
Bert系列:基于Bert微调快速实现多标签文本分类
内容摘要
- 多标签文本分类的应用场景
- 下游分类任务Bert微调网络结构
- 多标签分类的损失函数
- Bert多标签文本分类在PyTorch下的实现
多标签文本分类定义和应用场景
文本分类是指对形如文章,新闻,舆情,评论,用户输入的词条等自然语言文本数据,根据某个业务维度进行自动归类的技术。
多标签分类是指文本可以被归类为一种或者多种不同的类目下,同一个文本实例可以有多个类别标签。相比于多元分类(文本只能归属于一类),多标签文本分类在实际的场景中更为常见,例如
- 1.新闻根据主题归类,比如某篇描述国际冲突的新闻既可以归为国际政治,也可以归类到军事主题。
- 2.舆情根据事件类型归类,比如某篇描述土地污染的與情,涉及政府,工厂,开发商,业主等多方,该舆情可以被归类为环境污染处罚,重大事故损失,房企暴雷,消费者维权等多个事件类型。
- 3.用户输入根据意图归类,例如在用户在APP的搜索栏输入的短语包括“变形金刚”,用户的意图既可以是指电影,也可能是游戏,玩具。
Bert微调网络结构简述
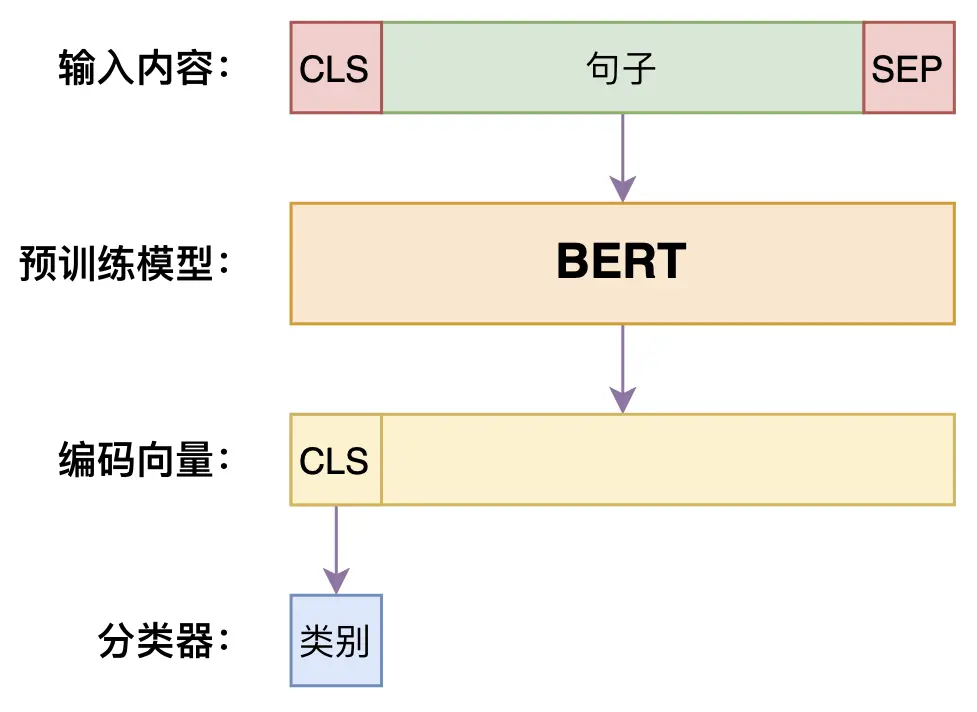
在文本分类场景,只需要将原始文本输入到Bert中,就可以利用到预训练的token embedding知识以及Bert的self Attention结构直接将文本转化为对应的特征向量,其中向量的第一个位置[CLS]单独用来给下游分类任务使用的,比如文本分类,情感分类,一对文本的相似匹配分类等等,Bert对下游分类任务的微调网络示意图如下

