
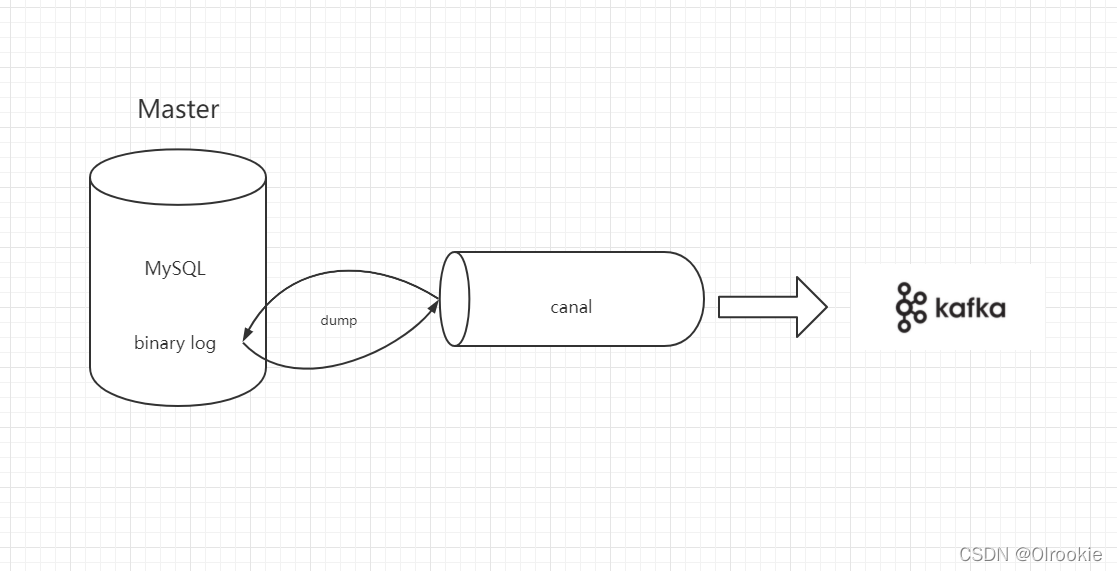
Canal监控MySQL数据到Kafka详细步骤(jdk+zookeeper+kafka+canal+mysql)
目录
一、前言
以下步骤是通过一台虚拟机搭建的单节点jdk+zookeeper+kafka+canal+mysql集群环境,搭建完成可通过canal监控mysql数据库数据发送到kafka。

二、环境准备
环境:虚拟机 centos7
全程为root操作权限
由于是虚拟机我们这里直接关闭防火墙,如果是服务器建议只开放指定端口(注意有的需要配置安全组)
1、在虚拟机中打开终端查看ip
ifconfig
2、用xshell连接上虚拟机
3、关闭防火墙
systemctl stop firewalld # 关闭防火墙
补充:
systemctl status firewalld # 查看防火墙状态
systemctl start firewalld # 打开防火墙
systemctl restart firewalld # 重启防火墙
三、安装JDK
1、查看是否有默认安装的jdk
java -version
2、卸载默认安装的jdk
yum list installed | grep java # 查询已安装的jdk信息
yum -y remove 自带openjdk # 卸载
3、创建文件夹放我们的安装包以及安装位置
cd /
mkdir app
cd app
mkdir installationPackage #放安装包
cd ../
mkdir path # 安装位置
4、将我们用到的压缩包通过xftp上传到服务器的/app/installationPackage目录下
5、解压jdk到/app/path目录下
tar -zxvf /app/installationPackage/jdk-8u221-linux-x64.tar.gz -C /app/path
6、进入到/app/path目录下将jdk1.8.0_221文件夹更名为jdk
mv jdk1.8.0_221 ./jdk
7、配置环境变量
vim /etc/profile
按i进入到insert模式,在文件最下方输入
# java 环境变量
export JAVA_HOME=/app/path/jdk
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
8、让环境变量生效
source /etc/profile
9、测试jdk是否安装成功
java -version
四、安装zookeeper
1、把zookeeper的压缩包传到/app/installationPackage目录下
2、解压到/app/path目录下
tar -zxvf apache-zookeeper-3.5.9-bin.tar.gz -C ../path/
3、进入到/app/path目录下将apache-zookeeper-3.5.9更名为zookeeper
cd /app/path
mv apache-zookeeper-3.5.9 /zookeeper
4、进入到/app/path/zookeeper/conf目录下,把zoo_sample.cfg 文件复制并重命名为 zoo.cfg 文件
cd /app/path/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
5、修改zoo.cfg文件
vim zoo.cfg
修改dataDir
dataDir=/app/path/zookeeper/data
# 在文件最下方加如下内容
server.0=localhost:2888:3888
1、 dataDir:存储内存中数据库快照的位置,除非另有说明,否则指向数据库更新的事务日志。注意:应该谨慎的选择日志存放的位置,使用专用的日志存储设备能够大大提高系统的性能,如果将日志存储在比较繁忙的存储设备上,那么将会很大程度上影像系统性能。
2、server.A=B:C:D
A:其中 A 是一个数字,表示这个是服务器的编号;
B:是这个服务器的 ip 地址;
C:Zookeeper服务器之间的通信端口;
D:Leader选举的端口。
我们需要修改的第一个是 dataDir ,在指定的位置处创建好目录。
第二个需要新增的是 server.A=B:C:D 配置,其中 A 对应下面我们即将介绍的myid 文件。B是集群的各个IP地址,C:D 是端口配置。
