
机器学习实战(用Scikit-learn和TensorFlow进行机器学习)(六)
上一节讲述了线性模型,Logistic回归模型,Softmax模型,他们这种通过定义损失函数,然后计算损失函数的梯度,并求平均值来更新参数。下面介绍一种新的模型。
六、支持向量机(Support Vector Machines)
支持向量机(SVM)是一种非常强大的机器学习模型,能够进行线性、非线性分类、回归问题,还能检测异常值。SVM特别适用于复杂但小型或中型的数据集的分类。
1、线性SVM分类(Linear SVM Classification)
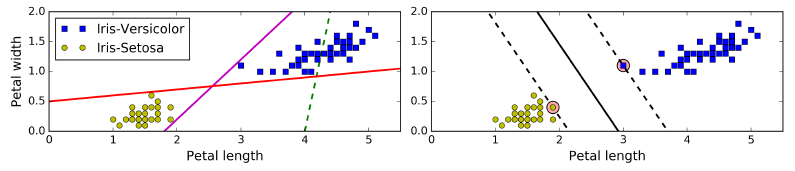
如图,从左图我们可以看到现在有两类数据,只需要1条直线就能把它们分开,其中红线和紫线都能把这两类数据完美的分开,但是两条直线都非常靠近样本,如果有新的样本加入,有比较大的可能会分类错误。
因此线性SVM的思想就是如右图的黑色实线,决策边界在正确分类的同时离最近的样本尽可能的远。而这些最近的样本(途中虚线上的点)即为支持向量(support vector)。因此只要没有点在这些点划分的区域之间,决策边界就只由这些支持向量所决定。
需要注意:SVM对特征之间的尺度比较敏感,因此要先对特征进行缩放(如标准化(StandardScaler))
2、Soft Margin Classification
上面严格的把所有样本用一条直线分开为两类,叫做Hard margin classification。但是在实际情况中,可能存在一些异常点(如下图),左图中的异常点在另一类之中,没有办法用一条直线分开;右图中异常点离另一类很近,虽然能分开,但是决策线看起来非常不好。
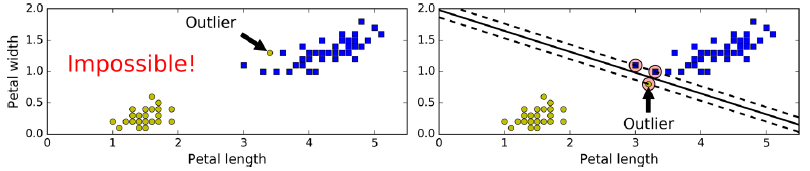
为了解决这种问题,需要一个更加宽松灵活的模型,来权衡尽可能分开以及限制支持向量组成的区域里面点的个数,这就叫Soft Margin Classification
在Scikit-learn的SVM类中,可以通过调剂松弛因子C来权衡,C越大,分类越严格;C越小,在margin内的点越多。

需要注意:如果你的SVM模型过拟合了,可以尝试减小C
下面通过加载Iris数据,标准化后训练一个线性SVM模型(C=0.1),使用的损失函数为hinge loss: max(0,1−t)
import numpy as np
from sklearn import datasets
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris = datasets.load_iris()
X = iris["data"][:, (2, 3)] # petal length, petal width
y = (iris["target"] == 2).astype(np.float64) # Iris-Virginica
svm_clf = Pipeline((
("scaler", StandardScaler()),
("linear_svc", LinearSVC(C=1, loss="hinge")),
))
svm_clf.fit(X, y)
#预测
svm_clf.predict([[5.5, 1.7]])需要注意:SVM分类器不像Logistic回归分类器一样有predict_proba()方法来计算得分(概率),因为SVM只是靠支持向量来构建决策线。而且loss函数一定要记得填”hinge”,因为默认不是”hinge”。
