
【NLP相关】从零开始理解BERT模型:NLP领域的突破(BERT详解与代码实现)

【NLP相关】从零开始理解BERT模型:NLP领域的突破(BERT详解与代码实现)
自然语言处理(Natural Language Processing, NLP)是人工智能(Artificial Intelligence, AI)领域中的重要分支之一。随着深度学习(Deep Learning)技术的迅速发展,NLP的研究也得到了大幅度的提升。其中,BERT模型(Bidirectional Encoder Representations from Transformers)是当前NLP领域的研究热点,成为自然语言处理任务中的一种主流模型。
1. BERT模型介绍
BERT模型是一种预训练的深度神经网络模型,由Google团队于2018年提出,基于Transformer架构,旨在解决NLP中的语言表示问题。该模型采用了自编码器(AutoEncoder)的预训练思想,先在大规模语料库上进行无监督的预训练,再在具体任务上进行微调,从而达到很好的效果。
1.1 Transformer架构
BERT模型基于Transformer架构,该架构主要由编码器(Encoder)和解码器(Decoder)两个部分组成。其中,编码器可以用于NLP中的语言表示学习任务,解码器则可用于翻译等任务。
Transformer架构中的编码器主要包括多头自注意力机制(Multi-Head Self-Attention Mechanism)和前馈神经网络(Feedforward Neural Network)两个部分。多头自注意力机制可以有效地捕捉输入句子中不同位置之间的依赖关系,提高了表示的效果;而前馈神经网络则可将输入序列转换成隐层表示。通过多个编码器的堆叠,Transformer架构可以将输入序列编码成高质量的语言表示。
1.2 BERT模型的预训练
BERT模型的预训练分为两个阶段:Masked Language Model(MLM)和Next Sentence Prediction(NSP)。
MLM是一种基于掩码的语言模型,其目标是从输入序列中掩盖一些单词,然后让模型预测这些单词的词汇。通过MLM预训练,模型可以学习到单词之间的关系,提高语言表示的效果。
NSP则是一种二分类任务,其目标是判断两个输入句子是否是相邻的,从而对模型进行微调。通过NSP预训练,模型可以学习到句子之间的关系,进一步提高语言表示的效果。
1.3 BERT模型的微调
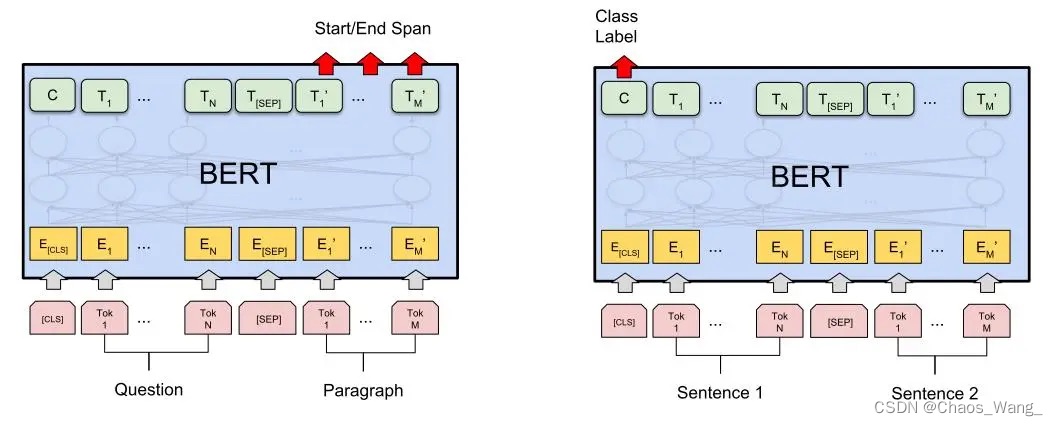
在完成预训练之后,BERT模型可以在各种具体任务上进行微调,例如文本分类、问答系统、命名实体识别等。在微调过程中,可以将BERT模型的输出连接到全连接层(Fully Connected Layer)进行分类或者生成。
2. BERT模型的优势和劣势
2.1 优势
(1)双向编码:BERT模型采用了双向编码,即能够同时考虑上下文信息,大大提高了表示效果。
(2)预训练思想:BERT模型的预训练思想是将模型训练在大规模语料库上,能够提高模型的泛化能力。
(3)可迁移性:BERT模型在预训练和微调中使用相同的模型结构和参数,因此可以将其应用于不同的任务中,减少了训练时间和成本。
2.2 劣势
(1)计算资源:BERT模型需要大量的计算资源,包括显存和计算时间等,限制了其在实际应用中的使用。
(2)标注数据:BERT模型的微调需要大量的标注数据,对于一些低资源语言或者特定领域的任务,可能会面临数据稀缺的问题。
(3)过拟合:BERT模型在训练过程中容易过拟合,需要采用正则化等技术来缓解。
3. BERT模型公式推导
BERT模型的数学公式推导较为复杂,这里简单介绍其主要的数学公式,具体推导过程可以参考官方论文或者相关教材。
3.1 Encoder层
在BERT模型中,Encoder层主要包括多头自注意力机制和前馈神经网络两部分。其数学公式如下所示:
(1)多头自注意力机制:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
其中,Q、K、V分别表示查询、键、值向量,softmax为softmax函数,d_k为向量维度。
(2)前馈神经网络:
F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x) = max(0, xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
其中,W1、b1、W2、b2分别表示两个全连接层的权重和偏置。
3.2 Pre-training任务
BERT模型的预训练任务主要包括Masked Language Model和Next Sentence Prediction两部分。其数学公式如下所示:
(1)Masked Language Model:
P ( x ) = ∏ i = 1 n P ( x i ∣ x < i , θ ) m i P(x) = \prod_{i=1}^{n} P(x_i | x_{<i}, \theta) ^{m_i} P(x)=i=1∏nP(xi∣x<i,θ)mi
其中,P(x)表示目标概率分布,m_i表示第i个token是否被mask,x_{<i}表示第i个token之前的所有token。
(2)Next Sentence Prediction:
P N S P ( s , t ) = e x p ( ϕ ( s , t ) ) e x p ( ϕ ( s , t ) ) + e x p ( ϕ ( s , t r a n d ) ) P_{NSP}(s, t) = \frac{exp(\phi(s, t))}{exp(\phi(s, t)) + exp(\phi(s, t_{rand}))} PNSP(s,t)=exp(ϕ(s,t))+exp(ϕ(s,trand))exp(ϕ(s,t))
其中,s和t分别表示两个句子, ϕ ( s , t ) \phi(s,t) ϕ(s,t)表示句子对的向量表示, t r a n d t_{rand} trand表示与s来自不同文档的随机句子。
4. BERT模型的研究进展
BERT模型在问答系统、文本分类、语言生成等领域取得了显著的成果。随着研究的深入,BERT模型也得到了进一步的改进和优化。以下是BERT类模型的一些研究进展:
-
RoBERTa
RoBERTa模型是在BERT模型的基础上进行优化,主要包括动态掩码、更长的训练时间和更大的批量等。RoBERTa模型在多个自然语言处理任务上超越了BERT模型的表现。 -
ALBERT
ALBERT模型是在BERT模型的基础上进行优化,采用了参数共享和跨层参数交互等技术,大大减少了模型参数数量和训练时间,同时提高了模型性能。 -
ELECTRA
ELECTRA模型是一种新型的预训练方法,采用了生成式对抗网络(GAN)的思想,通过生成假数据来训练判别器模型,从而提高了模型的泛化能力和性能。 -
