
RAG实操教程: langchain+Milvus向量数据库创建你的本地知识库
本篇文章是 Milvus 向量数据库学习的总结篇,打造自己的知识库系统。
RAG是什么
RAG 是retrieval-augmented-generation的缩写,翻译为中文的意思就检索增强,以基于最新,最准确的数据建立LLM的语料知识库。
LLM 有哪些痛点
我们知道 LLM的知识库是通过现有的网络公开的数据作为数据源来训练的,现在公开的很多模型他们基于的训练数据会比我们现在网络上公开的数据早很多,那自然就会产生一种问题,网络上最新的数据和知识 LLM是不知道。还有一种情况就是很多企业他们对自己的数据的安全做的很好,也就是私有化数据(这些数据是有价值的,也是企业的立足之本)。这些数据网络上肯定是不存在,那自然 LLM也是不知道的。
我们在提问LLM 对于一些不知道的知识时候,LLM 很多时候是不知道如何回答问题的。甚至会对我们的问题进行胡诌随机回答,也就是瞎说。
为什么要用 RAG
如果使用预训练好的 LLM 模型,应用在某些情景下势必会有些词不达意的问题,例如问 LLM 你个人的信息,那么它会无法回答;这种情况在企业内部也是一样,例如使用 LLM 来回答企业内部的规章条款等。
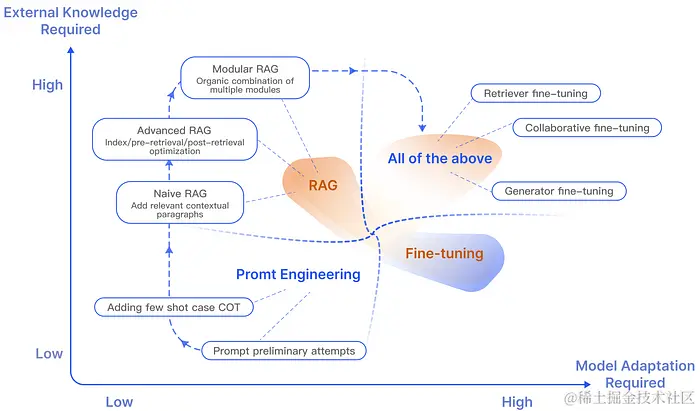
这种时候主要有三种方式来让 LLM 变得更符合你的需求:
-
Promt Enginerring: 输入提示来指导LLM产生所需回应。 例如常见的In-context Learning,通过在提示中提供上下文或范例,来形塑模型的回答方式。 例如,提供特定回答风格的示例或包含相关的情境信息,可以引导模型产生更合适的答案。 -
Fine tuning:这个过程包括在特定数据集上训练
LLM,使其响应更符合特定需求。 例如,一个EDA公司会使用其内部文件verilog code进行Fine tuning,使其能够更准确地回答关于企业内部问题。 但是Fine tuning需要代表性的数据集且量也有一定要求,且Fine tuning并不适合于在模型中增加全新的知识或应对那些需要快速迭代新场景的情况。 -
RAG (Retrieval Augmented Generation) : 结合了神经语言模型和撷取系统。 撷取系统从数据库或一组文件中提取相关信息,然后由语言模型使用这些信息来生成答案。 我们可以把
RAG想像成给模型提供一本书或者是文档、教程,让它根据特定的问题去找信息。 此方法适用于模型需要整合实时、最新或非常特定的信息非常有用。 但RAG并不适合教会模型理解广泛的信息或学习新的语言、格式。

目前的研究已经表明,RAG 在优化 LLM 方面,相较于其他方法具有显著的优势。
主要的优势可以体现在以下几点:
- RAG 通过外部知识来提高答案的准确性,有效地减少了虚假信息,使得产生的回答更加准确可信。
- 使用撷取技术能够识别到最新的信息(用户提供),这使得 LLM 的回答能保持及时性。
- RAG 引用信息来源是用户可以核实答案,因此其透明透非常高,这增强了人们对模型输出结果的信任。
- 透过获取与特定领域数据,RAG能够为不同领域提供专业的知识支持,定制能力非常高。
- 在安全性和隐私管理方面,RAG 通过数据库来存储知识,对数据使用有较好控制性。 相较之下,经过 Fine tuning 的模型在管理数据存取权限方面不够明确,容易外泄,这对于企业是一大问题。
- 由于
RAG不需更新模型参数,因此在处理大规模数据集时,经济效率方面更具优势。
不过虽然RAG有许多优势在,但这3种方法并不是互斥的,反而是相辅相成的。 结合 RAG 和 Fine tuning ,甚至 Promt Enginerring 可以让模型能力的层次性得增强。 这种协同作用特别在特定情境下显得重要,能够将模型的效能推至最佳。 整体过程可能需要经过多次迭代和调整,才能达到最佳的成效。 这种迭代过程涵盖了对模型的持续评估和改进,以满足特定的应用需求。

如何解决上面的问题
那如何让 LLM 知道这些最新/私有的数据的知识呢❓
那就是 RAG。通过将模型建立在外部知识来源的基础上来补充回答。从而提高 LLM生成回答的质量。
在基于 LLM实现的问答系统中使用 RAG 有三方面的好处:
- 确保
LLM可以回答最新,最准确的内容。并且用户可以访问模型内容的来源,确保可以检查其声明的准确性并最终可信。 - 通过将
LLM建立在一组外部的、可验证的事实数据之上,该模型将信息提取到其参数中的机会更少。这减少了LLM泄露敏感数据或“幻觉”不正确或误导性信息的机会。 RAG还减少了用户根据新数据不断训练模型并随着数据的变化更新训练参数的需要。通过这种方式企业可以减低相关财务成本。
