
AddressSanitizer理论及实践:heap-use-after-free、free on not malloc()-ed address
AddressSanity:A Fast Address Sanity Checker
摘要
对于C和C ++等编程语言,包括缓冲区溢出和堆内存的释放后重用等内存访问错误仍然是一个严重的问题。存在许多内存错误检测器,但大多数检测器要么运行缓慢,要么检测到的错误类型有限,或者两者兼而有之。
本文介绍了一种新的内存错误检测器AddressSanitizer。我们的工具能够发现堆、堆栈和全局对象的越界访问,以及释放后重用的错误。它采用了专门的内存分配器和代码插桩,该插桩足够简单,可以在任何编译器,二进制翻译系统甚至硬件中实现。
AddressSanitizer在不牺牲全面性的情况下实现了效率。它对程序运行速度的平均仅为下降73%,但它可以在错误发生时准确地捕捉到。它在Chromium浏览器中发现了300多个未知的错误,在其他软件中也发现了许多错误。
1 引言
市场上有数十种内存错误检测工具[3、8、11、13、15、21、23、24]。 这些工具在速度,内存消耗,可检测到的错误类型,检测到错误的概率,支持的平台以及其他特性方面有所不同。 许多工具可以成功地检测到各种各样的错误,但是会产生高昂的开销,或者开销低但检测到bug更少。 我们介绍了AddressSanitizer,这是一种将性能和覆盖范围相结合的新工具。 AddressSanitizer可以发现越界访问(用于堆,堆栈和全局对象)和释放的堆内存的使用,相对较低的73%的速度下降,并且内存使用量增加了3.4倍,使其成为C / C ++应用程序测试领域中的理想选择 。
AddressSanitizer由两部分组成:一个插桩模块和一个运行时库。 插桩模块修改代码,以在每次内存访问时检查影子状态,并在堆栈和全局对象周围创建poisoned redzones,以检测上溢和下溢。 当前的实现基于LLVM [4]编译器基础结构。 运行时库替换malloc,free和相关函数,在分配的堆区周围创建poisoned redzones,延迟释放堆区的访问并进行错误报告。
1.1 贡献
在本文中,我们:
- 表明内存错误检测器可以利用影子内存获得比传统方法低得多的开销和全面性;
- 提出了一种新颖的影子状态编码,可实现紧凑的影子内存(多达128对1的映射),用于检测越界和释放后重用的bug
- 描述针对我们的影子编码的专用内存分配器;
- 评估一个新的可以有效识别内存错误的公开可用的工具。
1.2 大纲
在下一节总结了相关工作之后,我们将在第3节中介绍AddressSanitizer算法。第4节提供了使用AddressSanitizer的实验结果。我们在第5节中讨论了进一步的改进,然后总结了本文。
2 相关工作
本节探讨了现有的内存检测工具和技术。
2.1 影子内存
许多不同的工具使用影子内存来存储与每个应用程序数据相对应的元数据。通常,应用程序地址通过直接缩放和偏移量映射到影子地址,其中整个应用程序地址空间映射到单个影子地址空间,或者通过表查找进行级别转换。直接映射的示例包括TaintTrace [10]和LIFT [26]。 TaintTrace需要一个与应用程序地址空间大小相等的影子空间,这将导致使用超过一般地址空间的正常应用程序无法适应,LIFT中的影子空间是应用程序空间的八分之一。
为了在地址空间布局中提供更大的灵活性,某些工具使用了多级转换方案。 Valgrind [20]和Dr. Memory [8]将它们的影子内存分成几部分,并使用表查找来获取影子地址,这需要额外的内存负载。对于64位平台,Valgrind对32GB地址空间以外的应用程序地址使用附加的表转换。
Umbra [30,31]结合了布局灵活性和效率,避免了通过非均匀且动态调整的缩放比例和偏移方案进行表格查找。Bound- Less [9]将其某些元数据存储在64位指针的16个较高位中,但在慢速路径上会回落到更传统的影子内存中。 LBC [12]使用存储在应用程序内存中的特殊值执行快速路径检查,并依赖慢速路径上的两级影子存储器。
2.2 插桩
大量的内存错误检测器基于二进制插桩。 其中最受欢迎的是Valgrind(Memcheck)[21],Dr.Memory [8],Purify [13],BoundsChecker [17],Intel Parallel Inspector [15]和Discover [23]。 这些工具可以发现堆内存的越界和释放后重用错误,并且(通常)没有误报。 据我们所知,没有一种基于二进制插桩的工具可以在堆栈(除了堆栈顶部以外)或全局变量中发现越界错误。不过这些工具还可以查找未初始化访问错误(注:这是AddressSanitizer未支持的)。
