解决Selenium弹出新页面无法定位元素问题(Unable to locate element)
Python 2.7
IDE Pycharm 5.0.3
环境细节详见Python+Selenium+PIL+Tesseract真正自动识别验证码进行一键登录
对于同一页面无法定位元素问题请见姊妹篇解决网页元素无法定位(NoSuchElementException: Unable to locate element)的几种方法
只解决一个问题--NoSuchElementException: Message: Unable to locate element
问题来源
在上一篇博客中,我进行了自动化登录,之后我想直接进行对图书的续约操作,但是利用元素定位的方法,怎么都找不到元素,我一直以为是我的规则用的不对,导致元素找不到,其实,只是窗口句柄还停留在上一个页面而已!对于新弹出的页面还没有定位!!!那怎么可能找得到在新页面的元素呢!!这是新手(我)犯下最大的错误,只顾于对元素方法的定位,却没有意识到页面发生跳转后的handles的变化。
解决方案
窗口重定位,感谢@一朵菊花向阳开——python + selenium webdriver 从主窗口A跳转至主窗口B后,无法定位窗口B的元素的问题 让我找到解决方案,最终得以实现句柄的重定位!
(这段可跳过,因为百度太不稳定了,测试结果有差别) 
但话说到这的时候,我很疑惑一篇文章 python+selenuim webdriver 页面跳转后如何定位元素,他的方法我进行测试时不可行的,请看测试;
他的代码:我一行没动进行测试
#coding=utf-8
from selenium import webdriver
import time
browser=webdriver.Firefox()
browser.get("http://www.baidu.com")
browser.find_element_by_id("kw").send_keys("selenium")
browser.find_element_by_id("su").click()
time.sleep(3)