下游任务为分类的Bert微调网路结构
只需要将输入[CLS]+句子+[SEP]传入到BERT中,然后取出[CLS]位置的向量做分类就行,微调任务需要学习的参数包括最后一层的分类器,Bert中的token embedding,位置编码,Self Attention中的线性映射,以及各种全连接等。
多标签分类的损失函数
对于多元文本分类,文本只能属于唯一一类,此时通常采用Softmax交叉熵,而对于多标签分类场景,文本可以属于多个类别,此时Softmax交叉熵不再适用,一般采用每个类别的Sigmoid交叉熵的形式。令一共最大有n个候选类别,某条样本只属于其中的k个类别,则当n>>k时会出现类别不均衡问题,此时损失会受到(n-k)类稀疏部分的影响,导致有价值的k类别损失被平均掉,使得模型收敛缓慢。
令一共10个类别,一个批次下2条样本各命中其中的1个类别,用PyTorch来验证下类别不均衡问题的存在
>>> import torch
>>>
>>> y_pred = torch.tensor([[0.1] * 10, [0.1] * 10])
>>> y_true = torch.tensor([[1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0], [0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]])
>>>
>>> criterion1 = torch.nn.BCELoss(reduction="none")
>>> loss1 = criterion1(y_pred, y_true)
>>> criterion2 = torch.nn.BCELoss(reduction="mean")
>>> loss2 = criterion2(y_pred, y_true)
>>>
>>> loss1
tensor([[2.3026, 0.1054, 0.1054, 0.1054, 0.1054, 0.1054, 0.1054, 0.1054, 0.1054,
0.1054],
[0.1054, 2.3026, 0.1054, 0.1054, 0.1054, 0.1054, 0.1054, 0.1054, 0.1054,
0.1054]])
>>> loss2
tensor(0.3251)
loss1表明多标签分类的Sigmoid交叉熵会对每个类别位置计算一次loss,最后采用所有位置的均值作为该批次的最终损失,在该案例中剩下的9个位置的类别损失占了大部分的项数,导致实际命中的类别损失不明显,对比下二分类中交叉熵损失,仅拿出命中类目的预测值和实际标签值如下
>>> y_pred = torch.tensor([0.1, 0.1])
>>> y_true = torch.tensor([1.0, 1.0])
>>>
>>> criterion1 = torch.nn.BCELoss(reduction="none")
>>> loss1 = criterion1(y_pred, y_true)
>>> criterion2 = torch.nn.BCELoss(reduction="mean")
>>> loss2 = criterion2(y_pred, y_true)
>>>
>>> loss1
tensor([2.3026, 2.3026])
>>> loss2
tensor(2.3026)
二分类中交叉熵损失隔绝了剩余稀疏多标签的影响,该批次的最终损失为2.3026,明显高于多标签的0.3251。这种方式等同于Softmax交叉熵,代码如下
>>> y_pred = torch.tensor([[0.1] * 10, [0.1] * 10])
>>> y_true = torch.tensor([[1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0], [0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]])
>>>
>>> criterion1 = torch.nn.CrossEntropyLoss(reduction="none")
>>> loss1 = criterion1(y_pred, y_true)
>>> criterion2 = torch.nn.CrossEntropyLoss(reduction="mean")
>>> loss2 = criterion2(y_pred, y_true)
>>>
>>> loss1
tensor([2.3026, 2.3026])
>>> loss2
tensor(2.3026)
该种形式只会对实际标签为1的位置求损失,公式如下,其中S为输出得分,P为每个位置的实际onehot标签值

Softmax+交叉熵
作者从交叉熵公式的本质出发,将上面公式只定格在有意义的P(t)=1的位置,Softmax转化为目标预测值和其他位置预测值的差,形成logsumexp的形式,其中St代表目标标签为1的预测得分,Si为其他标签为0位置的预测得分

目标预测值和其他位置预测值的差
而logsumexp实际上是max函数的光滑近似,进一步推导如下

Softmax交叉熵近似
显然期望loss越小就是希望所有Sn-St的最大值最小化,如果St刚好是最大预测值,则St-St为最大值,此时loss接近为0,否则loss为一个正数,大小和最大预测值Sn和St的差距相关。
同理作者将把这种本质思想迁移到多标签分类上来,在单标签场景期望的是St比其他位置Sn都大,而多标签场景改为正例集合中所有得分都大于每个正例所对应的负例集合中的每个得分,公式如下

多标签分类Softmax
其中1为当i和j相同时的结果,作者额外引入了一个S0得分代表阈值,期望所有负例得分都能小于S0,所有正例得分都能大于S0,虽然这个log里面有4项,但是本质只是增加了一系列两两得分相减,最终还是被一个全局的max压缩拿到最大值作为loss。
上式可以把1拆开做因式分解,进一步转化为