Mudflap [11]使用编译时工具,因此能够检测堆栈对象的越界访问。 但是,它不会在一个堆栈帧中的不同堆栈对象之间插Redzone,因此不会检测到所有堆栈缓冲区溢出错误。 它在复杂的C ++代码中有较高的漏报率(false positive)。
CCured [19]将检测与静态分析结合在一起(仅适用于C程序),以消除冗余的检查。 它们的插桩与非插桩库不兼容。
LBC [12]使用源到源转换,并依靠CCured消除冗余检查。 LBC仅限于C语言,并且不检测释放后重用错误。
Insure ++ [24]主要依靠编译时插桩,但也可以使用二进制插桩。它的实施细节尚未公开。
2.3 调试分配器
另一类内存错误检测器使用专用的内存分配器,不会更改其它部分的代码执行。
Electric Fenc[25],Duma [3],GuardMalloc [16]和Page Heap [18]等工具都使用CPU页保护。每个分配的区域都放入一个专用页面(或一组页面)中。被特殊分配的页(右边或/和左边)标记为不可访问。随后将访问这些页面的页面错误报告为越界错误。这些工具会占用大量内存,并且在malloc密集型应用程序上可能会非常慢(因为每个malloc至少需要一个系统调用)。而且,这些工具可能会遗漏某些类型的错误(例如,从5字节内存区域的开头读取偏移量为6的字节)。如果报告了错误,则会在错误消息中提供相应的说明。
其他一些malloc实现,包括DieHarder [22](DieHard [5] malloc的后代)和Dmalloc [2],都是在概率和/或延迟的基础上发现内存错误的。他们修改后的malloc函数在返回给用户的内存区域周围添加了redzones,并使用特殊的魔术字节填充新分配的内存,free函数也会将魔术字节写入free后的内存区。
如果程序读取了魔术字节,则判定程序进行了越界读取或或读取了未初始化的值。但是,它无法立即发现这种错误。通过正确选择魔术字节,程序可能会以可检测错误的方式地运行(DieHard [5]具有复制模式,通过比较模式,它可以检测到这种错误行为。初始化为不同魔术字节的几个程序副本的输出)。换句话说,对越界读取和释放后重用的检测是概率性的。
如果Redzone中的魔术字节被覆盖了,则后面的free函数中会检测这一情况,但该工具无法确切知道何时发生越界写入或释放后写入。 对于大型程序,它通常等效于报告“您的程序有bug”。 请注意,DieHarder的目标不仅是检测错误,而且还可以防止受到安全攻击。
两种malloc调试方法通常结合在一起。但调试malloc工具不处理堆栈或全局变量。
相同的魔术字节技术通常用于缓冲区溢出保护。 StackGuard [29]和ProPolice [14](GCC当前使用的StackGuard重新实现)在当前堆栈帧的局部变量和返回地址之间放置一个canary值,并在函数退出时检查该值的一致性。 这有助于防止堆栈破坏缓冲区溢出,但无法检测到对堆栈对象的任意越界访问。
3 地址消毒算法
从顶层角度来看,我们的内存错误检测方法与基于Valgrind的工具AddrCheck [27]相似:使用影子内存记录应用程序内存的每个字节是否可以安全访问,并在应用程序每次加载和存储内存时,使用插桩检查影子内存。 但是,AddressSanitizer使用更高效的影子内存映射,更紧凑的影子内存映射编码,除了堆内存错误之外还可以检测堆栈和全局变量中的错误,并且比AddrCheck快一个数量级。 以下各节介绍了AddressSanitizer如何编码和映射其影子内存,指令插入以及其运行时库如何运行。
3.1 影子内存
malloc函数返回的内存地址通常至少8个字节对齐。这让我们观察到应用程序堆内存的任何对齐的8字节序列处于9种不同状态之一:前k(0≤k≤8)个字节是可寻址的,而其余的8 − k个字节则不可寻址。可以使用单个字节的影子内存编码该状态。
