
毕业设计-基于 BERT 的中文长文本分类系统
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯毕业设计-基于 BERT 的中文长文本分类系统
课题背景和意义
随着数字经济和互联网技术的发展,人类正处于信息爆炸时代。互联网所引发的信 息革命,使得语音、图像和文本等信息量指数型增长,人类社会也进入了大数据时代。 面对海量数据,如何从其中挖掘出最有价值的信息正逐渐成为研究领域的热点。 文本作为信息传播的主要媒介,具有传播速度快、信息检索便捷性以及内容丰富等 特点。然而,大量的文本数据如果没有经过有效的科学分类管理,只是简单的存储在后 台数据库中,则无法实现其应有的应用价值,最终沦落为电子垃圾。传统基于人工的 费时费力整理方法已无法适应大规模语料的需求。因此,如何利用计算机技术实现对 文本高效管理,为用户从海量的后台“数据仓库”中准确的提供所需要的文本内容具有 重大的研究意义,因此衍生出自然语言处理(Natural Language Processing,NLP)技术。 自然语言处理是语言学、人工智能及计算机科学领域的一个分支,探寻如何处理与 应用自然语言,实现计算机与人类语言之间的交互。
实现技术思路
一、文本分类的相关技术
文本分类介绍
1、文本分类定义
基于深度学习的文本分类系统是指不依靠专家经验,按照预先设定好的类别标签, 通过搭建神经网络对文本的高级特征进行学习并且量化,训练分类器模型实现文本的自 动化分类。本文研究所使用的文本分类数据集已标签化,因此属于有监督学习这一范畴。
通过构 建基于深度学习的分类器模型学习映射函数 f ,实现待分类的长文本数据集 D到类别标 签集C 之间的映射。
![]()
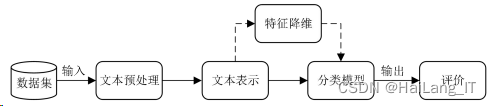
2、文本分类流程
文本分类包括如下几个基本组成单元:文本预处理、文本表示、特征降维、分类器 模型及评价等 5 部分,分类流程图如图所示。

文本预处理
文本语料的格式不同如 pdf、 html 页面,包括半结构化与非结构化形式的内容,参杂大量对文本分类无意义的成分(如 html 格式标签、特殊符号、公式、图表等内容)。如果对所有的信息全部保留,将浪费 大量的计算资源,延长模型训练时间,导致模型无法收敛,所以需要对文本进行第一步 预处理操作。

1、文本清洗
文本清洗是文本数据集预处理的第一个环节。针对不同格式的原始语料数据删除与 文本语义无关的 html 标签、图片、公式以及乱码等特殊字符。
2、分词
相对于英文文本具有分割词的天然空格,中文文本序列较复杂,需要对汉字组合成 词,才能表示真实的含义。目前在中文长文本分类中所采用的分词方法可以总结为三类: 基于字符串匹配的分词、基于统计的分词、基于理解的分词。
3、去停用词
停用词是指对文本语义表达没有价值的高频词,主要包括介词、语气助词以及无价 值但高频出现的汉字组如“对”、“就”、“往往”等。
二、文本表示模型
按照文本的表示形式划分,分为离散表示与分布式表示两种。以独热编码为典型代 表的离散表示由于具有高维、稀疏的数据特征,导致在采用机器学习的方法构建文本分 类模型时不能充分的挖掘文本语义特征,表征能力有限。
Word2Vec 模型
谷歌公司的 Mikolov 等人基于局部上下文窗口提出采用 Word2Vec 进行文本表示, 其 包 含 连 续 词 袋 模 型 (Continuous Bag of Words , CBOW) 和 跳 字 模 型 (Continuous Skip-gram Model,Skip-gram),两种模型结构如图所示。

CBOW 模型与 Skip-gram 模型的组成结构相同,均由输入层、隐藏层、输出层三部 分 构 成 , 但 是 其 训 练 过 程 是 不 一 样 的 。 CBOW 模 型 是 通 过 上 下 文 词 WC=wt-k ,wt-k+1 ,...,wt+k-1 ,wt+k 对目标词出现的概率进行预测,进而得到目标词 wt 的词嵌入 表示。

将平均词向量h 作为 CBOW 模型上下文语义表示,进行预测目标词 wt 的概率值, 公式如所示:

在 CBOW 模型中词向量矩阵是唯一的网络参数,对于训练词嵌入模型的整个语 料,CBOW 模型优化,实现最大化所有词的对数似然:

BERT 模型
随着词嵌入模型在文本表示的长河中如火如荼的发展,以 Word2Vec 为典型代表的 静态词向量逐渐显露出无法克服一词多义问题,因此动态词向量概念被提出来。
与 Word2Vec 与 Glove 等 静态词嵌入模型相比,BERT 采用 12 层 Transformer 架构在大量通用语料库上对模型进 行训练学习,利用所有编码层的上下文来训练深度双向表示,因此是一种深层预训练模 型,具有并行化计算优点,同时解决一词多义问题。

三、文本分类模型
经过文本预处理以及文本表示两个环节,非结构化的文本已经转换为张量形式的结 构化数据,接下来就是如何搭建分类器模型,以文本表示的结果作为分类模型的输入, 文本的预测类别标签作为输出。
卷积神经网络分类模型
卷积神经网络(Convolutional Neural Networks, CNN)最先被使用在图像领域中,Kim 针对 CNN 的输入层做了一些变形使其适用于文本类型,提出 TextCNN 模型开启了文本 分类的新时代。TextCNN 模型结构如图所示,由输入层、卷积层、池化层、全连接 层四部分构成。

