
Canal底层结构和工作原理
Canal底层结构和工作原理
因需要记录mysql配置表变更记录,采用canal监听 binlog的方案
Canal是什么
译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
为什么使用它
1.Canal 会将binlog会根据配置过滤解析成特定对象,便于客户端解析存储
2.服务端的数据存储采用内存模式,吞吐量较大
3.允许get/ack异步处理,客户端可以多线程消费,提高消费速度
4.依赖zookeeper可实现高可用
5.支持通过配置与kafka等消息中间件结合使用
工作原理
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
canal 解析 binary log 对象(原始为 byte 流)
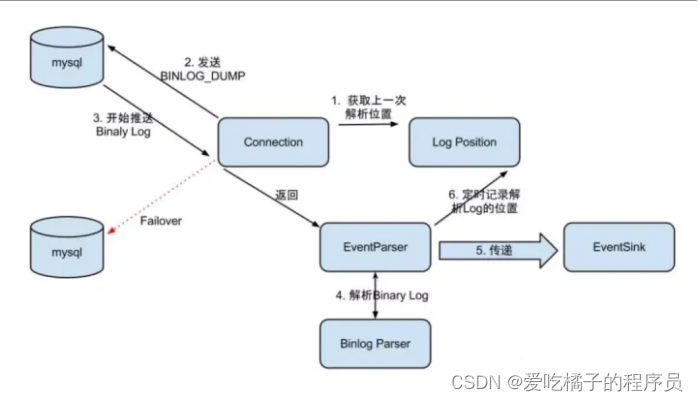
Canal server执行流程图
EventParser在向MySQL发送dump命令之前会先从Log Position中获取上次解析成功的位置(如果是第一次启动,则获取初始指定位置或者当前数据段binlog位点)。mysql接受到dump命令后,由EventParser从mysql上pull binlog数据进行解析并传递给EventSink(传递给EventSink模块进行数据存储,是一个阻塞操作,直到存储成功 ),传送成功之后更新Log Position

Canal架构

server 代表一个 canal 运行实例,对应于一个 jvm
instance 对应于一个数据队列 (1个 canal server 对应 1…n 个 instance )
instance 下的子模块
eventParser: 数据源接入,模拟 slave 协议和 master 进行交互,协议解析
eventSink: Parser 和 Store 链接器,可以对数据进行过滤、分发/路由(1:n)、归并(n:1)和加工
eventStore: 数据存储,实现模式是内存模式,内存结构为环形队列,由三个指针(Put、Get和Ack)标识数据存储和读取的位置。
metaManager: 增量订阅 & 消费信息管理器
EventSink设计

数据过滤:支持通配符的过滤模式,表名,字段内容等
数据路由/分发:解决1:n (1个parser对应多个store的模式)
数据归并:解决n:1 (多个parser对应1个store)
数据加工:在进入store之前进行额外的处理,比如join
EventStore设计

定义了3个cursor
Put : Sink模块进行数据存储的最后一次写入位置
Get : 数据订阅获取的最后一次提取位置
Ack : 数据消费成功的最后一次消费位置
get/ack异步化的好处:
1.减少因ack带来的网络延迟和操作成本 (99%的状态都是处于正常状态,异常的rollback属于个别情况,没必要为个别的case牺牲整个性能)
2.get获取数据后,业务消费存在瓶颈或者需要多进程/多线程消费时,可以不停的轮询get数据,不停的往后发送任务,提高并行化.
HA机制设计

大致步骤:
1.canal server要启动某个canal instance时都先向zookeeper进行一次尝试启动判断 (实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)
2.创建zookeeper节点成功后,对应的canal server就启动对应的canal instance,没有创建成功的canal instance就会处于standby状态
3.一旦zookeeper发现canal server A创建的节点消失后,立即通知其他的canal server再次进行步骤1的操作,重新选出一个canal server启动instance.
4.canal client每次进行connect时,会首先向zookeeper询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect.
5.Canal Client的方式和canal server方式类似,也是利用zokeeper的抢占EPHEMERAL节点的方式进行控制.

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)