基于tensorflow的栈式自编码器实现
这周完全没有想法要看栈式编码器的,谁知误入桃花源,就暂且把栈式自编码器看了吧。由于手上有很多数值型的数据,仅仅是数据,没有标签,所以,迫切需要通过聚类抽出特征。无意间看到别人家公司的推荐系统里面用到sdae,于是,找了个ae程序,建了个sdae,跑一下自己的数据。希望sdae在后面的推荐系统中能有用。
啰嗦了那么多,先看看原理吧。http://ufldl.stanford.edu/wiki/index.php/%E6%A0%88%E5%BC%8F%E8%87%AA%E7%BC%96%E7%A0%81%E7%AE%97%E6%B3%95
斯坦福的这篇文章原理讲的很到位了。
一.基本原理
AE的原理是先通过一个encode层对输入进行编码,这个编码就是特征,然后利用encode乘第2层参数(也可以是encode层的参数的转置乘特征并加偏执),重构(解码)输入,然后用重构的输入和实际输入的损失训练参数。
对于我的应用来说,我要做的首先是抽取特征。AE的encode的过程很简单,是这样的:
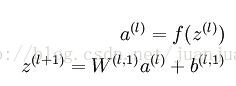
SAE是这样的:
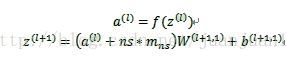
训练过程中,两个SAE分别训练,第一个SAE训练完之后,其encode的输出作为第二个SAE的输入,接着训练。训练完后,用第二层的特征,通过softmax分类器(由于分类器 还是得要带标签的数据来训练,所以,实际应用总,提取特征后不一定是拿来分类),将所有特征分为n类,得到n类标签。训练网络图
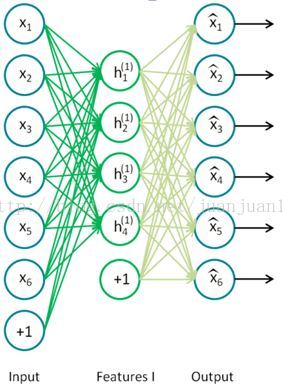
step 1
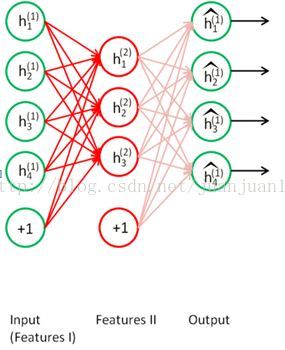
step 2
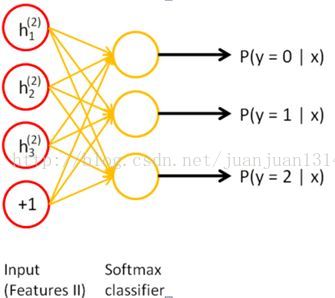
step 3
按照UFLDL的说明,在各自训练到快要收敛的时候,要对整个网络通过反向传播做微调,但是不能从一开始就整个网络调节。
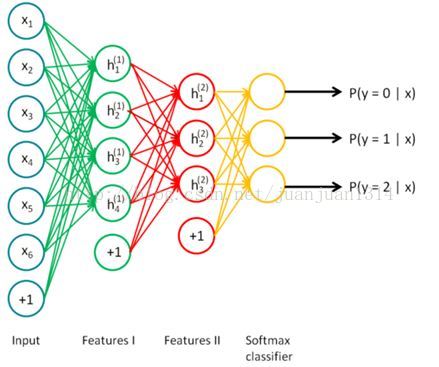
两个SAE训练完后,每个encode的输出作为两个隐层的特征,然后重新构建网络,新网络不做训练,只做预测。网络如下:
二.程序
1. 首先建立自编码器的网络
采用添加高斯噪声的dae,这是tensorflow 的models-master里面提供的一种自编码器。
#coding: utf-8
import tensorflow as tf
import numpy as npimport Utilsclass AdditiveGaussianNoiseAutoencoder(object): def __init__(self, n_input, n_hidden, transfer_function = tf.nn.softplus, optimizer = tf.train.AdamOptimizer(), scale = 0.1): self.n_input = n_input self.n_hidden = n_hidden self.transfer = transfer_function self.scale = tf.placeholder(tf.float32) self.training_scale = scale network_weights = self._initialize_weights() self.weights = network_weights # model self.x = tf.placeholder(tf.float32, [None, self.n_input])
#编码
self.hidden = self.transfer(tf.add(tf.matmul(self.x + scale * tf.random_normal((n_input,)),
self.weights['w1']),
self.weights['b1']))
#解码
self.reconstruction = tf.add(tf.matmul(self.hidden, self.weights['w2']), self.weights['b2'])
# cost
self.cost = 0.5 * tf.reduce_sum(tf.pow(tf.sub(self.reconstruction, self.x), 2.0))
self.optimizer = optimizer.minimize(self.cost)
init = tf.initialize_all_variables()
self.sess = tf.Session()
self.sess.run(init)
def _initialize_weights(self):
all_weights = dict()
all_weights['w1'] = tf.Variable(Utils.xavier_init(self.n_input, self.n_hidden))
all_weights['b1'] = tf.Variable(tf.zeros([self.n_hidden], dtype = tf.float32))
all_weights['w2'] = tf.Variable(tf.zeros([self.n_hidden, self.n_input], dtype = tf.float32))
all_weights['b2'] = tf.Variable(tf.zeros([self.n_input], dtype = tf.float32))
return all_weights
#优化参数
def partial_fit(self, X):
cost, opt = self.sess.run((self.cost, self.optimizer), feed_dict = {self.x: X,
self.scale: self.training_scale
})
return cost
def calc_total_cost(self, X):
return self.sess.run(self.cost, feed_dict = {self.x: X,
self.scale: self.training_scale
})
def transform(self, X):
