
向量数据库FAISS/Chromadb/ES/milvus简单概述
FAISS
FAISS(Facebook AI Similarity Search)是一种高性能的向量相似性搜索库,用于在大规模向量数据集中快速搜索最相似的向量。它是由Facebook AI Research开发的,旨在解决大规模向量搜索的问题,广泛应用于各种领域,如图像搜索、文本搜索、推荐系统等。
FAISS的主要特点和优势如下:
-
高效的相似性搜索:FAISS使用了一系列高效的算法和数据结构,如倒排索引、局部敏感哈希(LSH)等,以实现快速的相似性搜索。它能够在大规模数据集中高效地找到与查询向量最相似的向量。
-
支持多种相似性度量:FAISS支持多种常见的相似性度量,包括欧氏距离、内积和余弦相似度等。这使得它适用于各种不同的应用场景。
-
可扩展性:FAISS支持在多个CPU或GPU上进行并行计算,以加速搜索过程。它还提供了一些优化技术,如分布式索引和量化压缩等,以便在处理大规模数据集时保持高性能。
-
易于使用的API:FAISS提供了简单易用的API,使得用户可以方便地构建和管理向量数据库。它还提供了一些辅助函数和工具,如索引训练器和评估器等,以帮助用户更好地使用和优化FAISS。

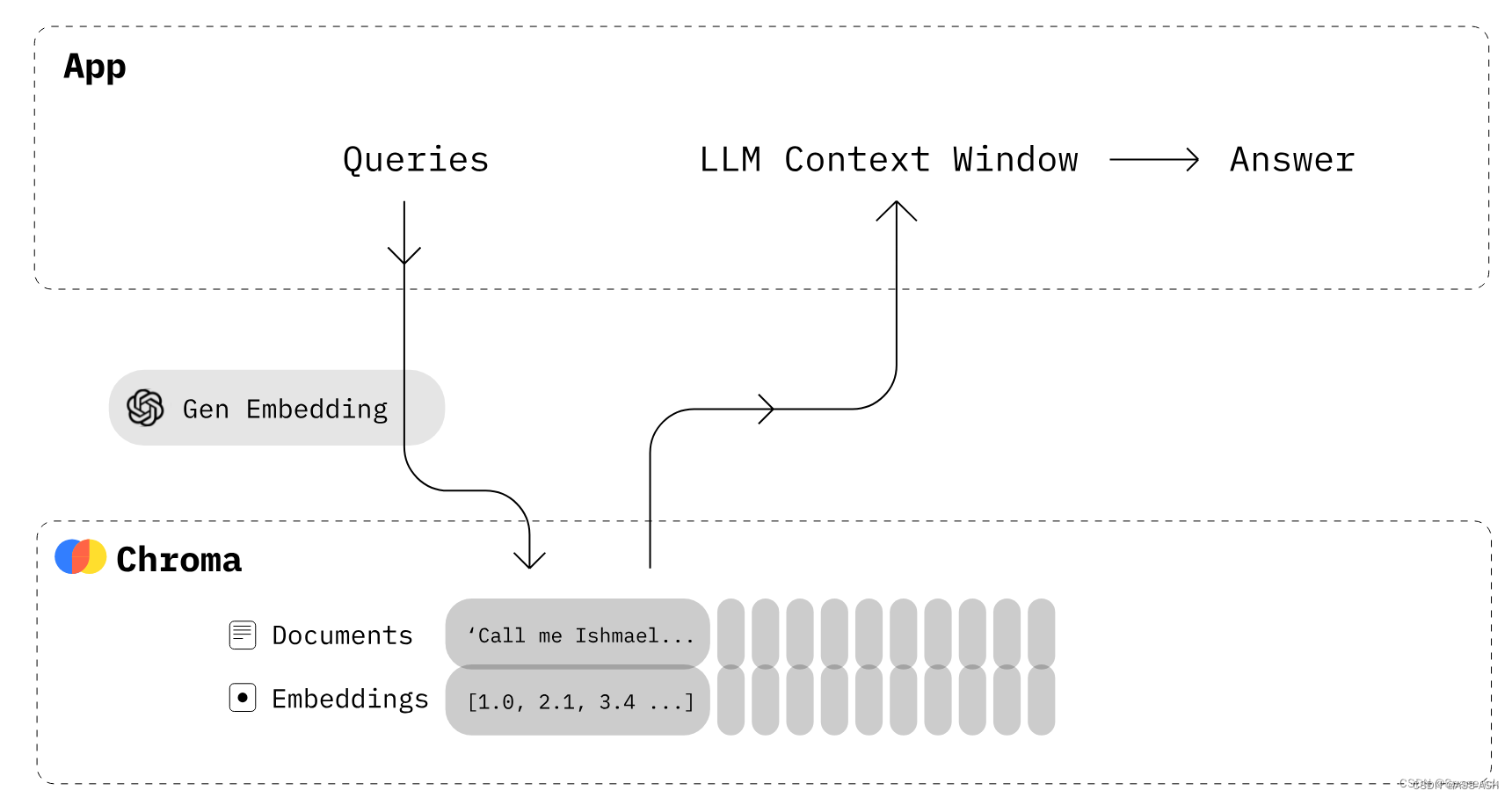
Chromadb
Chromadb是一种用于管理和查询基因组数据的数据库系统。它专门设计用于存储和分析大规模的染色体亚结构数据,如染色体亚带、染色体亚区和染色体亚片段。Chromadb提供了高效的数据存储和检索功能,使研究人员能够快速访问和分析基因组数据。
Chromadb的主要特点包括:
- 高效存储:Chromadb使用了一种优化的数据结构和索引技术,可以高效地存储大规模的基因组数据。它能够处理数百万个染色体亚结构的数据,并提供快速的数据访问速度。
- 强大的查询功能:Chromadb支持灵活的查询语言,可以根据不同的查询条件进行数据检索。用户可以根据染色体位置、基因型、表达水平等多个维度进行查询,并获得准确的结果。
- 可扩展性:Chromadb具有良好的可扩展性,可以处理不断增长的基因组数据。它支持数据的分区和分片存储,可以在需要时进行水平扩展,以满足不同规模的数据需求。
- 数据安全性:Chromadb提供了数据加密和访问控制等安全机制,保护用户的数据免受未授权访问和恶意攻击。

