从零开始使用tensorflow(2)——词向量
前面记录了安装过程,现在开始使用词向量。
一.对tf的肤浅认识
首先是tf的基本总结(时间有限,认识比较肤浅):
(1). 使用图来表示计算;
(2). 在session中执行图;
(3). 使用tensor来表示数据;
(4). Variable维护状态
(5). 使用feed和fetch可以为任意的操作赋值和获取数据。
看起来是不是蛮简单的,但其实用起来不容易(可能本人道行太低)。
1. 跑tf的过程:
(1). 构建图
构图过程就是自己建立网络的过程。主要构建op和op之间的传递,op之间通过tensor实现数据传输。Op右构造器构造(tf.constent、tf.Variable、tf.matmul等),构造器的输入是op的输入。
库里有一个默认的图,一般是在默认图中添加op。
(2). 执行图
构造完成后,可以启动图,首先创建一个session,创建是无参数传入,则表示启动默认图。
通过session.run()来执行图,可以添加参数,参数为op,执行完后返回op的执行后的结果。
(3). 保存图
在训练创建图时,可以定义saver=tf.train.saver(),如果没有加参数,则会默认把所有变量全部保存,此时,保存的是图中的变量。
在执行完图后,做saver.save(session,save_path,…)即可把整个模型保存下来。
(4). 恢复模型
训练并保存一次模型后,模型可重复恢复,使用。在恢复模型前,也要先建图,在图中部署使用模型做计算的op和计算过程,此时定义的op需要与训练时定义的op对应(可以不完全复制,但此时要用的op要包含在训练op中),然后任然定义saver=tf.train.saver(),保存变量。
然后用saver.restore(session,save_path,…)加载模型,接下来,可以用session.run()执行图。
二.词向量
之前已经理过一次word2vec的算法了,单独的word2vec和tf均采用的mikolov大神的wordembedding算法,所以,这里只是操作,不做算法分析。
Tf中包含的word2vec例子一共3个,word2vec_basic.py(examples/tutorial/word2vec)、word2vec_optimized.py、word2vec.py(models/embedding),
word2vec_basic.py比较简单,下载text8然后选择词频较高的5个词训练和测试,用distance来测试。完成后不保存模型,用t分布将词的分布用matplot显示出来。
word2vec_optimized.py和word2vec.py的过程几乎是一样的,只是后者要做summary,会保存日志,可以通过tensorboard来可视化,两者都要保存模型。
用word2vec_optimized.py和word2vec.py来训练中文语料,epoch选择15次效果就很好了。(效果如下)
葫芦娃