sreach_window=browser.current_window_handle //此行代码用来定位当前页面
browser.find_element_by_xpath("/html/body/div[3]/div[4]/div/div[3]/div[4]/h3/a").click()
time.sleep(5)
当然如果我一点都不改,也是进行不了测试的,这位大哥把注释符号写错了,不是//,而是#啊大哥
ok,然后运行下:出错了 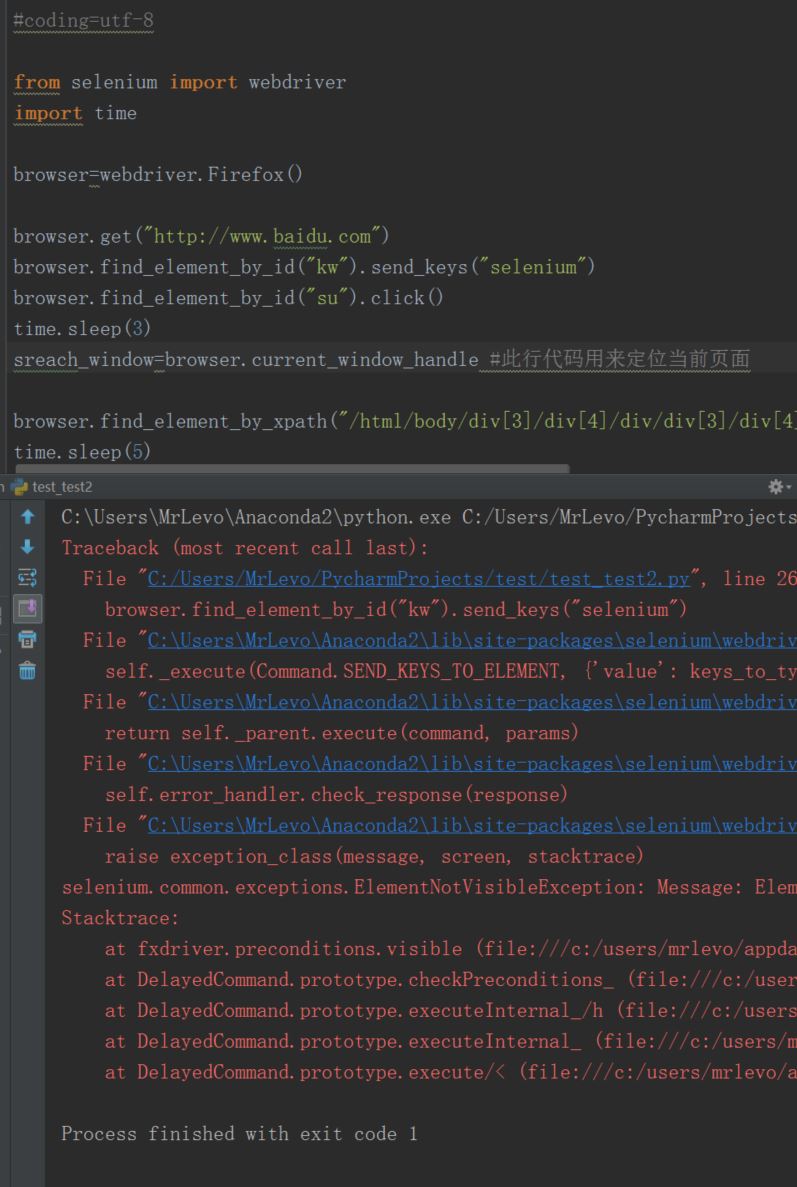
所以我感到好奇的是,这位大哥到底有没有跑过这段代码,看着原创的样子应该没有抄袭才对啊,那应该是测试过代码才对,但是可重复性在哪?最后发现需要修改http成这样才能访问(大哥少加个/): browser.get("https://www.baidu.com/")修改后代码如下:
#coding=utf-8
from selenium import webdriver
import time
browser=webdriver.Firefox()
browser.get("https://www.baidu.com/")
browser.find_element_by_id("kw").send_keys("selenium")
browser.find_element_by_id("su").click()
time.sleep(1)
sreach_window=browser.current_window_handle #此行代码用来定位当前页面
time.sleep(2)
browser.find_element_by_xpath("/html/body/div[3]/div[3]/div/div[3]/div[4]/h3/a").click()#我这里修改了一下div[4],大哥的索引直接到有道翻译了,不利于下一步测试
time.sleep(1)ok,这次能正常索引到值,但是!!!我要说的是但是!!!
这根本没有跳转页面!还是在同一个页面进行操作的!如果我把大哥的代码改成:
