) {
//根据自己业务逻辑处理
break;
}
//根据自己业务逻辑处理,比如满足条件做什么事情
//数据长度重新赋值
dataLength = resultList.size();
//获取最后一次查询id
paramMap.put("primaryId", resultList.get(dataLength - 1).getId());
}
快速、简洁、解决大文件内存溢出的java处理Excel工具
最近提交(Master分支:4 个月前 )
c42183df
Bugfix 1 年前
efa7dff6 * 重新加回 `commons-io`
1 年前

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)