=====================================
葫芦娃 1.0000
葫芦兄弟 0.5317
小葫芦 0.4907
金刚葫芦娃 0.4874
狩猎季节 0.4858
黑猫警长 0.4719
哪吒闹海 0.4711
奥创纪元 0.4701
战象 0.4530
美少女战士 0.4506
葫芦小金刚 0.4506
童年 0.4491
虹猫蓝兔七侠传 0.4428
沙人 0.4428
]] 0.4372
西游记 0.4351
变种时代 0.4334
新女婿时代 0.4330
电影版 0.4323
法柜奇兵 0.4302
之前使用word2vec时,一直只全局迭代(epoch)5次,在tf中迭代15次,效果明显比5次好很多。说明,里面那些默认参数也是需要调一调的。
用tensorboard可视化如下:
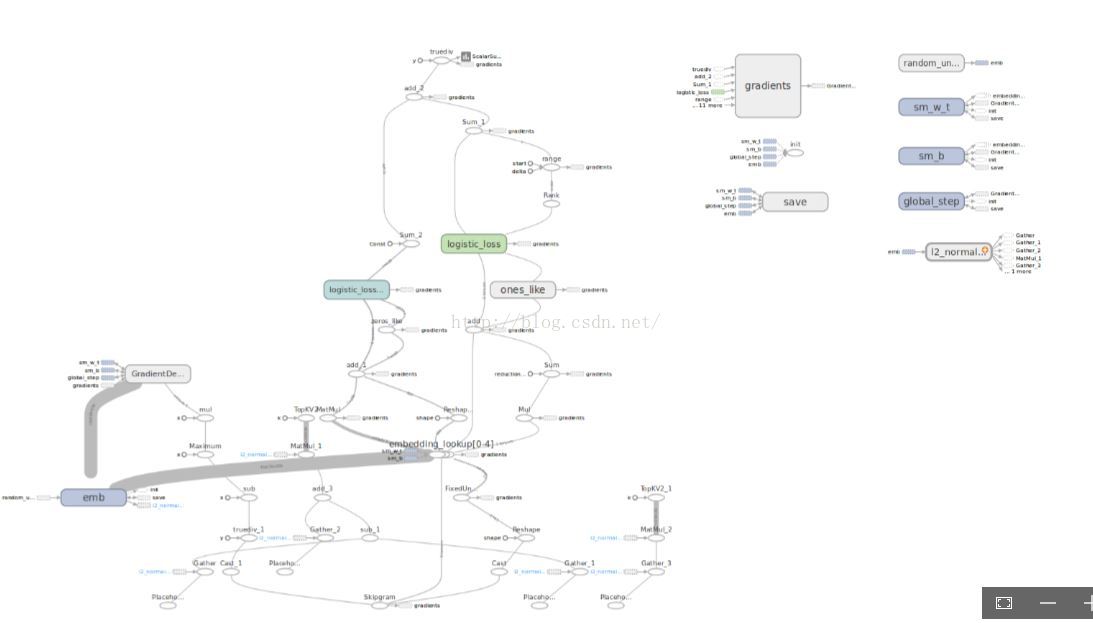
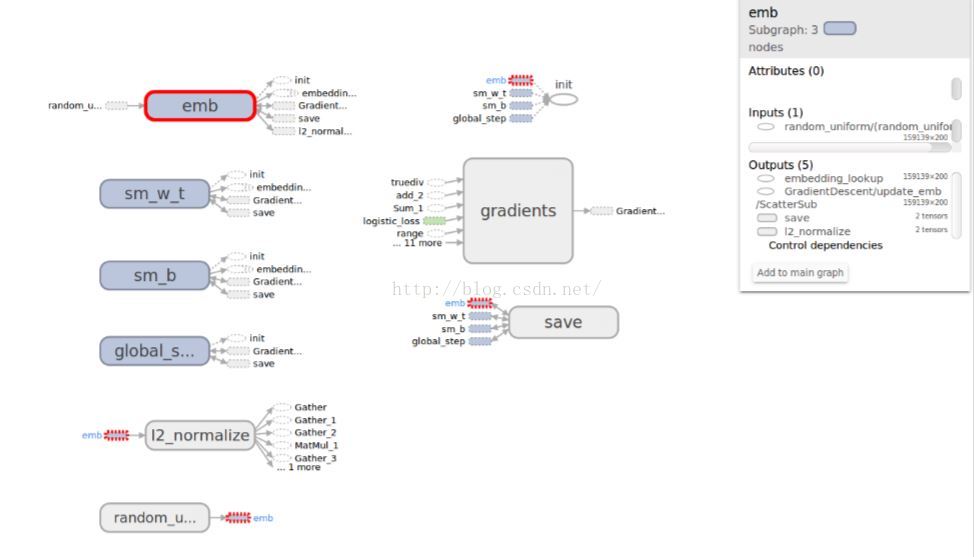
其中,emb、swm_w_t、sm_b、gloab_step建图时添加的。可以对比程序和图看看。图中,每个op的输入、输出、涉及到的网络都可以点击查看细节,这点真的很好。
三.此次使用遇到的问题总结
(1). 对tensor和op的混淆。
在c系编程中,很容易把数据传输跟变量、指针等有实际名字的东西结合起来,因此,不自觉的把op当成tensor来调用。
从图中取tensor的时候,名字实际上是<op>:<out_idx>,前面是op的名字,后面是第几路输出。液就是说tensor实际上是op的某一路输出或者输入,tensor就是一股数据。
(2). 被placeholder坑了。以为占位符也相当于是变量,所以在建图的时候把某些op定义成占位符,结果在save的时候,placeholder根本不被保存,导致在加载模型时,用placeholder定义的假op是不存在的。
(都是很二的错误啊!)
四.Caffe和tf的不成熟对比
之前用过caffe,所以,这里就caffe和tf的使用(仅仅只敢评价使用)做个比较。
(1). Caffe开源更早,早期使用的人多一些,可找到的使用心得也多一些,像薛开宇的“caffe学习笔记”、知名博主卜居的书“21天实战caffe”,写得都很好。可以让我等小菜很顺利的跑很多例子。而tf除了中文的官方文档,其他中文资料较少。本人在几天的使用过程中就遇到诸多问题,而无法查找。
(2). Caffe使用prototxt就可以设置网络参数,并建立网络;而tf是用python先创建图,然后执行的,对python和脚本务必陌生的我,也觉得有点头大。
(3). Caffe在执行时,日志输出比tf清晰一些,但是tf有可视化工具,tensorBoard,这个如果想掌握细节,tfboard真的很详细清晰。
(4). Tf虽然操作不那么友好,但是,在操作过程中真的能学到很多东西。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)