AddressSanitizer将虚拟地址空间的八分之一专用于其影子内存,并使用具有比例和偏移量的应用程序地址转换为其对应的影子地址。给定应用程序内存地址Addr,影子字节的地址计算为(Addr >> 3)+ Offset。如果Max-1是虚拟地址空间中的最大有效地址,则应选择Offset的值,以使启动时不占用从Offset到Offset + Max / 8的区域。与Umbra [31]不同,每个平台都必须静态选择Offset,但是我们并不认为这是一个严重的限制。在虚拟地址空间为0x00000000-0xffffffff的典型32位Linux或MacOS系统上,我们使用Offset = 0x20000000(2^29)。在具有47个有效地址位的64位系统上,我们使用Offset = 0x0000100000000000(2^44)。在某些情况下(例如,在Linux上带有-fPIE / -pie编译器标志),零偏移量可用于进一步简化检测过程。

图1显示了地址空间布局。应用程序内存分为两部分(低和高),它们分别映射到相应的影子区域(8字节对齐的映射)。将影子内存区域地址映射到Bad区域中,通过页面保护标记为无法访问的(保证影子内存区域不会被程序正常部分访问)。
我们为每个影子字节使用以下编码:0表示对应的应用程序内存区的所有8个字节都是可寻址的; k(1≤k≤7)表示前k个字节是可寻址的;任何负值表示整个8字节字都是不可寻址的。我们使用不同的负值来区分不同类型的不可寻址内存(堆redzones,堆栈redzones,全局redzones,已释放redzones)。
该影子映射可以推广为(Addr >> Scale)+ Offset形式,其中Scale是1 … 7之一。在Scale = N的情况下,影子内存占用虚拟地址空间的1/2^N,并且redzones(和malloc对齐)的最小大小为2^N字节。每个影子字节描述2^N个字节的状态,并编码2^N +1个不同的值。较大的Scale值需要较少的影子内存,但需要较大的redzones才能满足对齐要求。大于3的Scale值要求对8字节访问进行更复杂的配置(请参阅第3.2节),但对于可能无法放弃其地址空间的单个连续八分之一的应用程序,则提供了更大的灵活性。
3.2 插桩
挡检测8字节内存访问时,Address- Sanitizer计算相应影子字节的地址,加载该字节,然后检查其是否为零:
1 2 3 | ShadowAddr = (Addr >> 3) + Offset;
if (*ShadowAddr != 0)
ReportAndCrash(Addr);
|
当检测1、2或4字节访问时,检测稍微复杂一些:如果影子值是正数(即,只有8字节字中的前k个字节是可寻址的),我们需要比较访问地址的后3位与访问大小是否超出k值。
1 2 3 4 | ShadowAddr = (Addr >> 3) + Offset; k = *ShadowAddr; if (k != 0 && ((Addr & 7) + AccessSize > k)) ReportAndCrash(Addr); |
在这两种情况下,对于原始代码中的每个内存访问,检测仅插入一个内存读取。我们假定N字节访问与N对齐。如第3.5节中所述,Address- Sanitizer可能会丢失由未对齐访问引起的错误。
我们将AddressSanitizer的代码插桩过程放到LLVM优化流水线中非常靠后的位置,这样我们就只会对那些经过LLVM优化器优化后残余的内存访问进行插桩,减少了不必要的插入。例如,将不会检测对通过LLVM优化的本地堆栈对象的内存访问。同时,我们不必检测由LLVM代码生成器生成的内存访问(例如,寄存器溢出)。
错误报告代码(ReportAndCrash(Addr))最多执行一次,但是已插入到代码中的许多位置,因此仍然需要保持紧凑。当前,我们使用一个简单的函数调用(请参阅附录A中的示例)。另一个选择是使用生成硬件异常的指令。
3.3 运行时库
运行时库的主要目的是管理影子内存。在应用程序启动时,将映射整个影子区域,以便该程序的其他任何部分都不能使用它。 影子内存得到保护。 在Linux上,影子内存空间在启动时始终不被占用,因此内存映射总是成功的。 在MacOS上,我们需要禁用地址空间布局随机化(ASLR)。 我们的初步实验表明,相同的影子内存布局也适用于Windows。
malloc和free函数被特殊插桩替换。 malloc函数在返回的区域周围分配额外的内存,即redzone。redzone被标记为不可寻址或poisoned。redzone越大,检测到的上溢或下溢越大。
在分配器内部,内存区域被组织为与一系列大小相对一样的free chunk数组。当与请求的chunk大小相对应的空闲列表为空时,会从操作系统中分配一大组带有redzone的内存区域(例如,使用mmap)。对于n个区域,我们分配n +1个redzone,这样一个区域的右redzone通常是另一区域的左redzone:rz1 mem1 rz2 mem2 rz3 mem3 rz4