return self.sess.run(self.hidden, feed_dict = {self.x: X,
self.scale: self.training_scale
})
def generate(self, hidden = None):
if hidden is None:
hidden = np.random.normal(size = self.weights["b1"])
return self.sess.run(self.reconstruction, feed_dict = {self.hidden: hidden})
def reconstruct(self, X):
return self.sess.run(self.reconstruction, feed_dict = {self.x: X,
self.scale: self.training_scale
})
def getWeights(self):
return self.sess.run(self.weights['w1'])
def getBiases(self):
return self.sess.run(self.weights['b1'])2. sdae建立
#coding: utf-8
from __future__ import division, print_function, absolute_import
import numpy as np
import tensorflow as tf
from autoencoder_models.DenoisingAutoencoder import AdditiveGaussianNoiseAutoencoder
import prepare_data
#prepare_data.py是自己写的数据整理文件,通过这个文件清理数据,并将其分成M-1份测试数据,1份测试数据
pd = prepare_data.TidyData(file1='data/dim_tv_mall_lng_lat.txt',
file2='data/ali-hdfs_2017-03-22_18-24-37.log',
M=8,
seed=12,
k=5)
pd.read_mall_location_np()
pd.calc_min_distance()
print ('data read finished!')
#定义训练参数
training_epochs = 5
batch_size = 1000
display_step = 1
stack_size = 3 #栈中包含3个ae
hidden_size = [20, 20, 20]
input_n_size = [3, 200, 200]
def get_random_block_from_data(data, batch_size):
start_index = np.random.randint(0, len(data) - batch_size)
return data[start_index:(start_index + batch_size)]
#建立sdae图
sdae = []
for i in xrange(stack_size):
if i == 0:
ae = AdditiveGaussianNoiseAutoencoder(n_input = 2,
n_hidden = hidden_size[i],
transfer_function = tf.nn.softplus,
optimizer = tf.train.AdamOptimizer(learning_rate = 0.001),
scale = 0.01)
ae._initialize_weights()
sdae.append(ae)
else:
ae = AdditiveGaussianNoiseAutoencoder(n_input=hidden_size[i-1],
n_hidden=hidden_size[i],
transfer_function=tf.nn.softplus,
optimizer=tf.train.AdamOptimizer(learning_rate=0.001),
scale=0.01)
ae._initialize_weights()
sdae.append(ae)
W = []
b = []
Hidden_feature = [] #保存每个ae的特征
X_train = np.array([0])
for j in xrange(stack_size):
#输入
if j == 0:
X_train = np.array(pd.train_set)
X_test = np.array(pd.test_set)
else:
X_train_pre = X_train
X_train = sdae[j-1].transform(X_train_pre)
print (X_train.shape)
Hidden_feature.append(X_train)
#训练
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(X_train.shape[1] / batch_size)
# Loop over all batches
for k in range(total_batch):
batch_xs = get_random_block_from_data(X_train, batch_size)
# Fit training using batch data
cost = sdae[j].partial_fit(batch_xs)
# Compute average loss
avg_cost += cost / X_train.shape[1] * batch_size
# Display logs per epoch step
#if epoch % display_step == 0:
print ("Epoch:", '%04d' % (epoch + 1), "cost=", "{:.9f}".format(avg_cost))
#保存每个ae的参数
weight = sdae[j].getWeights()
#print (weight)
W.append(weight)
b.append(sdae[j].getBiases())

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)