多标签分类Softmax推导
如果指定阈值为0,那么就简化为

多标签分类Softmax简化
此公式本质上是比对所有标类别得分与非目标类别得分的差距,最后使用logsumexp聚合为最大值,自动隔绝了非最大值的影响,不存在类别不均衡问题。PyTorch实现代码如下
def multi_label_categorical_cross_entropy(y_true, y_pred):
"""
:param y_true: [batch_size, cate_size]
:param y_pred: [batch_size, cate_size]
:return:
"""
y_pred = (1 - 2 * y_true) * y_pred # 预测得分将正例乘以-1,负例乘以1
y_pred_neg = y_pred - y_true * 1e12 # 预测得分neg集合,将正例变为负无穷,负例保持不变
y_pred_pos = y_pred - (1 - y_true) * 1e12 # 预测得分pos集合,将负例变为负无穷,正例保持不变
zeros = torch.zeros_like(y_pred[..., :1])
y_pred_neg = torch.cat([y_pred_neg, zeros], dim=-1) # 0阈值
y_pred_pos = torch.cat([y_pred_pos, zeros], dim=-1)
neg_loss = torch.logsumexp(y_pred_neg, dim=-1)
pos_loss = torch.logsumexp(y_pred_pos, dim=-1)
return torch.mean(neg_loss + pos_loss)
其中第一行将预测得分将正例乘以-1,负例乘以1,目的是得到前项负例集合中的Si和后项正例集合中的-Sj,第二第三行代码负责将neg和pos集合位置的得分挑选出来,对非该集合的得分赋予一个负无穷大的值,使得e的指数次方接近于0从而对logsumexp没有影响,加入zeros的目的是构造前后两项log中的1,最终将两个logsumexp相加求平均即可获得整个批次的多分类Softmax交叉熵损失。
Bert多标签文本分类在PyTorch下的实现
采用新闻主题分类,一共94个类别,单条样本如下
text:'青岛市 大气 11月29日,莱西市政府组织店埠镇政府、环保局对信访件反映的问题进行了调查核实,有关情况如下: 经现场调查,该锅炉位于店埠镇政府院内北侧,检查时锅炉正在运行,未配套相应的污染防治设施,燃烧废气直接排放。'
label:['破坏生态环保']
(1)数据准备
基于PyTorch的Dataset,DataLoader快速将数据改造为批次格式,使用huggingface的Bert分词器将文本编码为数值id
def collate_fn(data):
texts, labels = [], []
for d in data:
texts.append(d[0])
one_hot_label = [0] * LABEL_NUM
for label in d[1]:
one_hot_label[LABEL2ID[label]] = 1
labels.append(one_hot_label)
# truncate, padding, token, convert_ids
encode = TOKENIZER.batch_encode_plus(texts, truncation=True, max_length=PRE_TRAIN_CONFIG.max_position_embeddings,
return_tensors="pt", padding=True)
input_ids = encode["input_ids"].to(DEVICE)
attention_mask = encode["attention_mask"].to(DEVICE)
token_type_ids = encode["token_type_ids"].to(DEVICE)
labels = torch.FloatTensor(labels).to(DEVICE)
return input_ids, attention_mask, token_type_ids, labels
train_data, val_data, test_data = random_split(total_data, (train_size, val_size, test_size))
train_loader = DataLoader(train_data, shuffle=True, drop_last=False, batch_size=32, collate_fn=collate_fn)
(2)模型构建
定义PyTorch网络模块,调用Bert预训练模型输出每个位置词的embedding,拿到第一个位置[CLS]用于分类,加一层线性层Linear得到每个类别的得分。
PRE_TRAIN = AutoModel.from_pretrained(PRE_TRAIN_PATH)
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.pre_train = PRE_TRAIN
self.linear = nn.Linear(in_features=PRE_TRAIN_CONFIG.hidden_size, out_features=LABEL_NUM)
nn.init.xavier_normal_(self.linear.weight.data)
def forward(self, input_ids, attention_mask, token_type_ids):
cls_emb = self.pre_train(input_ids, attention_mask)[0][:, 0, :]
linear_out = self.linear(cls_emb) # [None, 94]
return linear_out # [None, 94]
(3)损失函数
模型损失直接前文实现的multi_label_categorical_cross_entropy函数
prob = model(input_ids, attention_mask, token_type_ids)
loss = multi_label_categorical_cross_entropy(labels, prob)
如果采用二分类交叉熵的形式需要在model中对输出加上sigmoid,同时采用BCELoss来进行计算损失
...
def forward(self, input_ids, attention_mask, token_type_ids):
cls_emb = self.pre_train(input_ids, attention_mask)[0][:, 0, :]
linear_out = self.linear(cls_emb) # [None, 94]
return torch.sigmoid(linear_out) # [None, 94]
criterion = nn.BCELoss(reduction="mean")
loss = criterion(prob, labels)
(4)模型训练
采用每50步验证集连续10次f1值不上升作为早停条件,在学习率模块添加预热学习率,差分学习率等技巧
model = Model().to(DEVICE)
epochs = 20
pre_train_lr = 3e-5
optimizer, schedule = get_optimizer_schedule(model, pre_train_lr=pre_train_lr, other_lr=pre_train_lr * 100,
warm_step=50, total_step=len(train_loader) * epochs,
weight_decay=0.001)
handler = train_handler(model, model_path="./topic_cls/model.bin", acc_name="f1", num_windows=10)
early_stop_flag = False
for epoch in range(epochs):
for step, (input_ids, attention_mask, token_type_ids, labels) in enumerate(train_loader):
model.train()
optimizer.zero_grad()
prob = model(input_ids, attention_mask, token_type_ids)
loss = multi_label_categorical_cross_entropy(labels, prob)
loss.backward()
optimizer.step()
schedule.step()
step += 1
print("epoch: {}, step: {}, loss: {}".format(epoch + 1, step, loss.item()))
if step % 50 == 0:
loss_val, acc_val, pre_val, recall_val, f1_val, report = eval_metrics(model, val_loader)
print("[evaluation] loss: {} acc: {} pre: {} recall: {} f1: {}".format(loss_val, acc_val, pre_val,
recall_val, f1_val))
# print(report)
handler.get_step_metrics(f1_val)
if handler.early_stop():
early_stop_flag = True
print("early stop...")
break
if early_stop_flag:
break
(5)模型效果对比
分别采用逐位二分类交叉熵损失和多标签Softmax交叉熵两种损失来训练模型,早停后最佳模型在测试集合的表现如下
| 损失函数策略 | 逐位sigmoid交叉熵 | 多标签softmax交叉熵 |
|---|---|---|
| loss | 0.0046 | 0.3361 |
| accuracy | 0.8943 | 0.9155 |
| precision | 0.9371 | 0.9463 |
| recall | 0.9417 | 0.9594 |
| f1 | 0.9394 | 0.9528 |
在该数据集上使用多标签Softmax交叉熵的效果明显优于逐位二分类交叉熵。
从训练过程来看,每50步记录一次验集的f1提升情况,使用多标签Softmax交叉熵的模型能在训练早期快速收敛达到0.5以上的f1,而使用逐位二分类交叉熵的模型在第一个验证步长上f1还是停留在0,需要更多步长的训练才能稳定收敛到较高的f1水平。