现在所有基础模型使用的是 transformer 的 AI 架构。它将大量原始数据转换为其基本结构的压缩表示形式。这种原始的表示基础模型可以适应各种任务,并对标记的、特定于领域的知识进行一些额外的微调。
不过仅靠微调很少能为模型提供在不断变化的环境中回答高度具体问题所需的全部知识,并且微调的时间周期还比较长。所以科学家们提出了 RAG,让 LLM 能够访问训练数据之外的信息。RAG 允许 LLM 建立在专门的知识体系之上,以更准确的回答问题,减低幻觉的产生。
下面我将 langchain+Milvus 向量数据库创建你的本地知识库
安装 langchain
使用下面的命令可以快速安装 langchain 相关的依赖
python复制代码
pip install langchain
pip install langchain-community # 默认安装
pip install langchain-core # 默认安装
pip install langchain-cli # LangChain 命令行界面
pip install --upgrade --quiet pypdf # 安装pdf 加载器的依赖
文档加载器 pdf
在这篇文章中我们使用pdf作为我们的知识库文档。
加载文档的过程一般需要下面的步骤:
- 解析文档(
txt、pdf、html、url、xml、markdown、json)等等为字符串(langchain已经分装了几十种文档加载器,感兴趣的可以去参考官网)。 - 将字符串拆分为适合模型的对话窗口的大小,称为
chunk,chunk的大小需要依据模型的会话窗口设定。 - 保存拆分好的文档保存到向量数据库中。
- 设计向量数据库的数据库、集合、字段,索引等信息。
- 从向量数据库中检索需要的数据
这些步骤 langchain 已经给结合自己的工具连做好了封装,所以我们直接使用 langchain 来构建RAG。
python复制代码 from langchain_text_splitters import CharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
file_path = 'CodeGeeX 模型API.pdf'
# 初始化pdf 文档加载器
loader = PyPDFLoader(file_path=file_path)
# 将pdf中的文档解析为 langchain 的document对象
documents = loader.load()
# 将文档拆分为合适的大小
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
docs = text_splitter.split_documents(documents)
上面有两个参数需要注意下:
chunk_size=1000
表示拆分的文档的大小,也就是上面所说的要设置为多少合适取决于所使用LLM 的窗口大小。
- 如果设置小了,那么我们一次查询的数据的信息量就会少,势必会导致信息的缺失。
- 如果设置大了,一次检索出来的数据就会比较大,LLM 产生的token就会多,费用贵,信息不聚焦等问题。
chunk_overlap=100
这个参数表示每个拆分好的文档重复多少个字符串。
-
为什么要重复:如果拆分后的
chunk没有重复,很有可能会产生语义错误。比如这样一段文本:
....小米汽车的续航里程为700公里....如果文本正好从 700的哪里拆分开的话,那给人展示的时候就会产生酒究竟是700m还是700公里才歧义。 -
chunk_overlap如果设置比较大的值也不合适。这样每个文档的重复度就会很大,导致有用的信息就会减少,从而 LLM 回复的内容有可能缺少关键的信息。
Miluvs 向量数据库
关于 Milvui 可以参考我的前两篇文章
下面我们安装 pymilvus 库
python
复制代码 pip install --upgrade --quiet pymilvus
如果你使用的不是 Miluvs 数据库,那也没关系,langchain 已经给我们分装了几十种向量数据库,你选择你需要的数据库即可。本文中我们是系列教程中一篇,所以我们使用 Miluvs 向量库。
Embedding model

这里需要明确的两个功能是:
embedding Model所做中工作就是将image、Document、Audio等信息向量化.vectorBD负责保存多维向量
我这里使用 AzureOpenAIEmbeddings 是个收费的模型。有开源的 embedding Model可以部署在本地使用,如果你的机器性能足够好。如果要本地部署可以参考 docker 部署 llama2 模型 。
