
jmeter上一个接口获取的token传递给下个接口(方法:Json与正则表达式)
一、jmeter上一个接口获取的token传递给下个接口
例1-使用Json
1、现在获取token的接口下面添加一个JSON提取器
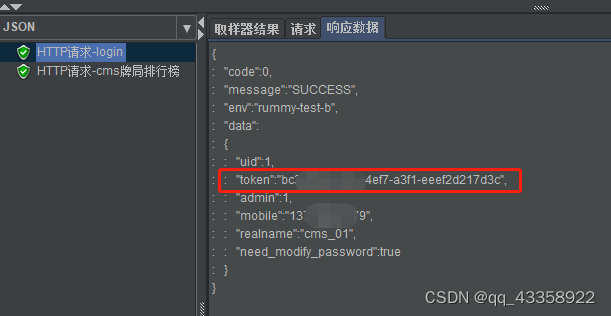
2、查看获取token的接口的返回报文,看到里面有token这节点
3、在json提取器中将返回报文中的token提取出来


JSON提取器说明:
Apply to:应用范围
Names of created variables :接收值的变量名,自定义,多个变量用分号分隔
JSON Path expression: json path表达式,也是用分号分隔
Match No.(0 for Random):0表示随机;n取第几个匹配值;-1匹配所有。若只要获取到匹配的第一个值,则填写1
Compute concatenation var(suffix_ALL):如果找到许多结果,则插件将使用’ , '分隔符将它们连接起来,并将其存储在名为 _ALL的var中
Default Values: 缺省值,匹配不到值的时候取该值,可写error。
4、$.data.token的解释
$相当于是根节点,然后一级一级的去找你要的参数

5、最后把token添加到报文头里面去

6、测试结果ok
例2-使用正则表达式提取器
1、新建http请求,获取接口返回的token的值
2、http请求右键,添加–后置处理器–正则表达式提取器


引用名称:token后面接口用到的变量名称
正则表达式:.“token”:“(.+?)”.
():括起来的部分就是要提取的。
.:匹配任何字符串。
+:一次或多次。
?:不要太贪婪,在找到第一个匹配项后停止。
模版 : 模板是使用提取到的第几个值。因为可能有多个值匹配,所以要使用模板。从 1 开始匹配,依次类推。这里只有一个,所以填写 即可
0
0
0:表示取所有值,取正则表达式中所有的值,也就是非括号与括号中所有的值
1
1
1:表示取第一个()中的值
2
2
2:表示只取第二个()中的值
n
n
n:表示取第n个()中的值
1
1
1,
2
2
2:表示取第一个()与第二个()中的值,注意:第一个括号中的值与第二个括号中的值连接方式就依赖于它们之间是用什么分隔符,如
1
1
1,
2
2
2,它们之间是用逗号来分隔的,那么取到的第一个值与第二个值连接方式就是逗号分隔
匹配数字:1,表示如何取值。0 代表随机取值,1 代表全部取值。这里只有一个,填 1 即可。
缺省值表示参数没有取到值的话,默认给它的值。一般不填
3.新建一个http请求,引用result 变量
操作同例1步骤5
二、正则表达式验证工具
RegexTester工具可以用来验证所写的正则表达式是否有误
1、下载地址:https://sourceforge.net/projects/regextester/
2、下载后解压,不需要安装,直接点击应用程序

3、然后打开页面,如下图页面
(1)RegEx Expression:输入正则表达式
(2)Test Text:需要提取的返回数据
(3)按Test[F5]键,生成对应的值,验证生成的值是否是自己所需要的值

