
Druid连接池的能力介绍与使用方法
Druid连接池的能力介绍与使用方法
本文将介绍druid连接池的能力:监控sql调用数据(慢sql、调用量、异常堆栈)、防止sql注入和数据库密码加密。
新增springboot项目常见的druid连接池使用的代码demo,真香!
1. Druid连接池简介
Alibaba Druid官网使用手册里是这样介绍的:Druid连接池是阿里巴巴开源的数据库连接池项目。Druid连接池为监控而生,内置强大的监控功能,监控特性不影响性能。功能强大,能防SQL注入,内置Loging能诊断Hack应用行为。
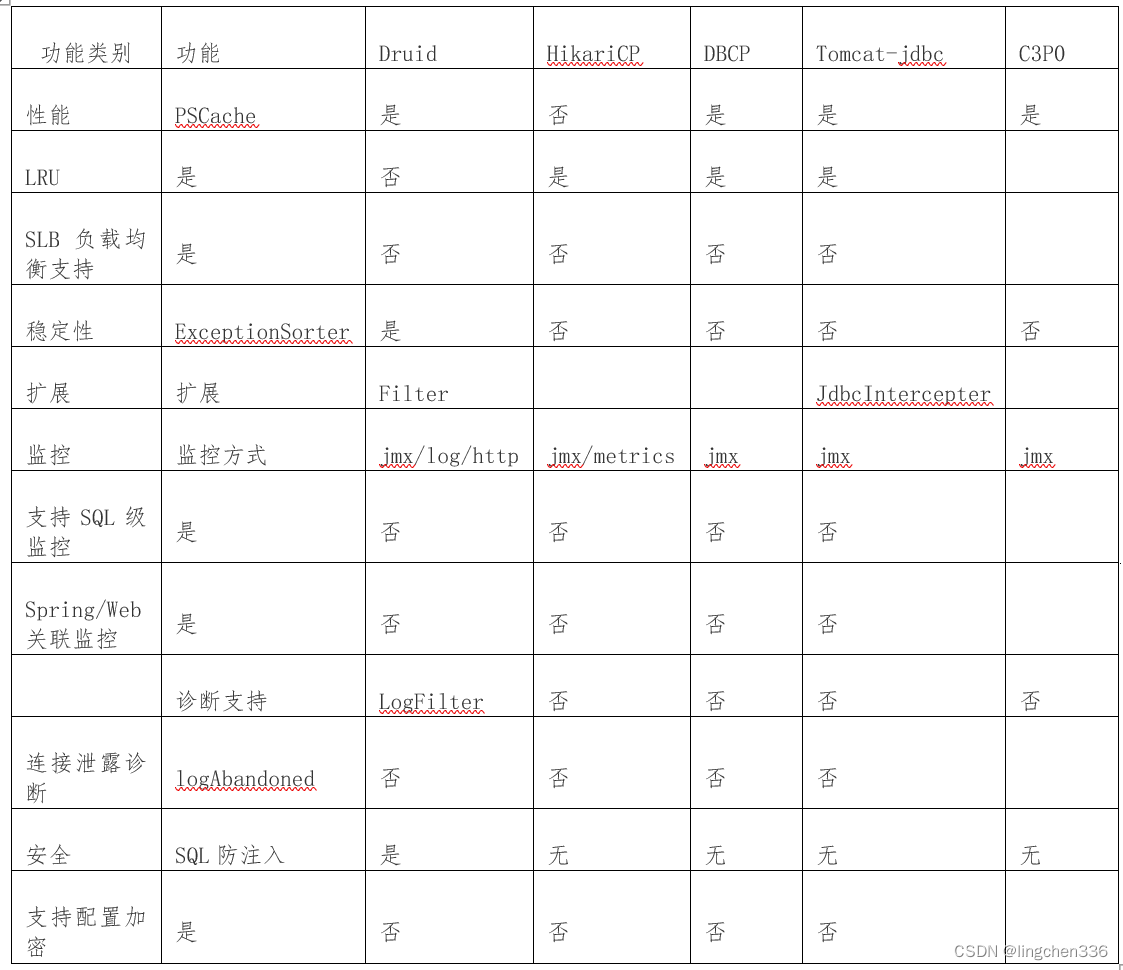
如果你是Java程序员,你在大多数项目中应该都见到过使用Druid作为数据库连接池,无他,阿里巴巴出品,质量有保证。当然这是玩笑,我们程序员选择技术组件时严谨的,下表是Druid连接池和其它连接池的对比,从此表可以看出,Druid连接池在性能、监控、诊断、安全、扩展性这些方面远远超出竞品。这些强大的能力才是Druid连接池被众多Java程序员青睐的根本原因。
2. 为监控而生
Druid连接池最初就是为监控系统采集jdbc运行信息而生的,它内置了StatFilter 功能,能采集非常完备的连接池执行信息Druid连接池内置了能和Spring/Servlet关联监控的实现,使得监控Web应用特别方便Druid连接池内置了一个监控页面,提供了非常完备的监控信息,可以快速诊断系统的瓶颈。
2.1 监控信息采集的StatFilter
Druid连接池的监控信息主要是通过StatFilter 采集的,采集的信息非常全面,包括SQL执行、并发、慢查、执行时间区间分布等。这些都可以通过配置的方式实现,如通过增加JVM的参数配置实现sql合并:-Ddruid.stat.mergeSql=true,开启后可默认实现多种sql优化策略;在yml配置文件里增加slowSqlMillis参数,可用于控制慢sql记录检测的超时时间。
2.2监控不影响性能
Druid增加StatFilter之后,能采集大量统计信息,同时对性能基本没有影响。StatFilter对CPU和内存的消耗都极小,对系统的影响可以忽略不计。监控不影响性能是Druid连接池的重要特性。
2.3 SQL参数化合并监控
实际业务中,如果SQL不是走PreparedStatement,SQL没有参数化,这时SQL需要参数化合并监控才能真实反映业务情况。如下SQL:
select * from t where id = 1
select * from t where id = 2
select * from t where id = 3
参数化后:
select * from t where id = ?
参数化合并监控是基于SQL Parser语法解析实现的,是Druid连接池独一无二的功能。
2.4 执行次数、返回行数、更新行数和并发监控
StatFilter能采集到每个SQL的执行次数、返回行数总和、更新行数总和、执行中次数和和最大并发。并发监控的统计是在SQL执行开始对计数器加一,结束后对计数器减一实现的。可以采集到每个SQL的当前并发和采集期间的最大并发。
2.5 慢查监控
缺省执行耗时超过3秒的被认为是慢查,统计项中有包括每个SQL的最后发生的慢查的耗时和发生时的参数。
2.6 Exception监控
如果SQL执行时抛出了Exception,SQL统计项上会Exception有最后的发生时间、堆栈和Message,根据这些信息可以很容易定位错误原因。
3. 防SQL注入
SQL注入攻击是黑客对数据库进行攻击的常用手段,Druid连接池内置了WallFilter 提供防SQL注入功能,在不影响性能的同时防御SQL注入攻击。
3.1 基于语意的防SQL注入
Druid连接池内置了一个功能完备的SQL Parser,能够完整解析mysql、sql server、oracle、postgresql的语法,通过语意分析能够精确识别SQL注入攻击。
检测逻辑
3.1.1只允许基本的crud命令(增删改查)
通过配置noneBaseStatementAllow参数,设置是否允许非基本语句的其他语句,缺省关闭。通过这个选项就能够屏蔽诸如CREATE、DROP、ALERT等可能存在严重危害的DDL语言。

3.1.2.禁止访问系统级表
出于权限控制的需要,Druid对于系统表的操作进行了详细的限制,给予用户充分的自定义空间。举例:
select * from information_schema.columns;