在我测试的时候,发生了奇怪的事情,同样的代码,有时候能跑有时候抛出错误,我已设定休眠时间,难道是我频繁访问导致百度封我?刚才上述的代码我都实际测试过的,但是现在又不能用了–wtf–,所以。我换了稳定的引擎,我采用bing搜索来试试,上面的全部作废,如果有人知道问题出在哪,请留言

7.19补充
应该是搜索引擎热点的问题,每次键入相同的值可能搜索结果首项会不一致的,百度可能更新热点比较快把,所以出现了我所谓不稳定的情况
正题测试

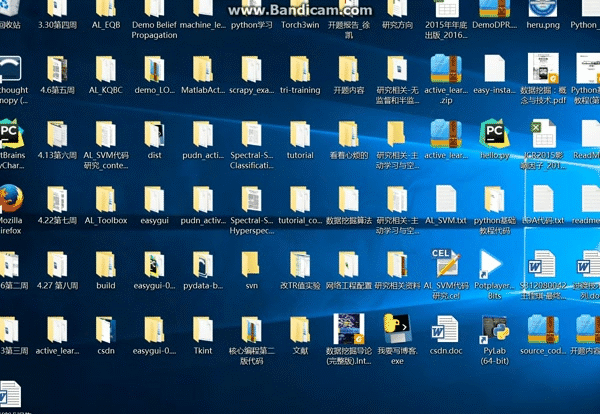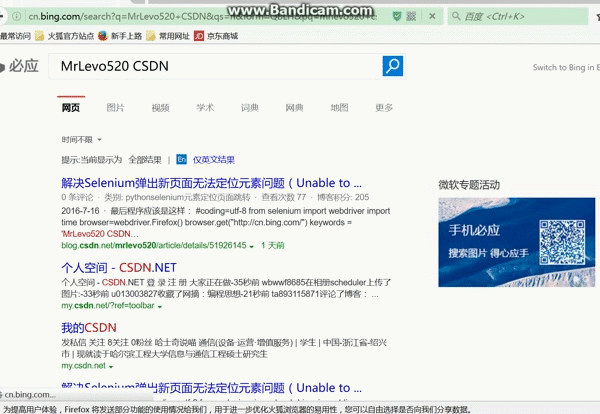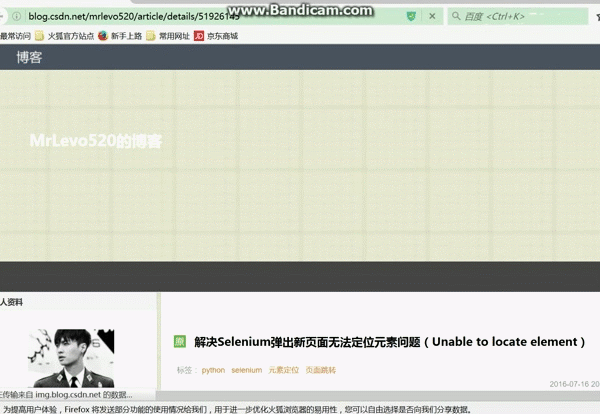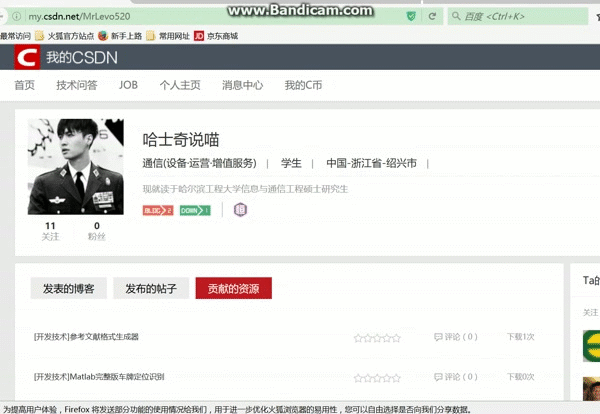
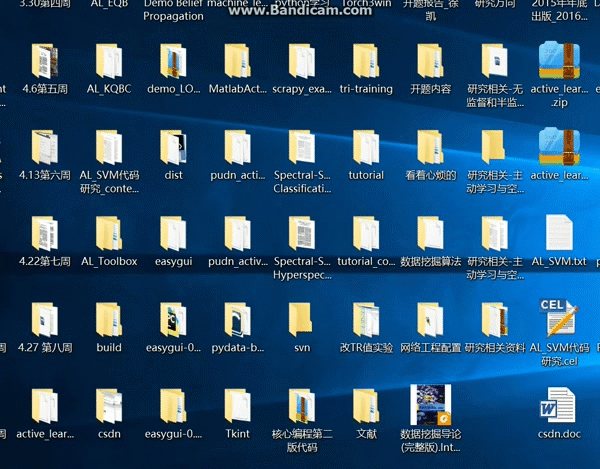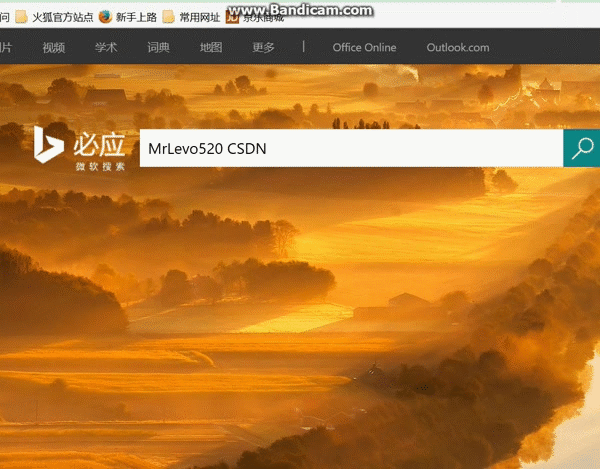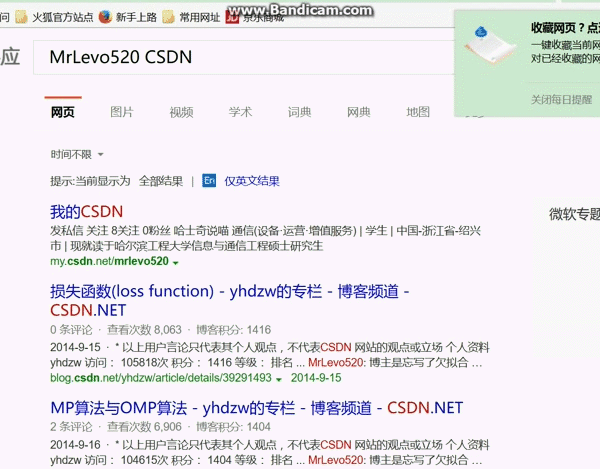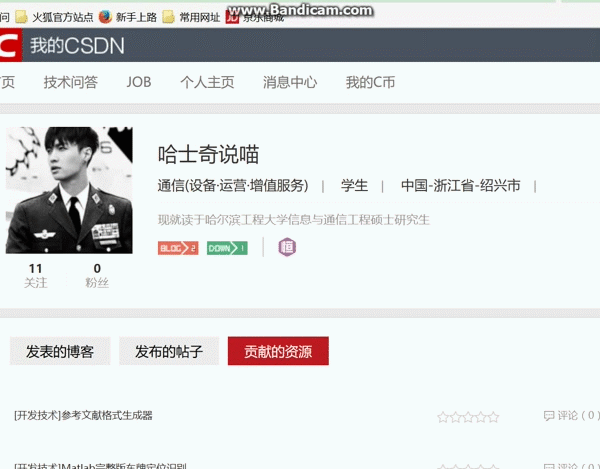
我和上述那位大哥不同的观点在于,他用的sreach_window=browser.current_window_handle方法并不能实现对新窗口句柄的捕捉,我以bing主页为测试页,重新构造了一下,
#coding=utf-8
from selenium import webdriver
import time
browser=webdriver.Firefox()
browser.get("http://cn.bing.com/")
keywords = 'MrLevo520 CSDN'
send_keywords=keywords.decode('utf-8')#中英混输入可防止乱码
browser.find_element_by_id("sb_form_q").send_keys(send_keywords)
time.sleep(1)