(1) 输入层
将待分类的文本送入 BERT 模型生成文本的词向量表示,将其结果作为 TextCNN 模型的输入,输入层的数据为n×d 大小的矩阵。
(2) 卷积层
卷积层作为 TextCNN 模型的核心单元,能够提取出文本的局部特征,在特征提取的过程中发挥关键作用。

如图所示对卷积的过程以输入层65词向量矩阵,4×5 卷积核,卷积核的数量 为 1,卷积步长为 1 为例进行介绍。卷积核在输入层的词向量矩阵上按从上到下的方向 进行卷积运算,每个卷积核经过卷积层运算之后会得到一个一维向量结果,如图中 的[1,1, 2]。
获得卷积层的输出结果之后会增加一个激励层,在其中使用激活函数,提高网络的 非线性表达能力。常见的激活函数有 Sigmoid、Tanh、Relu 与 Leaky Relu 函数,函数图 如图所示。

在本文研究所使用的 CNN 中采用 Relu 激活函数,其对分类器模型来说收敛速度要快于 Sigmoid 与 Tanh,而且能够解决梯度消失问题,其公式如所示。
![]()
(3) 池化层
在卷积层提取出文本的局部特征之后,需要对其加以池化操作。一方面,通过池化 可以剔除一些不重要的信息,提取出更重要的文本特征;另一方面,通过池化操作能够 达到降低特征维度,缓解分类器模型过拟合问题,加快模型收敛。
(4) 全连接层
全连接层作为 TextCNN 模型的最后一个部分,将池化层的输出融合向量作为其输 入。
2、循环神经网络分类模型
由于 CNN 在应用于文本分类时,其卷积核的视野受到卷积核大小的影响,固定大 小的卷积核则只能提取出局部的特征,因此研究者们提出循环神经网络(Recurrent Neural Network,RNN)分类模型。

图的右侧为 RNN 结构的展开形式, xt-1 , xt , xt+1 为输入的文本序列, xt 代表t 时 刻的输入文本向量,ot-1和ot 分别代表t -1和t 时刻 RNN 网络的输出向量。隐藏层的输出 值ht 与网络的输出值ot 计算公式如下所示

基于 Transformer 的分类模型
传统的基于深度学习的分类模型主要采用 CNN 以及基于时间序列的 RNN 两种模 式。Vaswani 等人最早提出 Transformer 架构用于机器翻译任务,其用自注意力机制与前 馈神经网络取代传统的 CNN 与 RNN 结构,在运算的过程中可以实现高度的并行化,这 是传统的序列模型无法实现的。

Transformer 的编码部分组成单元为多头自注意力层、残差连接与归一化层、前馈神 经网络层。归一化则是将相加的结果进行标准化,解决网络在反向传播过程中 的梯度问题,加快模型收敛速度。归一化之后的文本向量送入前馈神经网络,其主要包 含一个采用 Relu 激活函数的非线性变换和一个线性变换两层结构,公式如所示。
![]()
注意力机制
借鉴人类在面对陌生的图像或文本时会依据信息的重要程度在不同部分分配不同的关注度,降低对无效信息的关注程度,从而获取更多对目标结果有价值的信息,研究 者们提出注意力机制概念。
1、基础注意力机制
基础注意力在 NLP 中最早被应用于机器翻译任务,通过注意力使翻译模型关注到 序列数据中的重要部分。基础注意力实际上可以被描述为输入序列到输出序列之间的映 射,过程如图所示。

在机器翻译的编码器与解码器结构中,Query 相当于解码器的内容,而 key 与 value 均为编码器的内容。而在文本分类领域由于只涉及到编码器部分,因此 Query、key 与 value 的文本向量矩阵一致。
注意力的计算过程如下: 首先会对 Query 与每个 key 之间的相关性进行计算,获得每个 key 对应的权重系数 simi ,公式如 所示。

然后将得到的权重系数通过 softmax 进行归一化处理,计算公式如所示。

最后,将上述的注意力权重值与相对应的 value 值加权求和,使得模型关注重要部 分,公式如所示。

2、层次注意力机制
在长文本分类领域中,层次注意力机制最早由 Yang等人提出,在构建分类器模 型时考虑待分类文档的结构特征。将文本分类器模型架构分成词级注意层和句级注意层 两部分,各部分均使用双向循环神经网络并搭配基础注意力实现信息提取。
评价指标
本节在介绍评价指标之前先介绍二分类的混淆矩阵,如表所示。之后,将结合表对常用的分类指标进行描述。

表中,TP 指实际与预测均为正例的数量;TN 则为实际与预测均为负例的数量;FN 表示实际是正例而被预测为负例的数量;FP 指实际为负例而被预测是正例的数量。
根据上面的定义,接下来对分类中常用的性能指标进行概述:
(1) 准确率(Accuracy): 准确率指样本集中被正确预测的样本所占的比重,是最常用的评估指标,如式所示:

(2) 精确率(Precision): 精确率是针对预测结果来说的,指实际被预测为正例的样本数中,真正的正例所占 的比重大小,具体计算公式如式所示:

(3) 召回率(Recall): 召回率指在真正的正样本集中而被正确预测的样本所占的比例大小,其计算公式如所示:

(4) F1-score: F1-score 为召回率与精确率的加权平均,是两者的综合衡量指标,计算公式如所示。

实现效果图样例
中文长文本分类系统:

我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!
最后

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 3
3 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)