该操作不存在注入点,只是对系统表进行简单查询,所以是被允许的。
但是如果是:
select id from admin where id = 1 and 5 = 6 union select concat(id, name, score) from (select column_name from information_schema.columns where table_name = class1)
因为SQL在子语句中使用了union进行了concat拼接,拼接之后连接了系统表进行查询。Druid在sql parser解析后,判断information_schema在层次中的位置,如果它的父节点为SQL表达式(select等)、左节点为"from",就会满足子句拼接的条件,从而被认为具有攻击性。
3.1.3.禁止访问系统变量
Druid同样也是通过配置策略的方式限制用户对于系统敏感变量的访问,代码与系统表的限制类似,正常的针对version、basedir的查询不会报错,但是:
select * from database where id=‘1’ and len(@@version)>0 and ‘1’=‘1’
上文的语句中使用逻辑表达式,尝试探测版本信息。因为@@version的内容在where或having之后,所以会被禁止。
3.1.4.禁止访问系统函数
和系统敏感的表、变量一样,Druid冶金用了诸如sleep等危险的系统函数的使用,最新的Druid在mysql中摒弃了黑名单的做法,采用白名单的方式限制函数的使用,其他数据库仍旧使用黑名单。
select * from ((select sleep(0))a);
会被禁止,因为显而易见的sleep函数出现在了可能存在注入点的位置(from的子节点)。
3.1.5.禁止出现注释
通常的业务SQl语句不会带有注释,而在SQL注入中类似的行为却很常见,Druid默认模式下,会在SQL parser解析之前,先消除语句中的单行和多行注释内容。
诸如’//or//‘1’='2等常见绕waf手段都是利用了SQL的快注释符。
3.1.6.禁止同时执行多条SQL语句
Druid默认每次只允许执行一条SQL,一次执行多条会被认为疑似是恶意SQL注入语句。
3.1.7.禁止永真条件
利用永真条件判断是否存在注入点是sql注入攻击最常用的手段。Druid对where、order by和group by节点之后的两个及以上永真条件进行过滤。
例如:select info from admin where ID =
i
d
;
其中
id; 其中
id;其中id为可控输入,如果输入为1,在数据库层就会变成永真条件。因此Druid目前的规则允许语句子句之后最多只存在一个永真逻辑表达式
3.1.8.禁止 getshell
into outfile是常用的利用注入点进行文件写入,druid的拦截是智能的,它只对真正的注入进行拦截,而正常的语句,例如:
记录每个用户的登录ip,写入文件中:select “127.0.0.1” into outfile ‘c:\index.php’;是被允许的。
3.2 极低的漏报率和误报率
基于SQL语意分析,大量应用和反馈,使得Druid的防SQL注入拥有极低的漏报率和误报率。
3.3 防注入对性能影响极小
内置参数化后的Cache、高性能手写的Parser,使得打开防SQL注入对应用的性能基本不受影响。
4. 加密数据库密码
Java项目中,数据库的密码往往以明文形式写在项目的配置文件里,所有能看到本项目代码的人员都可以拿到,这对运维安全来说,是一个很大的挑战。Druid为此提供一种数据库密码加密的手段ConfigFilter。
4.1项目里配置数据库加密方法如下
- DruidDataSource支持jvm启动参数配置filters:
java -Ddruid.filters=config
或者在yml文件里加入参数:filters:config - 同时可以在jvm启动参数配置配置开启解密:
-Ddruid.config.decrypt=true
或者在yml文件里加入参数:config.decrypt:true - 当然最重要的是解密私钥的配置:
config.decrypt.key:${privateKey}
4.2获取私钥和加密后的密码方式如下 - 去官网下载druid-1.0.16.jar后,在命令行中执行如下命令:
java -cp druid-1.0.16.jar com.alibaba.druid.filter.config.ConfigTools you_password
程序会输出私钥:privateKey:xxxxxxx
