
Bert实战(基于PyTorch)
bert
TensorFlow code and pre-trained models for BERT
项目地址:https://gitcode.com/gh_mirrors/be/bert
·
2022.4.23 记

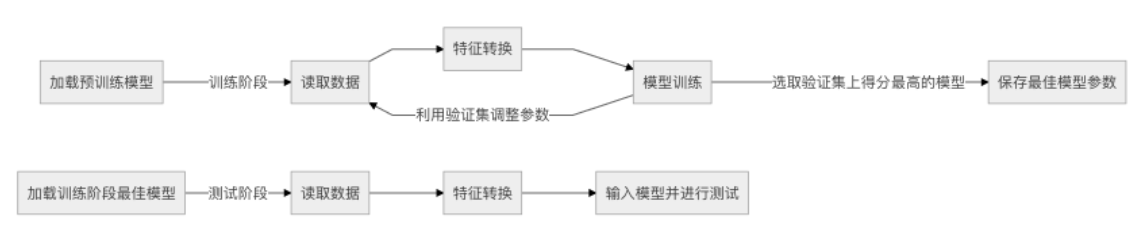
一、利用Bert进行特征提取
1、使用tokenizer编码输入文本
tokenizer是一个将纯文本转换为编码的过程,该过程不涉及将词转换成为词向量,仅仅是对纯文本进行分词,并且添加[MASK]、[SEP]、[CLS]标记,然后将这些词转换为字典索引。
model_class, tokenizer_class, pretrained_weights = (tfs.BertModel, tfs.BertTokenizer, 'bert-base-uncased')
# 主要是下面这一行代码
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
# BERT的分词操作不是以传统的单词为单位,而是以wordpiece为单位(比单词更细粒度的单位)
# add_special_tokens=True 表示在句子的首尾添加[CLS]和[SEP]符号
train_tokenized = train_set[0].apply((lambda x: tokenizer.encode(x, add_special_tokens=True)))
tokenizer=... 这一行代码会完成以下工作:
- 使用BertTokenizer将单词分割为token;
- 添加句子分类所需的特殊tokens(在第一个位置是[CLS],在句子的末尾是[SEP]);
- 用嵌入表中的 id 替换每个token,嵌入表是我们从训练模型中得到的一个组件。
2、填充数据
句子(文本)有长有短,所以在数据集作为输入处理之前要将句子处理成同一长度:
# 提高训练速度——把句子都处理成同一长度——少填多截
train_max_len = 0
for i in train_tokenized.values:
if len(i) > train_max_len:
train_max_len = len(i)
train_padded = np.array([i + [0] * (train_max_len-len(i)) for i in train_tokenized.values])
print("train set shape:", train_padded.shape)
# 让模型知道,哪些词不用处理
# np.where(condition) 满足条件condition则输出
train_attention_mask = np.where(train_padded != 0, 1, 0)
二、构建模型
1、建立模型
class BertCLassificationModel(nn.Module):
def __init__(self):
super(BertCLassificationModel, self).__init__()
model_class, tokenizer_class, pretrained_weights = (tfs.BertModel, tfs.BertTokenizer, 'bert-base-uncased')
self.tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
self.bert = model_class.from_pretrained(pretrained_weights)
self.dense = nn.Linear(768, 2) # bert默认的隐藏单元数是768, 输出单元是2,表示二分类
def forward(self, batch_sentences):
batch_tokenized = self.tokenizer.batch_encode_plus(batch_sentences, add_special_tokens=True,
max_length=66, pad_to_max_length=True)
input_ids = torch.tensor(batch_tokenized['input_ids'])
attention_mask = torch.tensor(batch_tokenized['attention_mask'])
bert_output = self.bert(input_ids, attention_mask=attention_mask)
bert_cls_hidden_state = bert_output[0][:, 0, :] # 提取[CLS]对应的隐藏状态
linear_output = self.dense(bert_cls_hidden_state)
return linear_output
2、分割数据
# ======数据分批======
# 对原来的数据集进行改造,分成batch_size为64大小的数据集,以便模型进行梯度下降
sentences = main.train_set[0].values
targets = main.train_set[1].values
train_inputs, test_inputs, train_targets, test_targets = main.train_test_split(sentences, targets)
batch_size = 64
batch_count = int(len(train_inputs) / batch_size)
batch_train_inputs, batch_train_targets = [], []
for i in range(batch_count):
batch_train_inputs.append(train_inputs[i*batch_size : (i+1)*batch_size])
batch_train_targets.append(train_targets[i*batch_size : (i+1)*batch_size])
三、训练模型
# ======训练模型======
epochs = 3
lr = 0.01
print_every_batch = 5
bert_classifier_model = BertCLassificationModel()
optimizer = optim.SGD(bert_classifier_model.parameters(), lr=lr, momentum=0.9)
criterion = nn.CrossEntropyLoss()
for epoch in range(epochs):
print_avg_loss = 0
for i in range(batch_count):
inputs = batch_train_inputs[i]
labels = torch.tensor(batch_train_targets[i])
optimizer.zero_grad()
outputs = bert_classifier_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print_avg_loss += loss.item()
if i % print_every_batch == (print_every_batch-1):
print("Batch: %d, Loss: %.4f" % ((i+1), print_avg_loss/print_every_batch))
print_avg_loss = 0
四、模型评价
# ======模型评价======
total = len(test_inputs)
hit = 0
with torch.no_grad():
for i in range(total):
outputs = bert_classifier_model([test_inputs[i]])
_, predicted = torch.max(outputs, 1)
if predicted == test_targets[i]:
hit += 1
print("Accuracy: %.2f%%" % (hit / total * 100))
代码结构:

完整代码如下:
part1—特征抽取
main.py
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import torch
import transformers as tfs
import warnings
warnings.filterwarnings('ignore')
train_df = pd.read_csv('train.tsv', delimiter='\t', header=None)
train_set = train_df[:3000] # 取其中3000条数据作为我们的数据集
print("Train set shape:", train_set.shape)
a = train_set[1].value_counts() # 查看数据集中标签的分布
print(a)
# 结果可以看出,积极和消极的标签基本对半分
# ======利用BERT进行特征抽取======
'''
输入数据经过BERT模型,获取输入数据的特征,
这些特征包含了整个句子的信息,是语境层面的。类似于EMLo的特征抽取。
这里没有使用到BERT的微调,因为BERT并不参与后面的训练,仅仅进行特征抽取操作。
'''
model_class, tokenizer_class, pretrained_weights = (tfs.BertModel, tfs.BertTokenizer, 'bert-base-uncased')
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
# BERT的分词操作不是以传统的单词为单位,而是以wordpiece为单位(比单词更细粒度的单位)
# add_special_tokens 表示在句子的首尾添加[CLS]和[SEP]符号
train_tokenized = train_set[0].apply((lambda x: tokenizer.encode(x, add_special_tokens=True)))
# 提高训练速度——把句子都处理成同一长度——少填多截(pad、)
train_max_len = 0
for i in train_tokenized.values:
if len(i) > train_max_len:
train_max_len = len(i)
train_padded = np.array([i + [0] * (train_max_len-len(i)) for i in train_tokenized.values])
print("train set shape:", train_padded.shape)
# 让模型知道,哪些词不用处理
# np.where(condition) 满足条件condition则输出
train_attention_mask = np.where(train_padded != 0, 1, 0)
# 经过上面的步骤,输入数据已经可以正确被BERT模型接受并处理,下面进行特征的输出
train_input_ids = torch.tensor(train_padded).long()
train_attention_mask = torch.tensor(train_attention_mask).long()
with torch.no_grad():
train_last_hidden_states = model(train_input_ids, attention_mask=train_attention_mask)
# bert模型的输出:
# print(train_last_hidden_states[0].size())
part2—微调建模
fine-tuned.py
# ********利用BERT微调方式进行建模********
import torch
from torch import nn
from torch import optim
import transformers as tfs
import math
import main
# ======建立模型======
class BertCLassificationModel(nn.Module):
def __init__(self):
super(BertCLassificationModel, self).__init__()
model_class, tokenizer_class, pretrained_weights = (tfs.BertModel, tfs.BertTokenizer, 'bert-base-uncased')
self.tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
self.bert = model_class.from_pretrained(pretrained_weights)
self.dense = nn.Linear(768, 2) # bert默认的隐藏单元数是768, 输出单元是2,表示二分类
def forward(self, batch_sentences):
batch_tokenized = self.tokenizer.batch_encode_plus(batch_sentences, add_special_tokens=True,
max_length=66, pad_to_max_length=True)
input_ids = torch.tensor(batch_tokenized['input_ids'])
attention_mask = torch.tensor(batch_tokenized['attention_mask'])
bert_output = self.bert(input_ids, attention_mask=attention_mask)
bert_cls_hidden_state = bert_output[0][:, 0, :] # 提取[CLS]对应的隐藏状态
linear_output = self.dense(bert_cls_hidden_state)
return linear_output
# ======数据分批======
# 对原来的数据集进行改造,分成batch_size为64大小的数据集,以便模型进行梯度下降
sentences = main.train_set[0].values
targets = main.train_set[1].values
train_inputs, test_inputs, train_targets, test_targets = main.train_test_split(sentences, targets)
batch_size = 64
batch_count = int(len(train_inputs) / batch_size)
batch_train_inputs, batch_train_targets = [], []
for i in range(batch_count):
batch_train_inputs.append(train_inputs[i*batch_size : (i+1)*batch_size])
batch_train_targets.append(train_targets[i*batch_size : (i+1)*batch_size])
# ======训练模型======
epochs = 3
lr = 0.01
print_every_batch = 5
bert_classifier_model = BertCLassificationModel()
optimizer = optim.SGD(bert_classifier_model.parameters(), lr=lr, momentum=0.9)
criterion = nn.CrossEntropyLoss()
for epoch in range(epochs):
print_avg_loss = 0
for i in range(batch_count):
inputs = batch_train_inputs[i]
labels = torch.tensor(batch_train_targets[i])
optimizer.zero_grad()
outputs = bert_classifier_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print_avg_loss += loss.item()
if i % print_every_batch == (print_every_batch-1):
print("Batch: %d, Loss: %.4f" % ((i+1), print_avg_loss/print_every_batch))
print_avg_loss = 0
# ======模型评价======
total = len(test_inputs)
hit = 0
with torch.no_grad():
for i in range(total):
outputs = bert_classifier_model([test_inputs[i]])
_, predicted = torch.max(outputs, 1)
if predicted == test_targets[i]:
hit += 1
print("Accuracy: %.2f%%" % (hit / total * 100))
TensorFlow code and pre-trained models for BERT
最近提交(Master分支:2 个月前 )
eedf5716
Add links to 24 smaller BERT models. 4 年前
8028c045 - 4 年前

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)