#----------操作一:进行对关键字MrLevo520 CSDN搜索----------------
browser.find_element_by_id("sb_form_go").click()#执行此操作会进行搜索,但是没有弹出新窗口,所以句柄不用重定位
time.sleep(3)
#----------操作二:对搜索页面"我的CSDN"进行点击操作--------------
browser.find_element_by_xpath("/html/body/div/ol/li/h2/a").click()#进行当前页面点击第一项
#--------操作三:对新弹出的页面再点击"贡献的资源"选项-----
sreach_window=browser.current_window_handle
browser.find_element_by_xpath("/html/body/div[3]/div[2]/div[2]/div/a[3]").click()
time.sleep(5)浏览器运行结果只到如图:
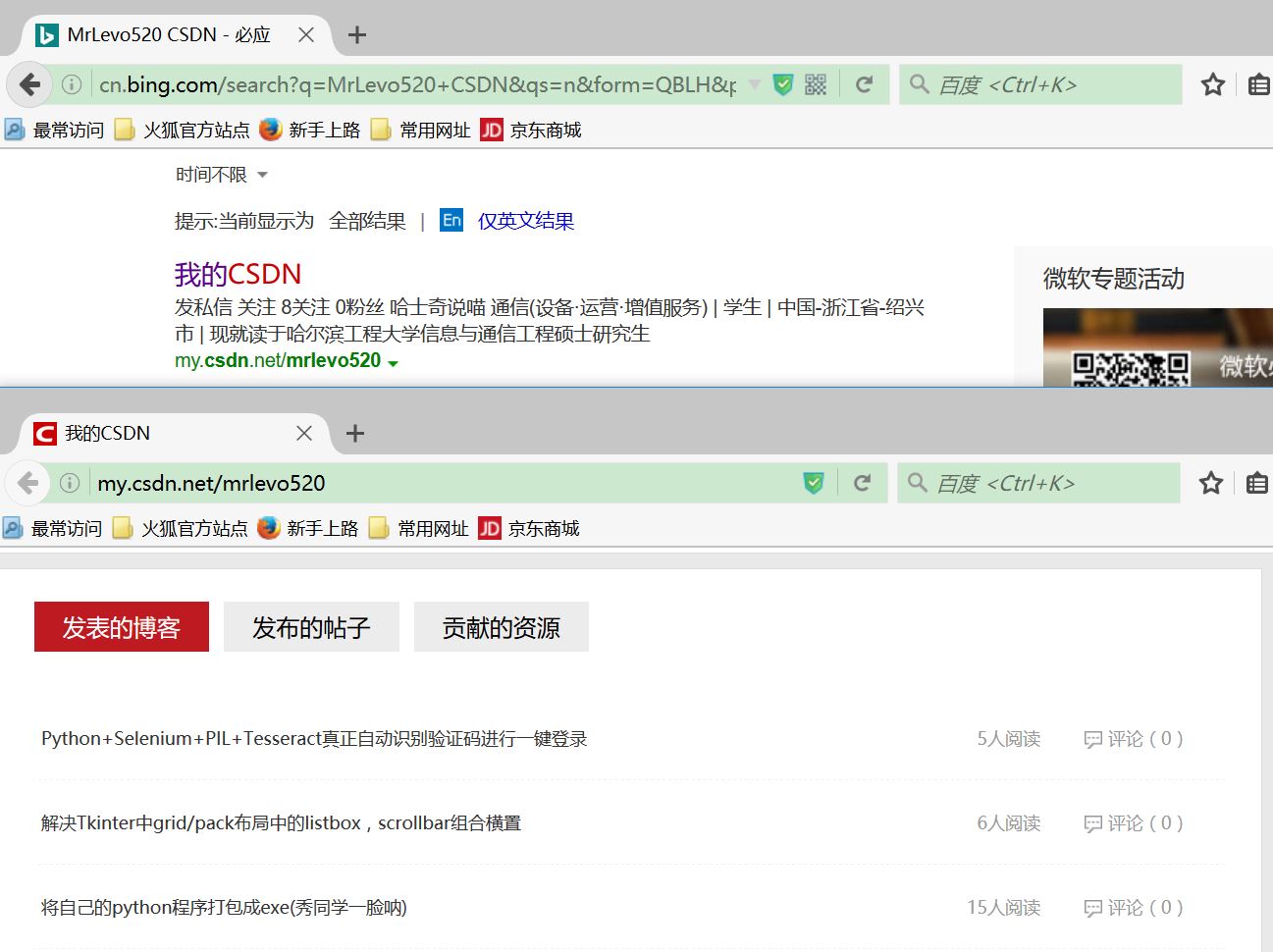
而且抛出错误:
selenium.common.exceptions.NoSuchElementException: Message: Unable to locate element: {"method":"xpath","selector":"/html/body/div[3]/div[2]/div[2]/div/a[3]"}
可见,此语句并没有实现句柄重定位的功能,然后我再试试下面的方法,所有语句不变,只改变获取当前句柄的语句,改成
browser.switch_to_window(browser.window_handles[1])最后程序应该是这样:
#coding=utf-8
from selenium import webdriver
import time
browser=webdriver.Firefox()
browser.get("http://cn.bing.com/")
