json_tuple一定比 get_json_object更高效吗?
要理性的比较json_tuple和get_json_object的效率,最近有朋友问我:hive中取多个key时,为什么用了json_tuple,效率反而比get_json_object慢了一些?
先看一下网上的结论:
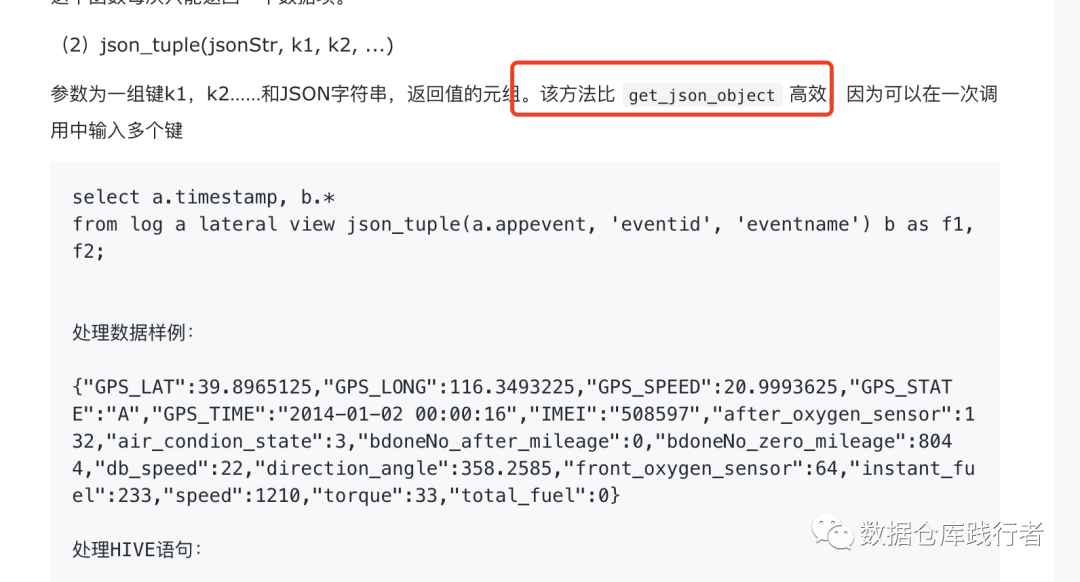



上面是搜索网上的结论的截图,基本都会认为json_tuple比get_json_object高效,理由是:取多个key值时,json_tuple只解析一次,而get_json_object需要解析多次。
我们来看实际情况:
1、get_json_object缓存jsonObject (并非无脑解析多次)

一般情况下,由json字符串序列化成jsonObject这个过程是最耗费时间的。从代码中可以看到,get_json_object函数会缓存jsonObject,也就是说json字符串转化为jsonObject的过程只有一次。并不是解析多次。
2、执行计划层面(get_json_object更简洁,json_tuple更繁重)
从下图中可以看到,get_json_object的执行计划,只有一个selectOperator ,非常简单

