解决网页元素无法定位(NoSuchElementException: Unable to locate element)的几种方法
Python 2.7
IDE Pycharm 5.0.3
姊妹篇请见解决Selenium弹出新页面无法定位元素问题(Unable to locate element)
只解决一个问题--NoSuchElementException: Message: Unable to locate element
出错形式
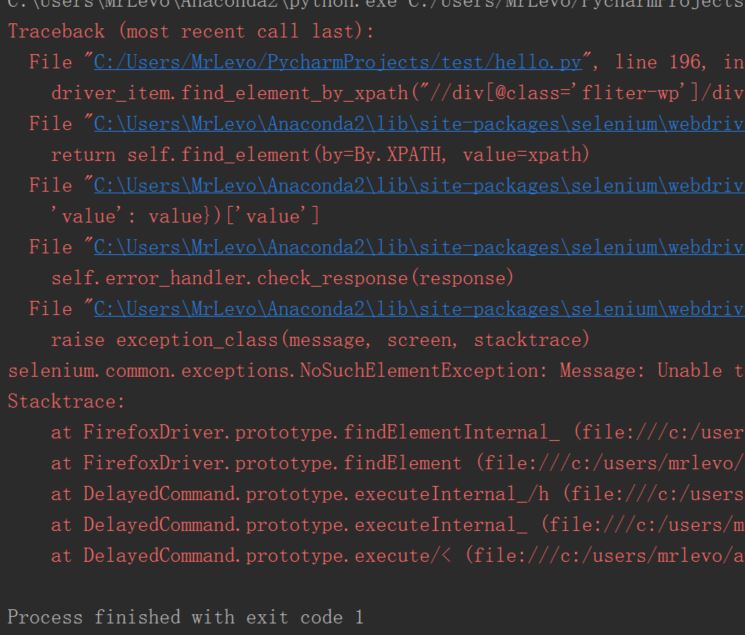
出错原因
1.可能元素加载未完成
元素加载没完成,同样的路径定位,每次测试结果确是不一样的,有时候抛出错误,有时候正常!这就比较蛋疼了,也就是说,和你的定位方法半毛钱关系没有,而很大程度上取决于你的电脑和网速!
1.解决方案A:添加两行代码
wait = ui.WebDriverWait(driver,10)
wait.until(lambda driver: driver.find_element_by_方法("定位路径自己来"))WebDriverWait(driver,10)的意思是;10秒内每隔500毫秒扫描1次页面变化,当出现指定的元素后结束。driver是前面操作webdriver.firefox()的句柄
完整的小段代码是:
from selenium import webdriver
import selenium.webdriver.support.ui as ui
driver_item=webdriver.Firefox()
url="https://movie.douban.com/"
wait = ui.WebDriverWait(driver_item,10)
driver_item.get(url)
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[5]"))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[5]").click()
1.解决方案B:使用while+try…except结合
下面来个例子,完整的可运行代码如下:
from selenium import webdriver
import time
import os
driver_item=webdriver.Firefox()
url="https://movie.douban.com/"
driver_item.get(url)
while 1:
start = time.clock()
try:
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[5]").click()
print '已定位到元素'
end=time.clock()
break
except:
print "还未定位到元素!"
print '定位耗费时间:'+str(end-start)
运行结果如下:
还未定位到元素!
已定位到元素
定位耗费时间:0.262649990301分析
开启页面后,并不是元素都一次性加载完成的,依赖于网速和电脑,从B方法中可见,所耗费的时间,还有一种静态的方法就是我以前常用的sleep,一般睡一秒就够了,但是对于不同电脑不同网速的情况,建议还是使用动态方法,也就是A方法,以变应变!
从代码可读性上和效率上都是A方法比较好,更加符合python的特性,简洁优美,而B方法应该是我这样初学者自己能想到的一种方法,先得自己想解决方案,然后再参考现有方法,我感觉这样才有意义。
2.本身定位方法错误
这也就是最常见的了,也是最容易犯的错误,自己对元素定位方法不够熟练,就很容易错误了,所以多想想该怎么定位才最容易,我现在最喜欢的是用xpath方法定位,DOM树的结构挺清晰的,可能我还是新手的原因吧!
2.解决方案
多查询元素定位方法,多使用多熟练,吐槽一下正则。。。相比较正则,我还是更喜欢BeautifulSoup或者xpath来用,额。。。
比方说,我要看看BeautifulSoup到底规则效果怎么样,那我会单独写个测试模块
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import re
#find_all() 和 find() 只搜索当前节点的所有子节点,孙子节点等.
# find_parents() 和 find_parent() 用来搜索当前节点的父辈节点,
# 搜索方法与普通tag的搜索方法相同,搜索文档搜索文档包含的内容
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup=BeautifulSoup(html,"lxml")
#soup=BeautifulSoup(open('index.html'),"lxml")#若本身有html文件,则打开
#print soup.prettify()
print soup.title
print soup.a.string
print soup.a['href']
print soup.a['class']这个我就做个比方,什么时候我要用BS4了我会单独测试下自己的规则好不好使,毕竟不是老司机。

Tips
1.测试阶段调用Firefox来做,这样更加直观具体,到最后可以调用phantomjs.exe。
2.分模块测试自己的idea,光想远远不够。
3.最好有分屏的电脑,一屏显示代码,一屏显示实现过程
总结
遇到问题看来还是需要一步步来,分析各个模块之间的衔接性和模块完整性,单独把模块拿出来进行测试,不然一个比较大点的程序出错在哪都很费劲,而且,如果是自己写的程序,那么推荐一步步实现,哪一步该有哪一步的功能,这样逻辑才够清晰,这是写给自己的话,如果对你有帮助,我也感到很荣幸!
下篇预告
基本上已经写完豆瓣高分电影及细节的爬取了,也遇到些困难,下篇再说遇到问题和怎么解决
吐槽
哈尔滨好热,,,,学校放假了,都没地方吃饭了,,,,,实验室没几个鸟人。。。。人生不仅需要代码和论文,我还要空调和西瓜!!!

致谢
@Eastmount–[Python爬虫] Selenium+Phantomjs动态获取CSDN下载资源信息和评论
@转–selenium webdriver学习(十一)-怎么等待页面元素加载完成
@阳光总在风雨后–webdriver 的三种等待方式

新一代开源开发者平台 GitCode,通过集成代码托管服务、代码仓库以及可信赖的开源组件库,让开发者可以在云端进行代码托管和开发。旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 34
34 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)