左边redzone会用于存储分配器的内部数据(例如分配大小,线程ID等);因此,堆redzone的最小大小当前为32个字节。缓冲区下溢不会破坏此内部数据,因为此类下溢会在实际溢出之前立即检测到(如果下溢发生在检测代码中)。
free函数会对整个free内存poisoned,并将其放入隔离区,这样malloc不会很快就分配该区域。当前,隔离区被实现为FIFO队列,该队列可随时保存固定数量的内存。
默认情况下,malloc和free记录当前的调用堆栈,以提供更多有用的错误报告。 malloc调用堆栈存储在左侧的redzone中(红redzone越大,可以存储的帧数越多),而free调用堆栈存储在内存区域本身的开头。
4.3节讨论了如何调整运行时库。
3.4 栈和全局变量
为了检测对全局对象和堆栈对象的越界访问,AddressSanitizer必须在此类对象周围创建中毒的红色区域。 对于全局变量,将在编译时创建redzone,并将redzone的地址在应用程序启动时传递给运行时库。 运行时库函数使redzone poisoned(标记不可安全访问),并记录地址以进一步报告错误。 对于堆栈对象,将在运行时创建redzone并使其poisoned。 当前,使用32字节的redzone(加上最多31字节用于对齐)。 例如,给定一个程序
1 2 3 | void foo() {
char a[10];
<function body> }
|
转为为:
1 2 3 4 5 6 7 8 9 10 11 12 13 | void foo() {
char rz1[32]
char arr[10];
char rz2[32-10+32];
unsigned *shadow =
(unsigned*)(((long)rz1>>8)+Offset);
// poison the redzones around arr.
shadow[0] = 0xffffffff; // rz1
shadow[1] = 0xffff0200; // arr and rz2
shadow[2] = 0xffffffff; // rz2
<function body>
// un-poison all.
shadow[0] = shadow[1] = shadow[2] = 0; }
|
3.5 假阴性
上面描述的检测方案可能会漏掉非常罕见的错误类型:部分超出范围的未对齐访问。 例如:
1 2 3 | int *a = new int[2]; // 8-aligned int *u = (int*)((char*)a + 6); *u = 1; // Access to range [6-9] |
目前,我们忽略了这种类型的错误,因为我们提出的所有解决方案都会拖慢通用的检测路径。我们考虑的解决方案包括:
- 在运行时检查地址是否未对齐;
- 使用字节到字节的阴影映射(仅在64位系统上可行);
- 使用更紧凑的映射(例如,第3.1节中的Scale = 7)以最小化遗漏此类错误的可能性。
在以下两种情况下,AddressSanitizer可能还会遗漏错误(Valgrind或Dr. Memory等工具存在相同的问题)。 首先,如果越界访问的内存距离分配的redzone太远,它可能会落在其它的有效分配中,AddressSanitizer会漏掉该错误。
所有越界访问落到堆redzone中,会100%的概率检测到。如果内存占用不是一个严格的限制,我们建议使用最大为128个字节的大红色区域。 其次,如果在“空闲”和后续使用之间分配并释放了大量内存,则释放后重用错误可能无法被检测到。1 2 3
char *a = new char[100]; char *b = new char[1000]; a[500] = 0; // may end up somewhere in b
1 2 3 4 5 6
char *a = new char[1 << 20]; // 1MB delete [] a; // <<< "free" char *b = new char[1 << 28]; // 256MB delete [] b; // drains the quarantine queue. char *c = new char[1 << 20]; // 1MB a[0] = 0; // "use". May land in ’c’.
