下一代大规模增量索引平台 – Percolator
本文作者:百度 刘景龙 原文刊登于《程序员》杂志2011年第二期。觉得写的非常好!所以转过来跟大家分享分享!
下一代大规模增量索引平台 – Percolator
简介
继google的3大基石GFS, MapReduce,BigTables之后,Google在10月份osdi会议上公布了论文《Large-scale Incremental Processing Using Distributed Transactions and Notification》,介绍了他们最新的内容索引技术。这项技术是Google下一代内容索引系统Caffeine的核心。该框架在抓取网页的同时进行对文档的处理,将平均延迟降低为原来的百分之一,平均文档寿命(document age)降低50%。
传统索引系统通常采用了多级索引的方式,按照网页的重要性将网页进行分级,分别按照小时,天,周对网页库进行更新。其特点是将网页收录到各级网页库时需要对全库进行处理。这种模式最大的缺点是新产生的网页或者信息不能被及时的收录到网页库中,而且定期做全库扫描也会造成计算资源的浪费。根源在于现有MapReduce框架对于网页库的处理粒度过粗,一次全库的更新需要几天的时间才能完成。针对这个问题Percolator细化了更新粒度,提供了对文档的随机访问,实现了对单个文档的处理,避免了MapReduce对全库的遍历。下面我们介绍下Percolator的设计及实现。
设计
在最初的Percolator设计中曾经考虑过直接使用BigTable存储网页库,但是对于构建网页库而言,需要比BigTable行原子性更强的一致性语义。而BigTable的可扩展性,容错以及负载均衡等设计是非常优秀的,为了避免重新发明“轮子”,Percolator在BigTable基础上,通过两阶段提交实现了跨行,跨表事务以及notifiication框架。
Percolator提供了对PB级网页库的随机访问功能。我们可以单独的处理每一个页面,从而避免使用mapreduce框架重建索引库时对全库的scan操作。此外为了实现高吞吐以及高并发下的同步,Percolator支持ACID兼容的事务语义。
对增量索引系统而言除了用户触发的操作外,很多处理流程是数据触发的。 Percolator中数据的变化,并且根据数据的变化进行触发后续的一系列操作(比如:页面解析,内容抽取等)。为了满足此需求,Percolator提供了notification语义。notification语义类似DBMS中的触发器,当Percolator中的某个cell数据发生变化,就触发应用开发者指定的Observer程序。一系列Observer程序通过“责任链”的方式级联,并完成各自逻辑。
作为一个基础架构,Percolator继承了BigTable的一致性和容错模型,并且可以通过增加机器实现集群的线性扩展。此外,它提供了友好的开发接口,使索引系统的开发者专注于页面解析,抽取,分词等算法的开发,而不必被分布式系统中常见的一致性,容错等问题所困扰。
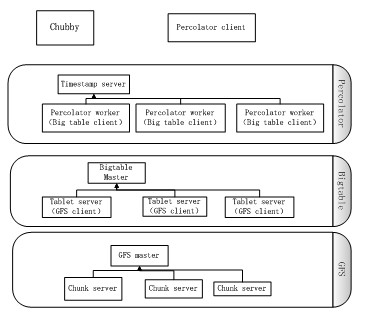
图1 Percolcator主要组件
如图1所示,Percolcator是构建在GFS和BigTable之上,主要包含3个组件。 timestamp server,Percolcator worker,Chubby。
Timestamp server提供了统一时间的服务,它保证每次获取的时间戳单调递增,timestamp server会持久化时间戳,以保证服务重启时时间戳的顺序性。Chubby 服务提供了分布式锁服务,保证Percolcator在处理全局临界资源时,可以互斥访问。Percolcator worker是Percolator中的主要部分,实现了跨行/跨表事务和notification机制。为获得更好的吞吐量,Percolcator worker启动了多个BigTable client对BigTable进行并发访问。Percolcator worker不持久化任何数据,换言之每个Percolcator worker都是无状态的,如果Percolator worker节点失效,Percolator client可以通过重试切换到另一个Percolator worker,从而不影响服务。
Percolator的设计主要针对大规模数据存储,以及对网页索引具有实时性更新需求的应用。相对于传统的OLTP,Percolator没有集中的事务管理机制,如果有机器在进行事务的过程中失效,失效事务中的锁释放是一件比较大的挑战。由于Percolator用于网页库建索引这样的线下服务,放松了对实时性的要求,采用一种延迟的方式清理锁。
实现
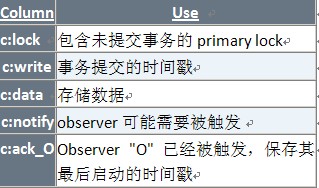
Percolator提供了类似BigTable的用户接口,Percolator中的cell通过BigTable中5列来表示。其中lock, write,data 3列用于实现Percolator事务的功能。Notify和ack_O这2列是为了实现Percolator的notification机制。
下表为Percolator在BigTable中的schema。
下面我们通过Percolator中的两个主要的feature:事务和notification框架来介绍下Percolator的实现机制。
事务
Percolaor在BigTable的基础上,提供了跨行,跨表的ACID语义。Percolator中的事务是通过传统的两阶段提交实现。
下面我们用一个例子来说明Percolator是如何实现事务的。Bob账户中有$10, Joe 账户中有$2,Bob转$7给Joe。
1. 初始状态, joe账户有$2 ,Bob有$10 ;write 列中的 6:data @ 5 表示当前的数据写入的时间戳是5;