加密后的密码:password: xxxxxxx
5.代码demo
可通过实现FilterEventAdapter 在sql链接建立前和链接建立后进行一定的操作;这个类是非常复杂非常值得研究的;
exemple:
plulic class COnnectionLogFilter extends FileterEventAdapter {
@Override
publicc void connection_connectbefor(FilterChain chain,Properties info){
log.info("befor connection!");
}
@Override
public void connection_connectAfter(ConnectionProxy connection){
log.info("after connection!");
}
}
数据源配置:
若是springboot项目,可通过druid-spring-boot-starter
- spring.datasource.druid *``
<!-- druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<!--<version>1.2.6</version>-->
</dependency>
<!-- 排除默认hikaricp连接池 -->
<dependency>
<groupId>org.springfremework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
<exclusions>
<exclusion>
<artifactId>HikariCP</artifactId>
<groupId>com.zaxxer</groupId>
</exclusion>
</exclusion>
</dependency>
spring.datasource.druid.url=jdbc:mysql://127.0.0.1:3306/yzh?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.druid.username=root
--密码加密的配置
spring.datasource.druid.password=加密密码
spring.datasource.druid.filter.config.enabled=true
spring.datasource.druid.filter.connection-properties=config.decrypt=true;config.decrypt.key=${public-key}
public-Key=公钥
spring.datasource.druid.filter.s=conn,config,stat,slf4j
--config为官方提供的,可实现密码加解密;stat是用于统计功能的,slf4j用于打印日志
spring.datasource.druid.max-active=20
spring.datasource.druid.initial-size=5
spring.datasource.druid.min-idle=5
spring.datasource.druid.min-evictable-idle-time-millis=300000
spring.datasource.druid.max-wait=60000
spring.datasource.druid.validation-query=select 1
--获取连接时做检查
spring.datasource.druid.test-on-borrow=false
--归还连接时做检查
spring.datasource.druid.test-on-return=false
--连接池为空时做检查
spring.datasource.druid.test-while-idle=true
spring.datasource.druid.time-between-eviction-runs-millis=60000
--sql防注入
spring.datasource.druid.filter.wall.enable=true
--不能删除表
spring.datasource.druid.filter.wall.config.drop-table-allow=false```

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)