3.6 假阳性
简单的来说,AddressSanitizer没有误报。 但是,在AddressSanitizer的开发和部署过程中,我们看到了下面描述的许多非期望的错误报告,现在已修复了所有错误报告。
3.6.1 与Widening编译选项的冲突
一个非常常见的编译器优化(称为负载扩展)与AddressSanitizer插桩冲突。 考虑以下C代码:
1 2 3 4 | struct X { char a, b, c; };
void foo() {
X x; ...
... = x.a + x.c; }
|
在此代码中,对象x的大小为3,对齐方式为4(至少)。 负载加宽将x.a + x.c转换为一个4字节的负载,该负载部分跨越了对象边界。按照之前的栈代码插入方式,第4个字节应该是被染毒的,这样在load这4个字节时,就会报错。为避免此问题,当启用AddressSanitizer工具时,我们部分禁用了LLVM中的负载扩展。 我们仍然允许将x.a + x.b扩展为2字节的负载,因为这样的转换不会导致误报,并且会加快检测代码的速度。
3.6.2 与clone系统调用的冲突
在clone系统调用的存在下,我们已经观察到一些错误的报告。 首先,一个进程使用CLONE VM | CLONE FILES标志clone,这将创建一个与父进程共享内存的子进程。 特别是,子进程的堆栈使用的内存仍然属于父级。 然后,子进程调用一个函数,该函数在堆栈上具有对象,并且AddressSanitizer插桩poisoning堆栈对象的redzone。 最后,子进程不会退出函数且不会使redzone poisoning,而是调用永不返回的函数(例如exit或exec)。 结果,部分父地址空间仍然poisoning,并且在重新使用此内存后,AddressSanitizer会报告错误。 我们通过找到永不返回函数调用(退出或exec之类的函数具有此属性)并在调用之前un-poisoning整个堆栈内存来解决此问题。 由于类似的原因,AddressSanitizer运行时库必须拦截longjmp和C ++异常。
3.6.3 野生引用
我们已经看到了几种情况,其中函数有意读取野生内存位置。 例如,低级代码在跨越多个堆栈帧的堆栈上的两个地址之间进行迭代。 对于这些情况,我们实现了没有地址安全性分析的函数属性,应将其添加到C / C ++源代码中的函数声明中。 这些情况很少见; 例如,在Chromium浏览器中,我们只需要一次此属性。
3.6.4 线程
AddressSanitizer是线程安全的。 仅当无法访问相应的应用程序内存时(在malloc或free内部,在创建或销毁堆栈帧期间,在模块初始化期间),才修改影子内存。读取影子内存的所有其他访问,malloc和free函数使用线程本地缓存来避免每次调用都被锁定(就像大多数现代malloc实现一样)。 如果原始程序在内存访问和删除该内存之间存在竞争,则AddressSanitizer有时可能会将其检测为释放后使用的bug,但不能保证。 记录每个malloc和free的线程ID,并在错误消息中与线程创建调用堆栈一起报告线程ID。
4 评估
我们根据SPEC CPU2006 [28]的C/C ++基准,测试了AddressSanitizer的性能。测试是在2个四核Intel Xeon E5620 CPU和24GB RAM的HP Z600机器上以64位模式完成的。 我们将插桩二进制文件的性能与使用常规LLVM编译器(clang -O2)构建的二进制文件进行比较。我们使用了32字节的Redzone,在malloc和free期间禁用了堆栈unwinding,并将隔离区大小设置为零(请参见第4.3节)。