ES
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
Elasticsearch使用Lucene,并试图通过JSON和Java API提供其所有特性。它支持facetting和percolating,如果新文档与注册查询匹配,这对于通知非常有用。另一个特性称为“网关”,处理索引的长期持久性;例如,在服务器崩溃的情况下,可以从网关恢复索引。Elasticsearch支持实时GET请求,适合作为NoSQL数据存储,但缺少分布式事务。
相关概念
cluster:代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
shards:代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
replicas:代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
recovery:代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
river:代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的。
gateway:代表es索引快照的存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘。gateway对索引快照进行存储,当这个es集群关闭再重新启动时就会从gateway中读取索引备份数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
discovery.zen:代表es的自动发现节点机制,es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
Transport:代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
Milvus
Milvus数据库是一个开源的向量数据库,专门用于存储和处理大规模向量数据。它提供了高效的向量相似度搜索和分析功能,适用于各种人工智能和机器学习应用。
Milvus数据库具有以下特点:
-
高性能:Milvus数据库采用了高度优化的向量索引结构和查询算法,能够快速地进行向量相似度搜索和分析。
-
多种数据类型支持:Milvus支持多种向量数据类型,包括浮点型、整型和二进制数据等。
-
分布式架构:Milvus数据库采用分布式架构,可以方便地水平扩展,处理大规模向量数据。
-
多种查询方式:Milvus支持多种查询方式,包括精确查询、范围查询和相似度查询等。
-
可扩展性:Milvus数据库支持在线扩容和动态添加节点,能够灵活应对数据规模的变化。
-
开源社区支持:Milvus是一个开源项目,拥有活跃的社区支持和持续的更新迭代。


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 31
31 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)