除了使用LinearSVC类来训练线性SVM外,还可以使用SVC类,参数为(kernel=“linear”,C=1),不过这种方法会比LinearSVC慢很多。还可以用SGDClassifier类,参数为(loss=“hinge”,alpha=1/(m*C)),这种使用随机梯度下降方法来训练SVM,虽然没有LinearSVC收敛快,但是能够处理数据量庞大的训练集,而且能够在线学习。
3、非线性SVM分类(Nonlinear SVM Classification)
由于现实数据中更多的是线性不可分的数据。为了能用线性分类器分类线性不可分的数据,其中一种方法就是如上一节的多项式分类想法一样,通过增加 x2,x3 等特征,使得数据能够线性可分。
多项式核(Polynomial Kernel)
基于这个思想,可以增加多项式特征来进行非线性分类。但是如果degree设置的比较小,则比较难分类比较复杂的数据;如果degree设置的比较大,产生了大量模型,导致训练的非常慢。
幸运的是,SVM能用运用一些数学的技巧,称为核技巧(Kernel trick)(后面会说到)。可以不真正的增加这些(如多项式)特征,来达到增加这些特征相同的效果。所以高degree并不会带来特征的急剧增加,因为并没有真正增加特征。这种方法可以在SVC类中使用。下面是一个例子:
from sklearn.datasets import make_moons
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
#构造球型数据集
(X,y)=make_moons(200,noise=0.2)
#使用SVC类中的多项式核训练
poly_kernel_svm_clf = Pipeline((
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="poly", degree=3, coef0=1, C=5))
))
poly_kernel_svm_clf.fit(X, y)其中参数coef0为高degree特征相比低degree特征对模型的影响程度。参数degree为选择多项式特征的维度,参数C为松弛因子。
还可以把决策线画出来看看效果如何:
import numpy as np
import matplotlib.pyplot as plt
xx, yy = np.meshgrid(np.arange(-2,3,0.01), np.arange(-1,2,0.01))
y_new=polynomial_svm_clf.predict(np.c_[xx.ravel(),yy.ravel()])
plt.contourf(xx, yy, y_new.reshape(xx.shape),cmap="PuBu")
plt.scatter(X[:,0],X[:,1],marker="o",c=y)
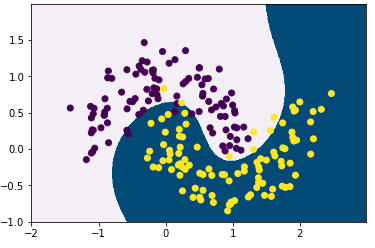
可以看到能够比较好的完成非线性分类。
需要注意:模型的参数应该使用Grid search来调整到一个比较好的状态,如果过拟合(可以通过交叉验证来评价),则可以适当减小degree;如果欠拟合,则增加。
高斯径向基核(Gaussian RBF Kernel)
除了通过多项式增加特征以外,还有别的增加特征的方式,比如通过Gaussian Radial Basis Function (RBF)增加相似特征。高斯RBF的表达式为:
如下左图为一维线性不可分的情况,比如通过设置参数
γ
为0.3,参数
l
(landmark)为-2和1,可以看到RBF函数对应的函数曲线类似钟形。假设为
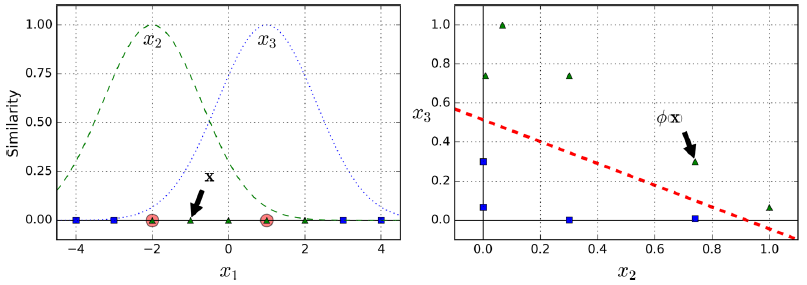