图2显示,CPU2006的平均速度降低了73%。 在perlbench和xalancbmk上看到的降幅最大(分别为2.60x和2.67x)。 这两个基准测试非常耗费内存,并且进行大量的1字节和2字节内存访问(两个基准测试都是文本处理程序)。 当仅检测写入时,我们还测量了AddressSanitizer的性能:平均速度下降了26%。 此模式可用于对性能有严格要求的环境中,以查找内存错误的子集。
在CPU2006环境中发现了三个错误:h264ref中的一个堆栈和一个全局缓冲区溢出,以及perlbench中的use-after realloc。
我们还评估了不同映射Scale和Offset值的性能(请参阅第3.1节)。大于3的Scale值代码执行速度平均会稍慢(与Scale = 3相比,从2%加速到15%减速)。 Scale = 4,5的内存占用量接近Scale = 3的内存占用量。对于值6和7,由于需要更大的redzone,因此内存占用量更大。将“偏移量”设置为零(需要-fPIE / -pie)可实现较小的加速,将CPU2006的平均速度降低到69%。

表1总结了内存使用量的增加(通过在进程终止时从/ proc / self / status中读取VmPeak字段来收集)。内存开销主要来自malloc Redzone。平均内存使用量增加了3.37倍。隔离区还有一个固定大小的开销,我们没有在实验中计算。

表2总结了堆栈大小的增加(/ proc / self / status中的VmStk字段)。只有6个基准测试的堆栈大小发生了明显变化,只有3个基准测试的堆栈大小增加了10%以上。 SPEC CPU2006的二进制大小增加范围是1.5倍至3.2倍,平均为2.5倍。
4.1 比较
将AddressSanitizer与其他工具进行比较比较棘手,因为其他工具会发现不同的错误集。 Valgrind和Dr.Memory在CPU2006上分别导致速度降低20倍和10倍[8]。但是这些工具会检测到一组不同的错误(除了越界和释放后使用,它们还会检测未初始化的读取和内存泄漏,但不会处理大多数堆栈变量和全局变量的越界)。
Mudflap可能是与Address Sanitizer最相似的工具,具有非常不寻常的性能特征。根据我们的测量,Mudflap在CPU2006上的速度降低了2倍至41倍;多个基准测试因内存不足错误而失败。
使用CPU保护页的Debug malloc通常只会使占用malloc的较多的应用程序的速度。 Duma是Linux的免费保护页实现,在18个CPU2006基准测试中有12个崩溃,并出现内存不足错误。毫不奇怪:Duma手册将其描述为“terrible memory hog”。在其余6个基准上,它的开销很小(从-1%到5%)。 DieHarder Debug malloc的开销非常低,平均为20%[22]。但是,在三个内存分配密集型基准上,它可以与AddressSanitizer的开销进行比较:perlbench,2x; omnetpp,1.85倍; xalancbmk,1.75倍。
4.2 AddressSanitizer部署
自2011年5月发布以来,Chromium开源浏览器[1]已通过AddressSanitizer进行了定期测试。在测试的前10个月中,该工具在Chromium代码和第三方库中检测到300多个未知的错误。 210个错误是堆释放后重用的错误,73个错误是堆缓冲区溢出,8个全局缓冲区溢出,7个堆栈缓冲区溢出和1个memcpy参数重叠。在另外13种情况下,Address- Sanitizer触发了其他类型的程序错误(例如,未初始化的内存读取),但未提供有意义的错误信息。