验证集每50步的f1值
(6)模型预测应用
构建一个预测Predictor类,封装文本输出的预处理和模型调用预测, 在输出层加入sigmoid来获取每个类别的置信度。
class Predictor:
def __init__(self):
self.model = Model()
self.model.load_state_dict(torch.load(os.path.join(ROOT_PATH, "./topic_cls/model.bin")))
self.max_length = PRE_TRAIN_CONFIG.max_position_embeddings
self.tokenizer = TOKENIZER
self.device = "cpu"
self.model.to(self.device)
self.model.eval()
self.id2label = ID2LABEL
def preprocess(self, texts: list):
encode = self.tokenizer.batch_encode_plus(texts, padding=True, truncation=True, max_length=self.max_length,
return_tensors="pt")
input_ids = encode["input_ids"].to(self.device)
attention_mask = encode["attention_mask"].to(self.device)
token_type_ids = encode["token_type_ids"].to(self.device)
return input_ids, attention_mask, token_type_ids
def get_topic_type(self, texts):
assert isinstance(texts, list), "输入非文本集合"
res = [[] for _ in range(len(texts))]
input_ids, attention_mask, token_type_ids = self.preprocess(texts)
with torch.no_grad():
sigmoid_out = torch.sigmoid(self.model(input_ids, attention_mask, token_type_ids)).detach().cpu().numpy()
binary_out = (sigmoid_out > 0.5).astype(float)
axis_1, axis_2 = np.where(binary_out == 1)
for i, j in zip(axis_1, axis_2):
res[i].append({"topic_type": self.id2label[j], "conf": sigmoid_out[i, j]})
return res
输入一批文本预测主题类别如下
>>> predictor = Predictor()
>>> texts = ["青岛市 大气 11月29日,莱西市政府组织店埠镇政府、环保局对信访件反映的问题进行了调查核实,有关情况如下: 经现场调查,该锅炉位于店埠镇政府院内北侧,检查时锅炉正在运行,未配套相应的污染防治设施,燃烧废气直接排放。"]
>>> for i in predictor.get_event_type(texts):
>>> print(i)
>>> [{'event_type': '破坏生态环保', 'conf': 0.99510044}]
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词
- L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节
- L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景
- L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例
- L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)