GPT-3
GPT-3模型是一种基于自回归语言模型的模型,采用了大量的参数和模型结构,具有强大的语言生成能力和泛化能力,已经在自然语言处理领域引起了广泛关注。
5. BERT的代码实现
5.1 基于PyTorch实现,不使用封装好的库
以下是只基于PyTorch实现的BERT模型,参考自transformers库。
import torch
import torch.nn as nn
class BertModel(nn.Module):
def __init__(self, vocab_size, hidden_size, num_hidden_layers, num_attention_heads, intermediate_size, max_seq_length, type_vocab_size, pad_token_id):
super().__init__()
# Embedding Layer
self.token_embeddings = nn.Embedding(vocab_size, hidden_size)
self.position_embeddings = nn.Embedding(max_seq_length, hidden_size)
self.token_type_embeddings = nn.Embedding(type_vocab_size, hidden_size)
# Encoder Layer
self.encoder_layers = nn.ModuleList([BertEncoderLayer(hidden_size, num_attention_heads, intermediate_size) for _ in range(num_hidden_layers)])
# Pooler Layer
self.pooler_layer = BertPooler(hidden_size)
# Initialization
self.apply(self.init_bert_weights)
self.max_seq_length = max_seq_length
self.pad_token_id = pad_token_id
def init_bert_weights(self, module):
""" Initialize the weights of the model """
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=0.02)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=0.02)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
def forward(self, input_ids, token_type_ids=None, attention_mask=None):
# Embedding Layer
embeddings = self.token_embeddings(input_ids)
position_embeddings = self.position_embeddings(torch.arange(self.max_seq_length).unsqueeze(0).to(input_ids.device))
token_type_embeddings = self.token_type_embeddings(token_type_ids) if token_type_ids is not None else 0
embeddings = embeddings + position_embeddings + token_type_embeddings
# Mask
if attention_mask is None:
attention_mask = input_ids.ne(self.pad_token_id)
attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
# Encoder Layer
hidden_states = embeddings
for layer in self.encoder_layers:
hidden_states = layer(hidden_states, attention_mask)
# Pooler Layer
pooled_output = self.pooler_layer(hidden_states[:, 0, :])
return pooled_output
class BertEncoderLayer(nn.Module):
def __init__(self, hidden_size, num_attention_heads, intermediate_size):
super().__init__()
# Self-Attention Layer
self.self_attention = BertSelfAttention(hidden_size, num_attention_heads)
self.self_attention_layer_norm = nn.LayerNorm(hidden_size)
# Feed-Forward Layer
self.feed_forward = BertFeedForward(intermediate_size, hidden_size)
self.feed_forward_layer_norm = nn.LayerNorm(hidden_size)
def forward(self, hidden_states, attention_mask):
# Self-Attention Layer
self_attention_outputs = self.self_attention(hidden_states, attention_mask)
hidden_states = hidden_states + self_attention_outputs
hidden_states = self.self_attention_layer_norm(hidden_states)
# Feed-Forward Layer
feed_forward_outputs = self.feed_forward(hidden_states)
hidden_states = hidden_states + feed_forward_outputs
hidden_states = self.feed_forward_layer_norm(hidden_states)
return hidden_states
class BertSelfAttention(nn.Module):
def __init__(self, hidden_size, num_attention_heads):
