欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
一项目简介
一、项目背景与意义
肺部CT图像分割是医学影像诊断中的一个重要步骤,主要目的是将图像中的肺部区域和非肺部区域进行准确分离。这对于医生进行病情诊断、病灶识别以及后续治疗方案的制定具有重要意义。然而,传统的肺部CT图像分割方法往往需要医生耗费大量的时间和精力,因此,自动分割算法在医学领域中具有广阔的应用前景。基于Python+OpenCV的肺部CT图像分割项目,旨在利用Python编程语言的灵活性和OpenCV库的强大图像处理能力,实现一个高效、准确的肺部CT图像自动分割系统[1][2][5][6]。
二、技术实现
图像预处理:
读取CT图像数据,并进行必要的预处理操作,如去噪、对比度增强等,以提高图像质量,便于后续分割处理[1]。
图像分割算法选择:
根据肺部CT图像的特点和分割需求,选择合适的图像分割算法。常见的肺部CT图像分割方法有基于阈值分割、基于边缘检测、基于区域生长、基于图像分割模型等[5]。
基于阈值分割的方法,如大津阈值法(Otsu法),通过设定合适的阈值,将像素值大于或小于阈值的像素划分到不同的区域中,实现肺部区域的初步分割[2]。
基于边缘检测的方法,如Sobel算子、Canny算子等,通过检测图像中的边缘信息,将肺部和胸腔的边缘进行分割[5]。
基于区域生长的方法,从某一种种子点出发,不断扩大区域,直到周围像素的灰度值和它的像素值差异不大为止,从而将肺部区域生长出来[5]。
基于图像分割模型的方法,如ACWE模型、level set模型等,通过建立数学模型,并通过优化算法来进行分割[5]。
后处理与优化:
对分割出的肺部区域进行后处理,如去除背景、噪声、气管等非肺部区域,以提高分割的准确性和完整性[2]。
利用形态学操作,如膨胀、腐蚀、开运算、闭运算等,对肺部轮廓进行平滑和细化,填补凹陷瑕疵等[2]。
结果展示与评估:
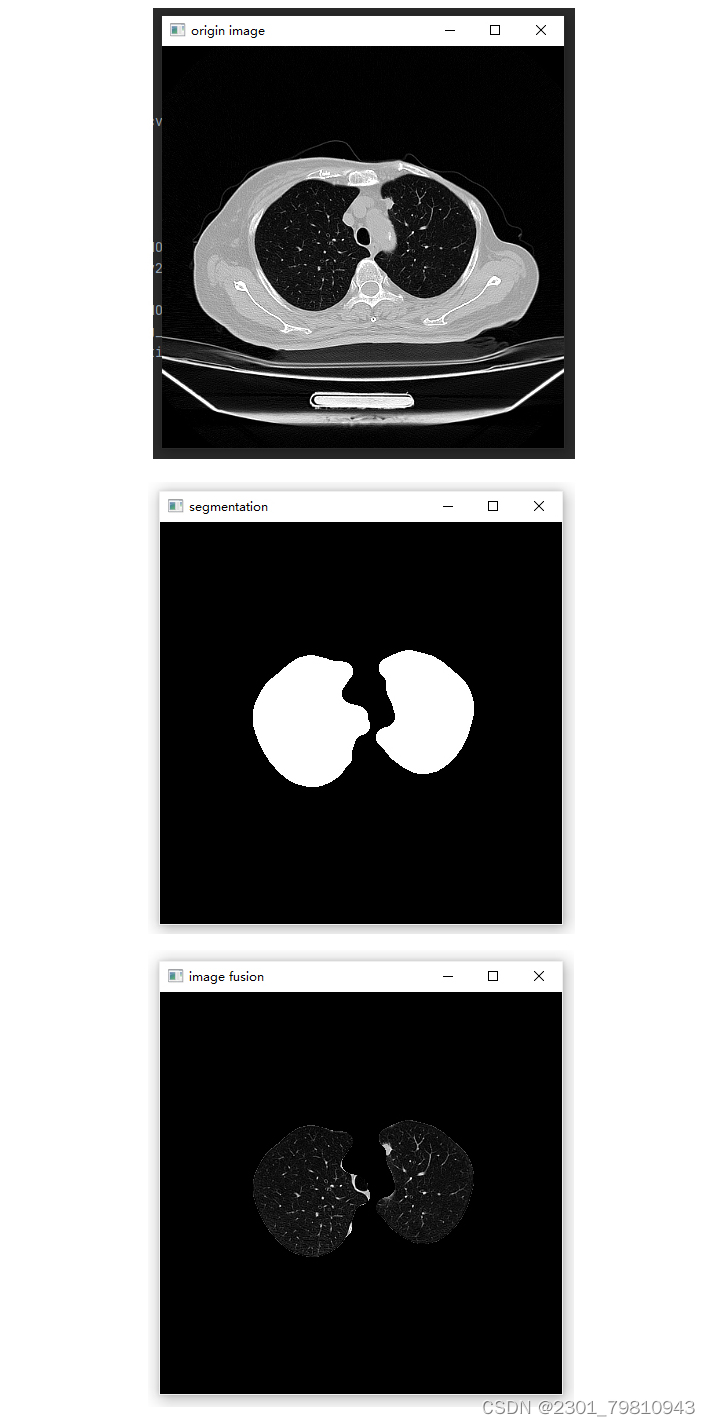
将分割后的肺部区域在原图像上进行标注和显示,方便用户观察和评估分割效果[2]。
使用定性和定量的评估指标对分割结果进行评估,如重叠率、准确率、召回率等,以验证分割算法的性能和效果[1]。
三、项目特点与优势
准确性高:采用多种图像分割算法和后处理技术,能够准确地从CT图像中分割出肺部区域,提高诊断的准确性和可靠性[2]。
自动化程度高:实现了肺部CT图像的自动分割,减轻了医生的工作负担,提高了诊断效率[6]。
灵活性好:项目采用模块化设计,可以方便地添加其他图像处理功能或改进分割算法,以适应不同的应用需求[1]。
二、功能
基于Python+OpenCV肺部CT图像分割
三、系统