这里我使用 AzureOpenAIEmbeddings, 相关配置我放到了 .env 文件中,并使用 dotenv 加载。
ini复制代码 # AZURE config
AZURE_OPENAI_ENDPOINT=''
AZURE_OPENAI_API_KEY=''
OPENAI_API_VERSION=2024-03-01-preview
AZURE_DEPLOYMENT_NAME_GPT35 = "gpt-35-turbo"
AZURE_DEPLOYMENT_NAME_GPT4 = "gpt-4"
AZURE_EMBEDDING_TEXT_MODEL = "text-embedding-ada-002"
这里各位可以依据自己的情况设定即可。
向量化+存储
上面已经说明了向量库以及embedding model的关系。我们直接使用 langchain 提供的工具连完成 embedding 和store。
python复制代码 # 初始化 embedding model
from langchain_openai import AzureOpenAIEmbeddings
embeddings = AzureOpenAIEmbeddings()
python复制代码 from langchain_community.vectorstores import Milvus
vector = Milvus.from_documents(
documents=documents, # 设置保存的文档
embedding=embeddings, # 设置 embedding model
collection_name="book", # 设置 集合名称
drop_old=True,
connection_args={"host": "127.0.0.1", "port": "19530"},# Milvus连接配置
)
执行完成上面的代码,我们就将pdf中文档内容保存到 vector_db 中。

字段 vector 就是保存的多维向量。

Milvus search
虽然现在我们还没有使用 LLM 的任何能力,但是我们已经可以使用 vector 的搜索功能了。
python复制代码 query = "CodeGeeX模型API参数有那些?"
docs = vector.similarity_search(query)
print(docs)
python复制代码 # 带score搜索
query = "CodeGeeX模型API参数有那些?"
docs = vector.similarity_search_with_score(query, k=2)
print(docs)
similarity_search 与 similarity_search_with_score 的区别就是 similarity_search_with_score 搜索出来会带有一个 score 分值的字段,某些情况下这个 score 很有用。
langchain 不仅仅提供了基础的搜索能力,还有其他的搜索方法,感兴趣的可以去研究下。
RAG Chat
准备工作我们已经就绪,接下来我们使用langchain 构建我们的chat。
既然是聊天也就是我们跟模型的一问一答的形式来体现。这两年LLM的出现,关于 LLM 的知识里面我们估计最熟悉就是角色设定了。
- 什么是角色设定:下面 OpenAI 给出的回答:
在大型语言模型(LLM)中,角色设定指的是为AI助手创建一个特定的人格或身份。这个设定包括AI助手的说话风格、知识领域、价值观、行为方式等各个方面。通过这些设定,AI助手可以扮演不同的角色,比如专业的客服、风趣幽默的聊天对象,或是特定领域的专家顾问。
角色设定可以让AI助手的回答更加符合特定的场景和用户的期望。比如一个扮演医生的AI助手,会用专业术语解释病情,给出严谨的建议;而一个扮演朋友的AI助手,会用轻松的语气聊天,给出生活化的提示。
此外,角色设定还可以帮助限定AI助手的行为边界,避免其做出不恰当或有害的回应。设定明确的角色定位,有助于AI助手更好地理解自己的身份和职责,从而提供更加合适和有帮助的回答。
总的来说,角色设定让AI助手的对话更加自然和人性化,让用户获得更好的使用体验。同时它也是引导AI助手行为、确保其安全可控的重要手段。
在 chat中我们同样也需要以及简单的 prompt:
python复制代码 template = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know.