2. 开始事务,在时间点7对Bob的账户加Primary lock并且向Bob账户写入转账结果$3;

3. 在时间点7对joe的账户加secondary lock,并且向joe账户写入转账结果$9.(secondary lock列中包含对primary lock的引用,row key为Bob);

4. 事务提交的第一阶段, 提交 primary, 移除lock 列的内容,在 write 列写入事务commit点的时间戳;

5. 事务提交的第二阶段,在Joe行中删除secondary lock,并且在Joe行写入commit点的时间戳;
Percolator就是通过以上5步完成事务的两阶段提交。对于分布式事务来讲,由于没有集中事务管理机制,其较大的困难就是在处理事务的过程中,Percolator client如果出现异常crash,如何清除已有的锁并重新使用被加锁的行。
Percolator采用的是比较消极的锁释放机制。如果事务A在执行的过程中,Percolator client crash掉了,Percolator 并不会主动释放事务A所占有的锁。如果事务B 在进行的过程中,使用到了事务A占有的数据,则由事务B负责锁的释放。
此时,有件比较棘手的事情就是:我们应当如何区分事务A是由于Percolator client crash导致不能完成,还是事务A长时间处于commit 的状态。为了避免此类竞态条件,我们需要一种锁机制来同步应该执行事务B cleanup任务或者事务A的commit任务。由于BigTable能够保证行的原子性,Percolator 很自然的使用BigTable的一个cell作为锁(称为primary lock),先抢到primary lock的则可以执行,否则退出。
Notification机制
粗略的讲,Notification机制类似于DBMS中的触发器,即用户对cell的修改都会触发观察该cell的程序(我们把这个程序称为”Observer”)。多个Observer组成一个”责任链”,当被观察的cell被修改的时候,Observer链上的全部Observer将被触发。
在实现上,为了能够及时发现被修改的cell,Percolator在其每一行中增加了一个BigTable列notify,用于标识被修改且没有触发执行Observer的cell。为了发现被标识为notify的cell,每个Percolator worker都会随机选取tablet,并进行scan。对于被标识为notify的dirty cell,则触发observer链。为了避免多个worker同时scan相同的tablet,worker使用分布式锁服务(Chubby)在开始scan一个tablet的时候对tablet进行加锁。对于网页库而言,这种周期性的对全表上P级数据进行scan是一个非常低效的操作,为了对其优化减少每次scan的数据量,Percolator利用了BigTable按列存储的优势,将notify列指定为单独的locality group,保证worker只对notify列进行scan,避免了全表扫描造成的对多余数据的加载。
此外,为了区分已被触发的Observer,Percolator增加了列ack_O,(表示名字为O的Observer对应的ack),该列的内容为对应Observer的最后启动时间。当被观察的列被修改,Percolator启动一个事务来处理notification。该事务读取被观察的列以及其相关联的ack列,如果该column最后写时间大于ack_O中的时间戳,则认为该column对应的Observer需要被触发。否则,认为Observer已经被触发。
在Notification机制的实现上需要考虑以下几个重要问题:
1. 如何防止多个notification事务的无限循环?
2. 如果多个notification事务触发了对同一个cell的修改,如何避免并发修改造成的正确性问题?
对于问题1当前Percolator实现中并未对notification事务的无限循环进行检测和防止,所以应用开发者必须在Observer开发中警惕此种情况,避免notification循环的出现。
对于问题2,Percolator的解决方法是使每一个被触发的Observer为一个事务,如果启动了多个Observer,同时修改一个cell,则事务锁机制可以避免重复修改引入的正确性问题。
总结
本文简单介绍了下一代大规模增量索引平台-Percolator所要解决的问题,实现的方法。该平台构建在Big Table和GFS上,利用了GFS的数据安全,BigTable的行原子性,负载均衡以及服务容错等优越特性,提供了稳定,可扩展的增量索引构建平台,并且相对于传统索引技术而言,带来了搜索结果的实时性和集群资源利用率的全面提升。在一窥Google基础架构的同时,我们可喜的看到,作为Percolator中最主要的2大功能的身影已经出现在HBase社区的开发计划中(Transaction和Coprocessor),下一代大规模增量索引平台离我们并不遥远。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)