三、常用表达式学习
1.\bhi\b : 匹配只有hi的字符,\b代表的位置,第一个\b代表单词开始的位置,第二个\b代表单词结束的位置
2.\bhi\b.*\bthis\b : 匹配hi的字符后,中间有任意个字符后,后面是this的字符
3. . : 表示任意字符的元字符
4. *:表示任意数量的元字符
5. \d : 表示任意一个数字
6. \d{2}: 表示任意一个数字出现两次,相当于\d\d
7. \s : 匹配任意的空白符,包括空格,换行符,制表符(tab),中文全角空格
8. \w : 匹配字母,数字,下划线或汉字
9. \d+ : 匹配一个或更多连续的数字
10. \b\w{2}\b : 匹配刚好有两个字符的单词
11. \b : 匹配单词的开始和结束
12. ^ : 匹配字符串的开始
13. $ : 匹配字符串的结束, 例: ^\d{2,5}$ 表示输入的数字必须是2位(包含)到5位(包含)之间
14. \ : 转义字符,如果要查找元字符就需要用转义字符来完成,比如: deerchao.net 实际上是deerchao.net
15. 重复次数说明: *是重复0次或多次,+是重复1次或多次,?是重复零次或一次,{n} 是重复n次,{n,}是重复n次到多次,{n,m}是重复n次到m次
16. [] : 括号里的字符会被匹配,比如[ab]匹配a或b字符,[,?]匹配逗号或问号
17. [a-z0-9A-Z] : 相当于匹配\w
18. | : 匹配或规则。比如: (0\d{2})[- ]?\d{8}|(0\d{3})[- ]\d{7}|0\d{2}[- ]?\d{8}|0\d{3}[- ]?\d{7} 这个就是匹配电话号码的,如:012-56236562, 0536-1234567,(0536)-1234567,01212345678
19. ():匹配分组,255.134.123.123 或 193.168.1.1 匹配表达式为:
(([01]?\d\d?|25[0-5]|2[0-4]\d).){3}([01]?\d\d?|25[0-5]|2[0-4]\d)
20. \W : 匹配任意不是字母,数字,下划线,汉字的字符
21. \S : 匹配任意不是空白符的字符
22. \D : 匹配任意非数字的字符
23. \B : 匹配不是单词开头或结尾的位置
24. [^x] : 匹配除了x以外的任意字符
25. [^aeiou] : 匹配除了aeiou以外的任意字符
26. (?\w+) 或(?‘word’\w+) 后向引用,用于重复搜索前面某个分组已经匹配的文本,引用时就可以写成\k。实际上分组0对应整个正则表达式;组号分配过程是从左到右分配两遍的,第一遍先扫描未命名的分组,第二遍扫描已命名的分组,所以命名分组的组号永远大于未命名分组的组号的; 可以用(?:exp)来剥夺组号分配的参与权
27. 分组命名的几种语法: (exp) 匹配exp表达式并将文本匹配的内容自动分配到分组里;
(? exp)匹配exp表达式里的文本内容到name组名下,也可以写成(?'name’exp); (?:exp)匹配exp表达式里内容,但是不捕获匹配的文本也不给匹配的文本分配组号;(?=exp)匹配exp前面的位置; (?<=exp)匹配exp后面的位置 ; (?!exp)匹配后面不是exp的位置 ; (?<!exp) 匹配前面不是exp的位置; (?#comment)添加注释,对正则表达式没有任何影响;
28. (?=exp)与(?<=exp)为零宽断言,其中(?=exp)为零宽度正预测先行断言,(?<=exp)为零宽度正回顾后发断言。(?=exp)表示自exp断言表达式出现的位置开始匹配断言之前的内容,如\b\w+(?=er\b) 源文件为tester,则匹配结果为:test。(?<=exp)表示自exp断言表达式内容结束后的位置开始匹配后面的内容,如(?<=test)\w+\b 源文件为test, 则匹配结果为:er。
例1:字符串“gfdd _fddsf fd”
例如以“g”开头以“d”结尾可写成
(^g.*d$)

2、常用正则表达式规则

中文字符 [\u4e00-\u9fa5]
双字节字符(包括汉字在内) [^\x00-\xff]
空白行 \n\s*\r
Email地址 [\w!#
%&'*+/=?^_`{|}~-]+(?:\.[\w!#
%&'+/=?^_`{|}~-]+)@(?:\w?.)+\w?
网址URL [a-zA-z]+://[^\s]*
国内电话号码 \d{3}-\d{8}|\d{4}-{7,8}
中国邮政编码 [1-9]\d{5}(?!\d)
18位身份证号 ^(\d{6})(\d{4})(\d{2})(\d{2})(\d{3})([0-9]|X)$

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)