keywords = 'MrLevo520 CSDN'
send_keywords=keywords.decode('utf-8')#中英混输入可防止乱码
browser.find_element_by_id("sb_form_q").send_keys(send_keywords)
time.sleep(1)
#----------操作一:进行对关键字MrLevo520 CSDN搜索----------------
browser.find_element_by_id("sb_form_go").click()#执行此操作会进行搜索,但是没有弹出新窗口,所以句柄不用重定位
time.sleep(3)
#----------操作二:对搜索页面"我的CSDN"进行点击操作--------------
browser.find_element_by_xpath("/html/body/div/ol/li/h2/a").click()#进行当前页面点击第一项
#--------操作三:对新弹出的页面再点击"贡献的资源"选项-----
browser.switch_to_window(browser.window_handles[1])
browser.find_element_by_xpath("/html/body/div[3]/div[2]/div[2]/div/a[3]").click()
time.sleep(5)最后结果,按照我的思路,进行了相应的点击,最后如图
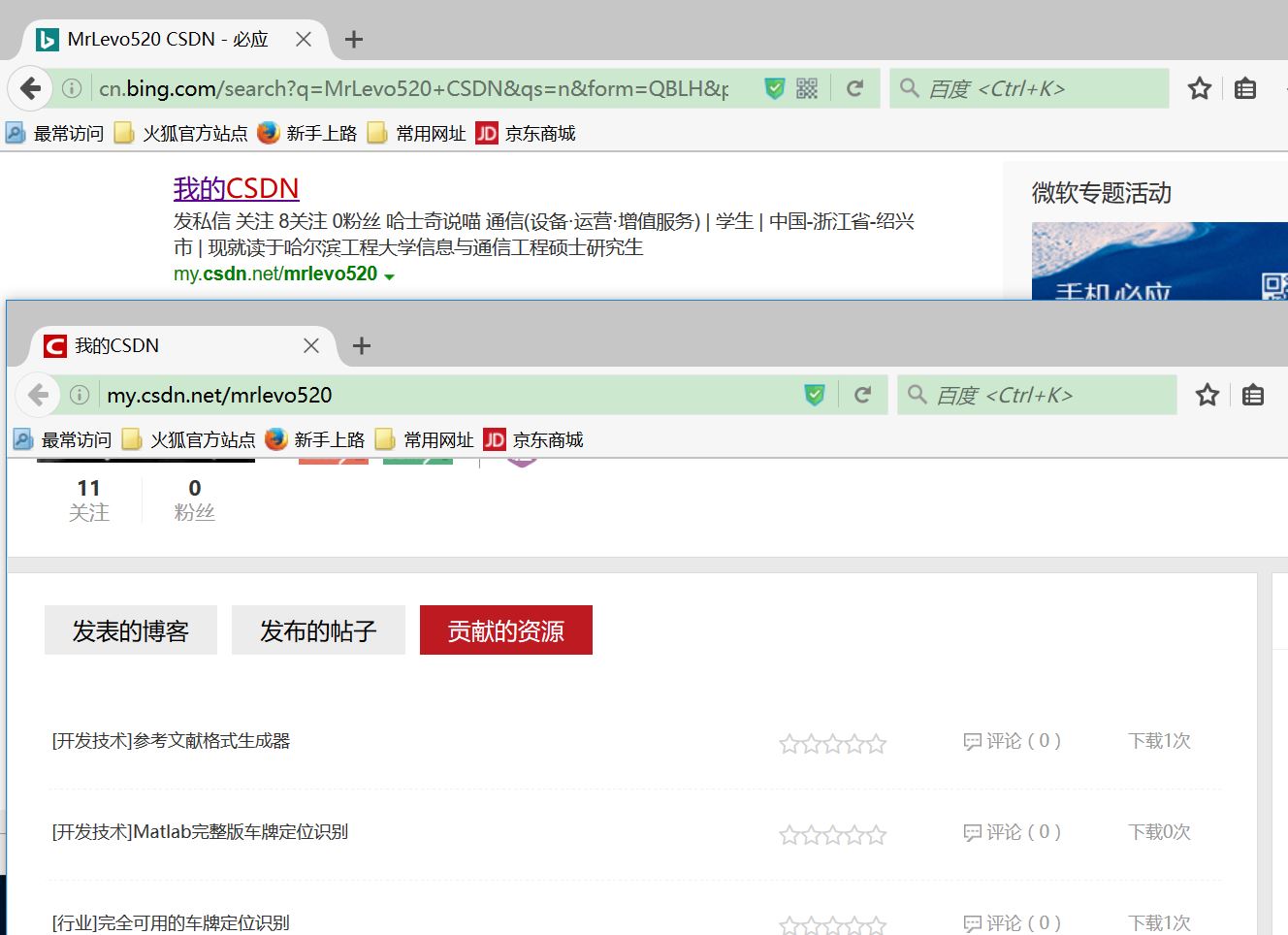
所以从上述的例子上来说,语句sreach_window=browser.current_window_handle并没有实现重定位,可能我才疏学浅,但至少,在上述的那位大哥的博客中,写的是错误的,运行失败,我对2016.7.16的所有数据负责,实际测试失败。
7.17-补充:另一种获取句柄方法
还有另一种方法,就是直接定位当前最新弹出的窗口。代码是这样的
for handle in browser.window_handles:#方法二,始终获得当前最后的窗口,所以多要多次使用