而json_tuple是属于udtf函数,中间会有udtf相关的operator
详情可以参考:你真的了解Lateral View explode吗? 这篇

执行计划图大概是这个样子:
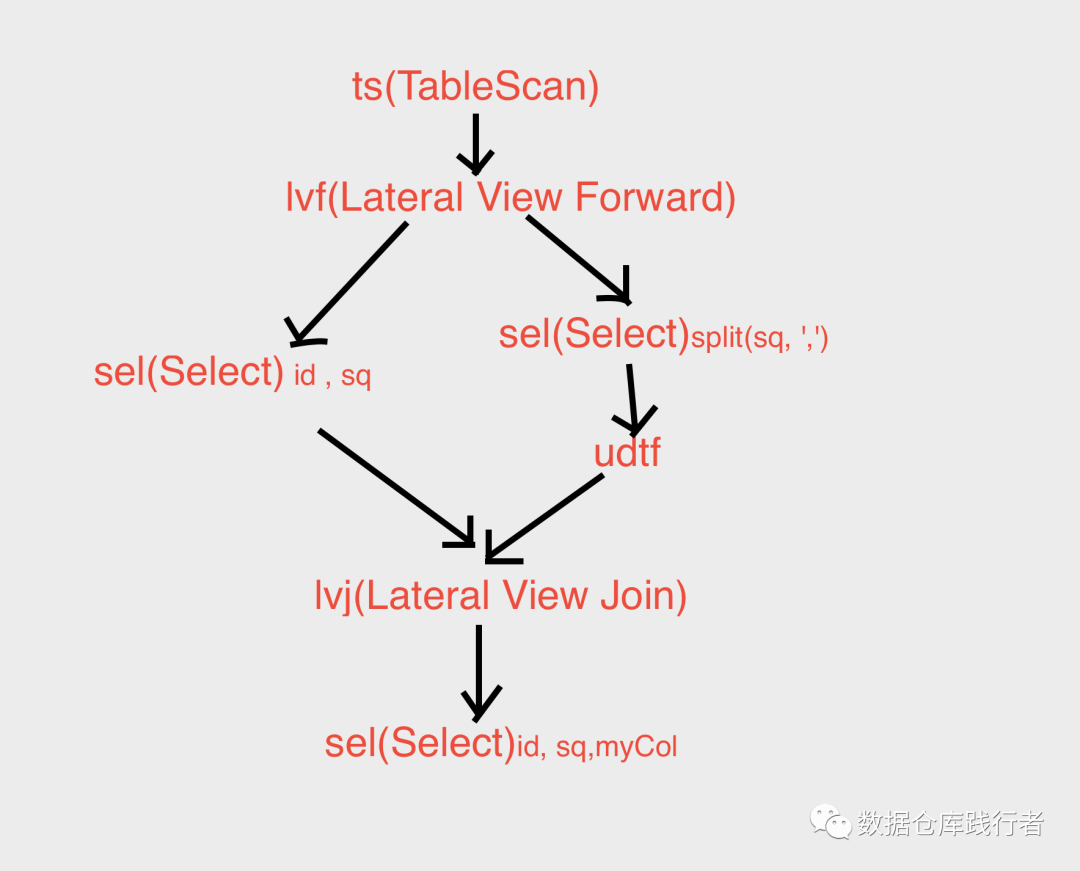
图是从 你真的了解Lateral View explode吗? 中取的,不太合适,但基本流程是一样的
json_tuple在这个过程中也是有一定的性能损耗的
3、从功能多样性来看(这个和性能无关啦)
get_json_object方法可以处理的 path更为丰富,能够支持正则、支持嵌套、取多层等。
而json_tuple简单粗暴,只能解析第一层key
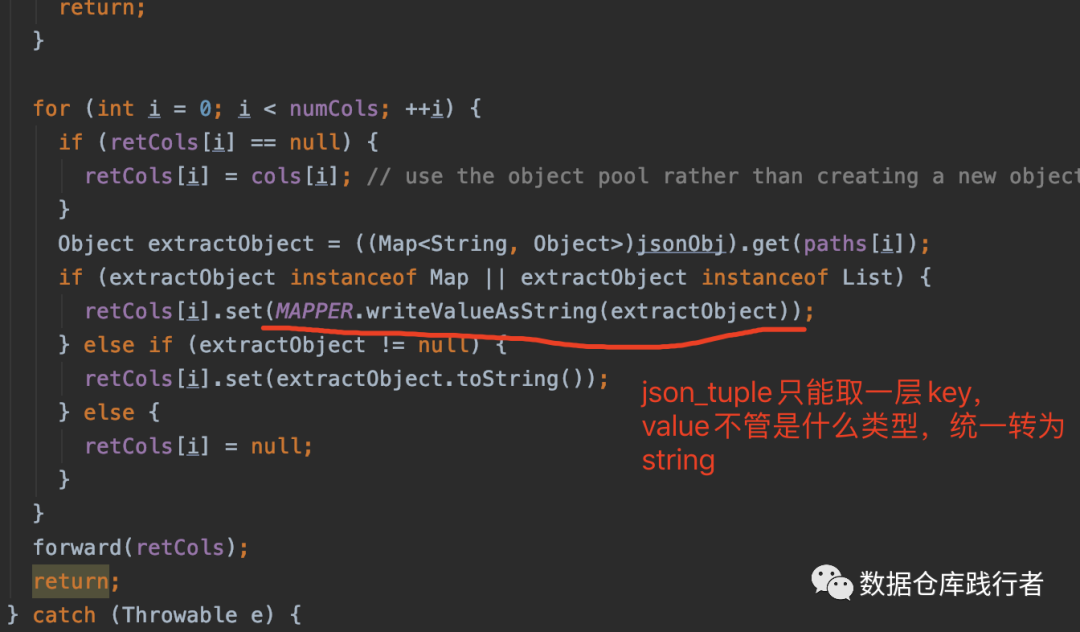
以上,我们在实际用的时候,不要盲从,用get_json_object也是没关系的,况且正常情况下,一次也不会取成千上万个key值... 重要的是要保证,我们的json字符串一定不要存的太长,太大,这样的话,不管用哪个函数,效率都不会好
Hey!
我是小萝卜算子
在成为最厉害最厉害最厉害的道路上
很高兴认识你
推荐阅读:
SparkSql LogicalPlan的resolved变量
Spark sql 生成PhysicalPlan(源码详解)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)