Chromium中错误报告的两个主要来源是现有单元测试的定期运行和目标随机测试生成(模糊测试)。无论哪种情况,检测代码的速度都是至关重要的。对于单元测试,高速允许使用更少的机器来跟上源代码的变化。对于模糊测试,它允许在短短的几秒钟内运行随机测试(由于AddressSanitizer被实现为编译时工具,因此没有启动代价),一旦发现错误,请在合理的时间内最小化测试。通过手动运行检测的浏览器发现了少数错误,而使用非常慢的工具则无法发现错误。
除了Chromium,我们还测试了大量其他代码,并发现了许多错误。就像在Chromium中一样,堆释放后重用是最常见的错误。但是,堆栈和全局缓冲区溢出的发生率比Chromium中的高。在LLVM本身中检测到了多个堆释放后重用。我们收到有关AddressSanitizer在Firefox,Perl,Vim和其他几个开源项目中发现的错误的通知。
4.3 调整精度和资源使用
AddressSanitizer具有三个主要徐昂行,这些选项会影响准确性和资源使用情况。
- 堆栈展开深度(默认值:30)
在每次调用malloc和free时,该工具都需要释放调用堆栈,以便错误消息包含更多信息。此选项影响工具的速度,尤其是在测试的应用程序是malloc密集型的情况下。它不会影响内存空间或错误发现能力,但较浅的堆栈跟踪通常不足以分析错误消息。 - 隔离区大小(默认值:256MB)
该值控制查找释放后使用堆的错误的能力(请参见第3.5节)。它不影响性能。 - 堆redzone的大小(默认值:128个字节
此选项影响查找堆缓冲区溢出错误的能力(请参见第3.5节)。较大的值可能会导致显着的减慢并增加内存使用量,尤其是在经过测试的程序分配许多小的堆内存块的情况下。由于redzone用于存储malloc调用堆栈,因此减小redzone会自动减小最大展开深度。
在测试Chromium时,我们使用了这三个参数的默认值。增加它们中的任何一个都不会增加发现错误的能力。在测试其他软件时,有时我们必须使用较小的redzone大小(32或64字节)和/或完全禁用堆栈展开,以满足极端的内存和速度限制。在具有少量RAM的环境中,我们使用了较小的隔离区大小。这三个值均由环境变量控制,可以在流程启动时设置。
5 未来工作
本节讨论可以使用AddressSanitizer进行的改进和进一步的计划。
5.1 实时编译的优化
不必对所有内存插桩就可以发现所有内存错误。 可以消除冗余的插桩,如以下示例所示:
1 2 | void inc(int *a) {
(*a)++; }
|
在这里,我们有两个内存访问,一个加载和一个存储,但是我们只需要检测第一个。 这是AddressSanitizer当前实现的唯一编译时优化。 下面介绍了一些其他可能的优化。 这些优化仅在某些条件下适用(例如,在第一个示例中,两次访问之间不应有非纯函数调用)。
- 仅对第一个访问进行检测:
1 2 3
*a = ... if (...) *a = ... - 仅对第二次访问进行检测(尽管这放弃了保证在实际加载或存储之前报告错误的属性):
1 2 3
if (...) *a = ... *a = ... - 仅对a[0]和a[n-1]插桩
我们已经使用这种方法来检测诸如memset,memcpy之类的函数。 如果n大,可能会遗漏一些错误。1 2
for (int i = 0; i < n; i++) a[i] = ...; - 合并两种访问
1 2 3