browser.switch_to_window(handle)那么结合到我的代码中那就是这样的:
#Author:哈士奇说喵
#因为搜索引擎检索项根据热度来排名,所以我只能对7.17的数据进行测试和负责,大家测试时候注意元素变化
#coding=utf-8
from selenium import webdriver
import time
browser=webdriver.Firefox()
browser.get("http://cn.bing.com/")
keywords = 'MrLevo520 CSDN'
send_keywords=keywords.decode('utf-8')#中英混输入可防止乱码
browser.find_element_by_id("sb_form_q").send_keys(send_keywords)
time.sleep(1)
#----------操作一:进行对关键字MrLevo520 CSDN搜索----------------
browser.find_element_by_id("sb_form_go").click()#执行此操作会进行搜索,但是没有弹出新窗口,所以句柄不用重定位
time.sleep(3)
#----------操作二:对搜索页面第一项进行点击操作--------------
browser.find_element_by_xpath("/html/body/div/ol/li/h2/a").click()#进行当前页面点击第一项
#--------操作三:对新弹出的页面再点击"我的头像"选项-----
#注意此时已经是弹出的第一个窗口了,需要重新定位句柄
'''browser.switch_to_window(browser.window_handles[1])#方法一'''
for handle in browser.window_handles:#方法二,始终获得当前最后的窗口
browser.switch_to_window(handle)
browser.find_element_by_xpath("//div[@id='body']/div[2]/div/div/ul[2]/div/a").click()