Question: {question}
Context: {context}
Answer:
"""
这个prompt中很明显我们设定了两个变量 question, context。
question: 这个会在后面被替换为用户的输入,也就是用户的问题。
context: 这个变量我们在后面会替换为向量检索出来的内容。
请思考下: 我们最后提供给LLm的内容只是用户的问题呢还是问题连带内容一起给到LLM?
chat chain
基于上面的内容我们基本的工作已经完成,下面就是我们基于 langchain构建chat。
python复制代码 import os
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template(template)
print(prompt)
# 加载chat model
from langchain_openai import AzureChatOpenAI
from langchain_core.runnables import RunnableParallel,RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
llm = AzureChatOpenAI(
azure_deployment=os.environ.get('AZURE_DEPLOYMENT_NAME_GPT35')
)
retriever = vector.as_retriever()
chain = (
RunnableParallel({"context": retriever, "question": RunnablePassthrough()})
| prompt
| llm
| StrOutputParser()
)
对于初学者可能有个问题就是:为什么这里有个 AzureChatOpenAI() 的实例 llm 。
这是个好问题,对于初学者会被各种 LLM 搞晕😵💫。
AzureOpenAIEmbeddings()这是一个负责将文本向化话的model。AzureChatOpenAI()是一个chat模型。负责聊天的 model。
基于 langchain 的链式调用构建 chat
python复制代码 chain = (
RunnableParallel({"context": retriever, "question": RunnablePassthrough()})
| prompt
| llm
| StrOutputParser()
)
这里看到 prompt中的两个变量context, question 会被替换。
为什么我们要写变量在 prompt中?
- 工程化:我们在做LLM相关的工作最重要的就是
prompt工程。这也是个重要的话题后面再说。 - 灵活:
测试
示例一:
python复制代码 question = "CodeGeeX模型API参数有那些?"
answer = chain.invoke(question)
print(answer)
输出:
python复制代码 CodeGeeX模型API的参数包括:
- prompt:用户输入的提示词
- max_tokens:模型输出最大tokens
- temperature:采样温度,控制输出的随机性
- top_p:另一种采样方法,模型考虑具有top_p概率质量tokens的结果
- stream:用于同步调用时,控制模型生成内容的返回方式,可以设置为false或true
示例二:
ini复制代码 question = "请给一个chat模型非流式请求示例"
answer = chain.invoke(question)
print(answer)
输出:
python复制代码 流式请求示例:
curl --location 'http://{ip}/prod/model/api/infillingStreaming' \
--header 'Content-Type: application/json' \
--data '{
"model": "codegeex",
"prompt": "package problem1;\nclass Solution{\n public int \nremoveDuplicates(int[] nums) {\n int cnt = 1;\n for (int i = 1; \ni < nums.length; ++i)\n if (nums[i] != nums[i - 1]) {\n \n nums[cnt] = nums[i];\n ++cnt;\n }\n return \ncnt;\n }\n}",
"max_tokens": 1024,
"temperature": 0.2,
"top_p": 0.95,
"stream": true
}'
对比pdf中的内容,很明显这个结果就是对的:

总结:
本文主要是 Milvus 向量数据实战总结。
- LLM 痛点以及解决方案
- RAG 是什么,为什么选用RAG。
langchain文档加载器,embedding model,chat model- 文档拆分的注意点,
embedding model,chat model区别。 - chat 示例代码。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)