如何选择landmark。 最简单的方法是在数据集中的每个实例的位置创建一个landmark。这创建了许多特征,从而使得变换后的训练集将是线性可分的。缺点是具有m个实例和n个特征的训练集被转换成具有m个实例和m个特征的训练集(假设放弃了原始特征)。如果训练集非常大,则会得到大量的特征,影响计算速度。
然而对于SVM,正如上面所说可以并不真正增加特征而达到同样的效果,下面利用SVC类的RBF核来试验一下:
#训练RBF核SVM
rbf_kernel_svm_clf = Pipeline((
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="rbf", gamma=5, C=0.001))
))
rbf_kernel_svm_clf.fit(X, y)
#画出决策线
import numpy as np
import matplotlib.pyplot as plt
xx, yy = np.meshgrid(np.arange(-2,3,0.01), np.arange(-1,2,0.01))
y_new=rbf_kernel_svm_clf.predict(np.c_[xx.ravel(),yy.ravel()])
plt.contourf(xx, yy, y_new.reshape(xx.shape),cmap="PuBu")
plt.scatter(X[:,0],X[:,1],marker="o",c=y)
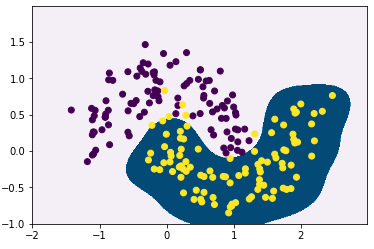
可以看到实现了非线性分类,然而决策边界范围很小,如果 γ 比较大,会使得决策线变窄,变得不规则。相反,小的 γ 使决策线变宽,边平滑。所以 γ 就像一个正则化参数:如果你的模型过拟合,可以适当减少它,如果它欠拟合,可以增加它(类似于C超参数)。
除了多项式核和高斯RBF核以外还有一些别的核,但都不太常用,一般用于一些特殊数据。
有这么多的内核可供选择,应该使用哪一个?一个经验法则,应该总是先尝试线性内核(LinearSVC比SVC(kernel =“linear”)快得多),特别是当训练集非常大或者有很多特征的时候。如果训练集不是太大,应该尝试高斯RBF核; 它在大多数情况下运行良好。如果你有空闲时间和计算能力,你还可以使用交叉验证和网格搜索来试验其他一些内核,特别是如果有专门用于你的训练集的数据结构的内核。
3、SVM回归(SVM Regression)
SVM除了能进行分类任务以外还能做回归任务。与SVM分类任务尽量让点在margin以外,而SVM回归则是尽量让点在margin以内通过参数 ε 控制margin的大小, ε 越大,margin越大,否则越小。(如下图)
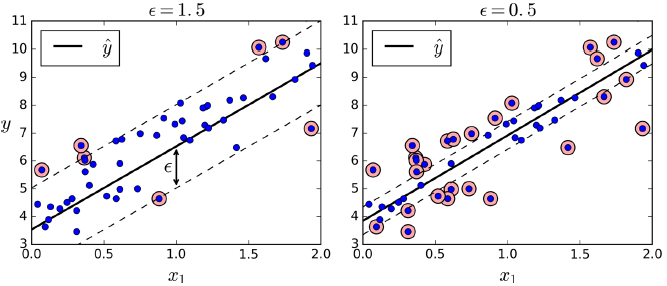
下面为训练一个线性SVM回归模型的例子,对应的类为LinearSVR
from sklearn.svm import LinearSVR
svm_reg = LinearSVR(epsilon=1.5)
svm_reg.fit(X, y)SVM非线性回归问题与分类问题类似,通过设置核来实现。
from sklearn.svm import SVR
svm_poly_reg = SVR(kernel="poly", degree=2, C=100, epsilon=0.1)
svm_poly_reg.fit(X, y)
上一篇:机器学习实战(用Scikit-learn和TensorFlow进行机器学习)(五)
下一篇:机器学习实战(用Scikit-learn和TensorFlow进行机器学习)(七)

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)