
跟着TensorFlow的进阶级教程实现MNIST库的训练
- 背景介绍
- 代码实现及结果
- 小问题
- ResourceExhaustedError的原因及解决方式
- Saver()进行模型存储及恢复
- 再说一下DL的运行时间吧
- 小结
- 优质资源分享
背景介绍
做这件事的初衷有二:
①做完入门级的,自然要进阶一下。
②之前做到的准确率只有92%,据说进阶版可以把准确率做到99.2%
步骤还是参考TensorFlow的中文教程,自然没有上次那么简单,有些坑掉进去了,好歹最后爬出来了,记录一下。
这次用的不是一个单纯的一层输入+一层输出+softmax概率映射层的三层网络。多加了了两个隐藏层以及一个全连接层,相当于6层CNN了。
代码实现及结果
这个照着教程来做的话,感觉应该也没有问题,注意一些变量名的细节比如y_conv替代了原来的y,敲出来一般就能跑通啦。
结果的话,没有做迭代次数以及cost函数的实验啦。就简单的一行。
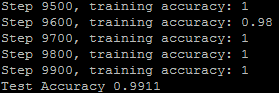
.9911的准确率,还可以吧应该。一是没有跑到2W次循环的训练,二是教程里面好像有说过他用GPU跑的结果,CPU的可以差一些。why?
小问题
①ResourceExhaustedError的原因及解决方式
码好之后,设置了2W的循环次数,15:17挂上开始跑,训练的速度有了明显变慢,到17:33去吃饭的时候只跑了17100次循环。饭罢回来傻眼啦,好长一串log,摘出主要的问题就是下图:

ResourceExhaustedError是啥子?

翻译过来是资源耗尽,不过不太理解,就去搜(承认没有去TensorFLow官网搜是我蠢,那里肯定有相应的说明),百度没得,Stack Overflow竟然也没得,后来在一个同学的吐槽里看到了这个Error。说他开了8G内存都跑不了海量数据,我这1G的难怪会遇到这种问题。大致计算了一下,这个矩阵的尺寸是10000x28x28x32,每个元素是一个float64占用8字节,所以这单个对象就需要占用1.87g的存储空间,还不算其他的系统运行内存和其他变量。肯定崩盘啦。
解决办法呢?就是拆分呀。其实我发现训练的时候都是拿batch=50来做,test时一下用10000太大了,我的做法就是把test数据也分了10份,每份batchsize=1000,跑10次结果取accuracy的平均。由于取数据的接口在input_data.py里写好了,剩下的就是熟悉一下TensorFlow的语法就能写好。
accuracyResult = list(range(10))
for i in range(10):
batch = mnist.test.next_batch(1000)
accuResult[i] = accuracy.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0})
print "Test accuracy:", numpy.mean(accuResult)
②Saver()进行模型存储及恢复
虽然后来这个拆分的test可以跑通了,不过之前训练的模型随着那个ResourceExhaustedError一并消失了,心好累。难道又要重跑(这一波必须重跑了TAT。。),难道以后都要这么伤?那就未必了。TensorFlow提供了Saver()这个类来解决Session参数的存储与恢复。具体的方法还是看存取教程吧。
做的时候存模型比较顺利,制定5000次迭代就存一下,新的模型也可以覆盖之前同名模型,一个模型的大小竟然有38M。

读取模型用于继续训练或者测试时需要再说一下:
a.tf.train.Saver()的定义需要在Session()之前,否则会提示你错误。
b.通过tf.train.Saver().restore进行恢复时,不需要进行变量的初始化,即Session.run(tf.initialize_all_variables())不用做,不过你的变量必须事先定义好。这一点不像matlab双击一下.mat文件就可以把.mat里面的所有参数导入当前workspace,不要期望在一个新的.py文件里导入模型参数就可以直接test了。
当然这些问题的话,只要按照存取教程做,是不会遇到的,我当时就是嘉祥成matlab,想偷懒。
③再说一下运行时间吧
之前还蠢蠢的移位自己的单核1G内存阿里云服务器能hold住Machine Learning,真的是太天真啦。下面对比一下用时吧,同样的MNIST库55000个train_image和10000个test_image:
之前用入门级的3层模型来训练10000次,每次batch100,只用30s不到。
现在用的6层卷积神经网络训练10000次,每次100个batch,用了80分钟。
差距还是蛮大的,更多的层数或者更多的数据就崩盘啦。其实相比平常用matlab做的通信仿真,13W秒跑一个case,这个时间还是能忍的哈。下次跑的时候也应该像matlab那样tic,toc一下,免得我自己手表计时啦。
小结
这两天做的也比较匆忙,只是实现了教程里面的入门内容,完成了个Hello World而已。如果做的有问题欢迎大家批评指正哈。接下来还有挺多需要学习,首要的两条:
①流程框图,通信里面可以通过流程框图来描述一个系统,直观高效。之前实现的部分顶多算识别的一小块,真正的一个应用肯定还需要其他模块,图片获取、图片预处理(定位/size/去噪)、识别信息的转化及应用等。
②NN,CNN的基础知识需要再巩固。
优质资源分享
深度学习路线看看大牛怎么说。
视觉信息介绍,又一个典型的外国大牛写的深入浅出的理论分析,我也正在学习。虽然有些知识以前知道,不过看的目的是 巩固 or 从另一个角度看待问题。
Stack Overflow 据说编程过程中遇到的95%的问题都能在这里找到。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)