#------------------操作四:点击"贡献的资源"-------------------
#注意此时已经是新弹出的第二个窗口了,需要重新定位句柄
browser.switch_to_window(browser.window_handles[2])#方法一,注意window_handles[2]变成了2
'''for handle in browser.window_handles:#方法二,始终获得当前最后的窗口
browser.switch_to_window(handle)'''
browser.find_element_by_xpath("/html/body/div[3]/div[2]/div[2]/div/a[3]").click()
time.sleep(5)上面的代码,我要说几点,总共实现完成会存在三个浏览器窗口,也就是相当于实现了两次句柄重定位功能,也就是下面的图片,对bing搜索“MrLevo520 CSDN”跳出的最热项,也就是这一篇(感谢大家厚爱),但是昨天最热弹出来的是直接是我的主页,大家从上面的动图应该也可以看出来,所以等你测试这段代码的时候,可能最热项目又变化了,道理大家懂就ok,不影响重抓句柄代码。
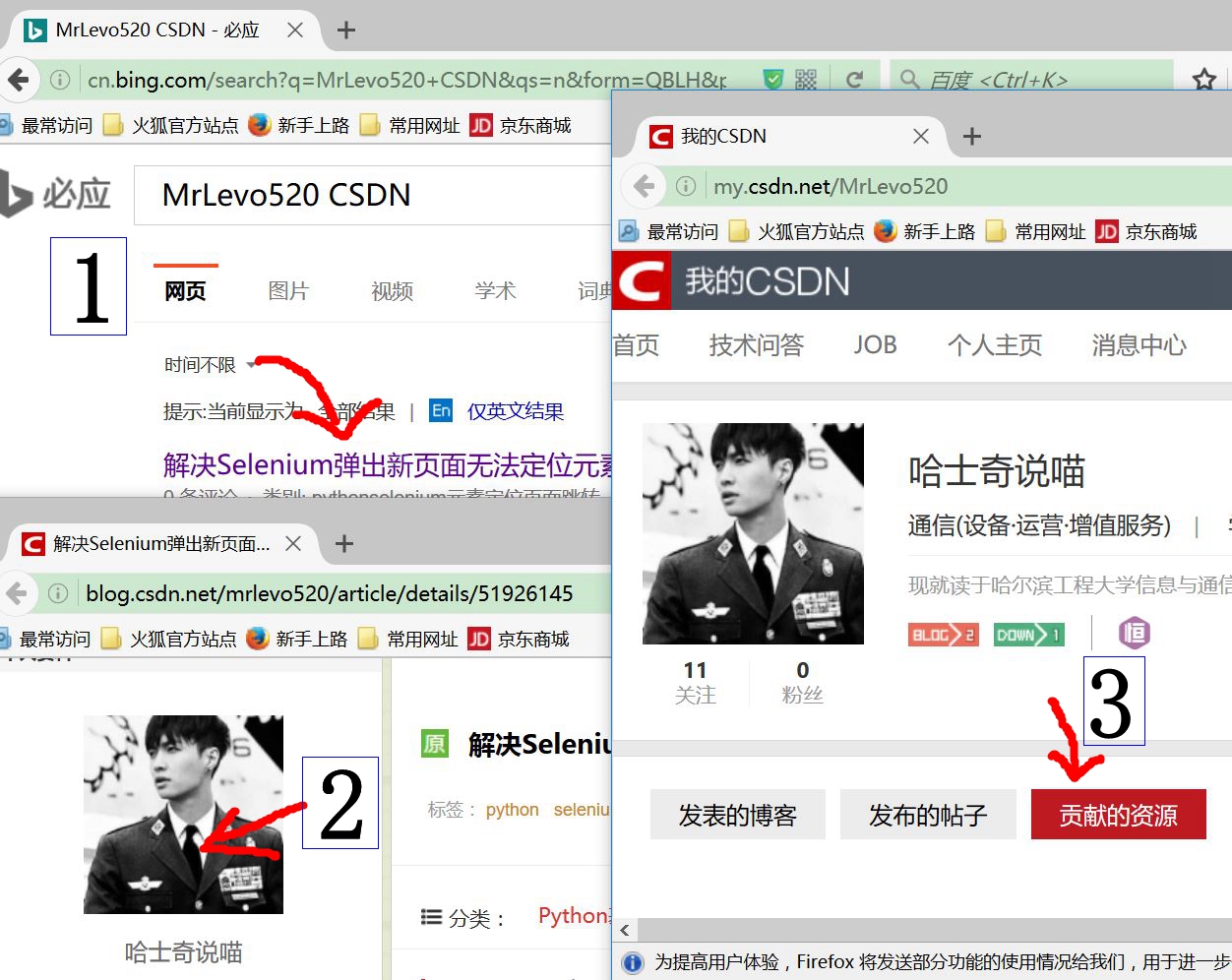
代码实现了从1,到2,点击头像后,再跳转到3主页,之后再点击”贡献资源”,实现的动图如下:
Pay Attention
1.搜索引擎根据热度来排名,也就是代码具有”不稳定性”,应该根据自己实际情况,定位不同元素,我只对当前编辑时间的数据负责
2.在实际操作过程中,会产生第一个页面还没等第二个页面缓冲完,直接又”占领”主视觉的问题,别担心,句柄还是在传递的,程序一直在跑,而且没有出错,过一会时间就会更新加载页面的,如果想要关闭无关页面,请看这篇博客 基于Selenium一键写CSDN博客
3.可能我的代码第一次获取句柄和第二次获取句柄不一样的方法,这是为了展示,你可以两次句柄获取都用方法二,也可以都是用方法一,但是方法一注意修改标号。