四. 总结
基于Python+OpenCV的肺部CT图像分割系统可以广泛应用于医学影像诊断、计算机辅助诊断、肺部疾病研究等领域。它可以帮助医生快速、准确地识别和定位肺部病灶,为后续的病情诊断和治疗方案制定提供重要支持[1][5]。同时,该系统还可以作为教学和研究工具,用于医学图像处理和计算机视觉领域的教学和研究工作[3]。
OpenCV: 开源计算机视觉库
最近提交(Master分支:3 个月前 )
d9a139f9
Animated WebP Support #25608
related issues #24855 #22569
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [ ] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [ ] The feature is well documented and sample code can be built with the project CMake
1 天前
09030615
V4l default image size #25500
Added ability to set default image width and height for V4L capture. This is required for cameras that does not support 640x480 resolution because otherwise V4L capture cannot be opened and failed with "Pixel format of incoming image is unsupported by OpenCV" and then with "can't open camera by index" message. Because of the videoio architecture it is not possible to insert actions between CvCaptureCAM_V4L::CvCaptureCAM_V4L and CvCaptureCAM_V4L::open so the only way I found is to use environment variables to preselect the resolution.
Related bug report is [#25499](https://github.com/opencv/opencv/issues/25499)
Maybe (but not confirmed) this is also related to [#24551](https://github.com/opencv/opencv/issues/24551)
This fix was made and verified in my local environment: capture board AVMATRIX VC42, Ubuntu 20, NVidia Jetson Orin.
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [X] I agree to contribute to the project under Apache 2 License.
- [X] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [X] The PR is proposed to the proper branch
- [X] There is a reference to the original bug report and related work
- [ ] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [ ] The feature is well documented and sample code can be built with the project CMake
1 天前


 12
12 0
0


 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)