struct { int a, b; } x; ... x.a = ...; x.b = ...; - 不对静态就能检测的进行插桩:
1 2 3
int x[100]; for (int i = 0; i < 100; i++) x[i] = ...; - 有些全局变量的插桩无意义
1 2 3
int glob; int get_glob() { return glob; }
5.2 库处理
AddressSanitizer的当前实现基于编译时工具,因此不处理系统库(但是可以处理某些C库函数,例如memset)。 对于开源库,最好的方法可能是创建特殊的工具版本。 对于闭源库,可以使用静态/动态组合的方法。 所有可用的源代码都可以使用启用了AddressSanitizer的编译器来构建。 然后,在执行过程中,可以使用二进制翻译系统(例如DynamoRIO [7,6])对闭源库进行检测。
可以仅使用运行时工具来实现AddressSanitizer,但是由于二进制翻译开销(包括次优的寄存器分配),它可能会变慢。 此外,尚不清楚如何使用运行时检测为堆栈对象实现重分区。
5.3 硬件支持
AddressSanitizer的性能特点适应于多数情况。但是,对大小很敏感的应用程序,当前的开销可能会过于严格。 AddressSanitizer执行的检测(请参见第3.2节)可以由单个新的硬件指令checkN(例如,用于4字节访问的“ check4 Addr”)代替。参数Addr的checkN指令应等效于
1 2 3 4 | ShadowAddr =(Addr >> Scale)+ Offset;
k = * ShadowAddr;
if(k!= 0 &&((Addr&7)+ N> k)
GenerateException();
|
Offset和Scale的值可以存储在特殊的寄存器中,并在应用程序启动时进行设置。
这样的指令将通过减少icache压力来提高性能,结合简单的算术运算,并获得更好的分支预测,这也将显着减小二进制大小。
默认情况下,checkN指令可以是无操作且只能由特殊的CPU标志启用,从而可以选择性地测试某些执行甚至只测试寿命很长的进程的执行时间的一小部分。
6 结论
在本文中,我们介绍了一种快速内存错误检测器AddressSanitizer。 AddressSanitizer查找越界(对于堆,堆栈和全局变量)访问和释放后重用的错误,平均速度降低了73%;该工具没有误报。
AddressSanitizer使用影子内存来提供准确和立即的错误检测。传统观点认为,影子内存会通过多级映射方案产生高开销,或者通过占用较大的连续内存而强加了过高的地址空间要求。我们新颖的影子状态编码可减少影子空间占用,让我们可以使用简单的映射(可以以较低的开销实现)。
该工具提供的高速度使用户可以更快地运行更多测试。该工具已用于测试Chromium浏览器,并在短短10个月内发现了300多个实际错误,其中包括一些可能导致安全漏洞的错误。AddressSanitizer用户在Firefox,Perl,Vim和LLVM中发现了错误。
AddressSanitizer所需的插桩非常简单,可以在各种编译器,二进制插桩系统甚至硬件中实现。
作者声明
本文版权归作者(rohex)所有,旨在技术交流使用。未经作者同意禁止转载,转载后需在文章页面明显位置给出原文连接,否则相关责任自行承担。
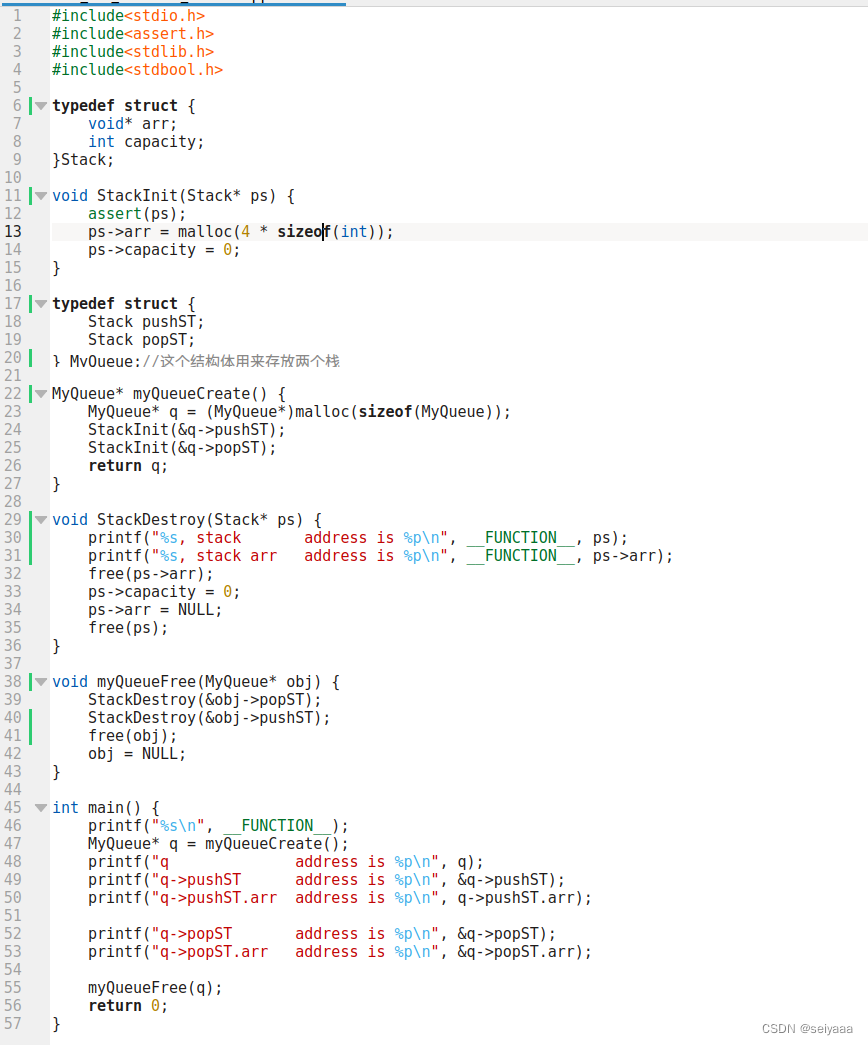
实践代码:
传图片了,建议手动尝试下

数据结构如下图,还不清晰可以看下面的打印



旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)