方法一 VS 方法二
相比较于方法二,方法一的优点在于后续操作,比如关闭第几个窗口,句柄传递是按照顺序来的。缺点在于对于较多新页面,有时候弹出窗口太多会变得难以计算。
而方法二,一直在获取最后的窗口,如果你只是对最后的窗口进行操作,也就是(自己定义的)”前向“操作时,不计后果,可以直接拿来用,而且代码不变。缺点在于,如果要返回到某个窗口句柄,那就显得没有方法一来的好,至少我现在是这么认为的,可能以后我会回来修改。
总结
我姑且认为这句语句,单独作用于上述博客中是不可行的。
所以我在后续的博客中对窗口重定向语句改成了browser.switch_to_window(browser.window_handles[1]),至少在我的实验中,这句语句实现了我需要的操作。
最后上张动图表示流程:
最后
虽然我才疏学浅,有时候还会有点错误,但是,我写的很认真,所以请@第七城市转载时候能转载全了,格式我看着惨不忍睹,真的,能不能转的问题你已经写上作者和出处了,所以没关系,但是,请也认真对待我的博客,谢谢。比如下图,我看着都蛋疼、、、 
这种格式和形式,我真的要吐了。。。。。

还有就是,辛辛苦苦写的原创,连个作者和来源都没有,我表示很受伤,更让我受伤的是,,,阅读量是我原创的6倍!!必须大写加粗

能让更多人看到自己写的东西,和帮助更多的人,我还是很开心的。。。所以我也就不计较了。。。。。。
so ,see you guys,have a good night!
致谢
@一朵菊花向阳开–python + selenium webdriver 从主窗口A跳转至主窗口B后,无法定位窗口B的元素的问题
@Do it Yourself–python+selenuim webdriver 页面跳转后如何定位元素
@崔庆才–Python爬虫利器五之Selenium的用法
原文链接

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 56
56 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)