super().__init__()
self.num_attention_heads = num_attention_heads
self.attention_head_size = hidden_size // num_attention_heads
self.query = nn.Linear(hidden_size, hidden_size)
self.key = nn.Linear(hidden_size, hidden_size)
self.value = nn.Linear(hidden_size, hidden_size)
self.dropout = nn.Dropout(0.1)
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self, hidden_states, attention_mask):
mixed_query_layer = self.query(hidden_states)
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
attention_scores = attention_scores + attention_mask
attention_probs = nn.Softmax(dim=-1)(attention_scores)
attention_probs = self.dropout(attention_probs)
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.num_attention_heads * self.attention_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
return context_layer
class BertFeedForward(nn.Module):
def __init__(self, intermediate_size, hidden_size):
super().__init__()
self.intermediate = nn.Linear(hidden_size, intermediate_size)
self.output = nn.Linear(intermediate_size, hidden_size)
self.dropout = nn.Dropout(0.1)
def forward(self, hidden_states):
intermediate_output = self.intermediate(hidden_states)
intermediate_output = nn.ReLU()(intermediate_output)
intermediate_output = self.dropout(intermediate_output)
layer_output = self.output(intermediate_output)
layer_output = self.dropout(layer_output)
return layer_output
class BertPooler(nn.Module):
def __init__(self, hidden_size):
super().__init__()
self.dense = nn.Linear(hidden_size, hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
pooled_output = self.dense(hidden_states)
pooled_output = self.activation(pooled_output)
return pooled_output
5.2 基于transformers库实现
以下是BERT模型的Python代码实现,使用了Hugging Face的Transformers库:
from transformers import BertTokenizer, BertForSequenceClassification
import torch
# 加载预训练的BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# 准备输入数据
text = "This is a sample sentence."
inputs = tokenizer(text, return_tensors='pt')
# 运行模型
outputs = model(**inputs)
# 打印输出
print(outputs)
上述代码实现了BERT模型的基本用法,包括模型和分词器的加载、输入数据的准备和模型的运行。值得注意的是,代码中使用了PyTorch的张量(tensor)作为输入和输出,这是因为Transformers库采用了PyTorch作为主要的深度学习框架。
如果要在自己的数据集上训练BERT模型,可以使用Transformers库提供的Trainer类,示例代码如下:
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
# 加载数据和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# 准备训练参数
train_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=64,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
logging_steps=10,
evaluation_strategy='steps',
eval_steps=50,
save_total_limit=3,
save_steps=50
)
# 定义训练数据和评估数据
train_dataset = ...
eval_dataset = ...
# 定义Trainer对象并进行训练
trainer = Trainer(
model=model,
args=train_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset
)
trainer.train()
上述代码实现了BERT模型在自定义数据集上的训练,其中使用了Trainer类和TrainingArguments对象来管理训练参数和数据集。需要注意的是,训练数据和评估数据需要自行准备,可以采用PyTorch的数据加载器(DataLoader)进行读取和处理。
参考文献

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 3
3 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)