6、在/app/path/zookeeper目录下创建data文件夹(zoo.cfg中指定的dataDir路径)
mkdir data
7、进入到dataDir指定的文件夹下(/app/path/zookeeper/data)
vim myid
# 按i进入insert模式并输入zoo.cfg中server的数字
0
myid是zk集群用来发现彼此的标识,必须创建,且不能相同
8、配置环境变量
vim /etc/profile
按i进入到insert模式,在文件最下方输入
# zookeeper环境变量
export ZK_HOME=/app/path/zookeeper
export PATH=$PATH:$ZK_HOME/bin
9、让环境变量生效
source /etc/profile
10、启动zookeeper
zkServer.sh start
补充:
zkServer.sh start # 启动
zkServer.sh stop # 停止
zkServer.sh restart # 重启
zkServer.sh status # 查看节点状态
11、查看zookeeper是否启动成功
zkServer.sh status
单节点的会显示standalone,集群会显示leader或者flower
jps
#QuorumPeerMain 表示zookeeper在运行
五、安装Kafka
1、把kafka压缩包放到/app/installationPackage目录下
2、解压到/app/path目录下
tar -zxvf kafka_2.13-2.7.0.tgz -C ../path/
3、进入到/app/path目录下将kafka_2.13-2.7.0更名为kafka
cd /app/path
mv kafka_2.13-2.7.0/ kafka
4、修改配置文件 (server.properties) 注:按顺序来(从上到下找)
broker.id=0 # 对应zookeeper的myid
listeners=PLAINTEXT://localhost:9092
log.dirs=/app/path/kafka/data
log.retention.hours=1
log.cleanup.policy=delete
zookeeper.connect=localhost:2181
在内网部署kafka集群只需要用到listeners,内外网需要作区分时才需要advertised.listeners。
listeners:监听器,是为了告诉外部连接者要通过什么协议访问指定主机名和端口开放的kafka服务。
advertiesd.listeners:比listeners多了一个advertised,advertise表示宣称的、公布的,就是组监听器是Broker用于对外发布的。
advertised_listeners 是对外暴露的服务端口,真正建立连接用的是 listeners。
5、进入到并/app/path/kafka/bin/目录下修改kafka日志存储地址
vim kafka-run-class.sh
修改如下内容
LOG_DIR=/app/path/kafka/logs
6、进入到/app/path/kafka/config目录下配置kafka connect组件
vim connect-distributed.properties
修改如下内容
bootstrap.servers=localhost:9092
rest.port=8083
rest.advertised.port=8083
plugin.path=/app/path/kafka/connect # kafka connect插件路径
7、配置环境变量
vim /etc/profile
按i进入到insert模式,在文件最下方输入
#KAFKA环境变量
export KAFKA_HOME=/app/path/kafka
export PATH=$PATH:$KAFKA_HOME/bin
8、让环境变量生效
source /etc/profile
9、启动kafka
kafka-server-start.sh -daemon /app/path/kafka/config/server.properties
10、启动kafka connect
connect-distributed.sh -daemon /app/path/kafka/config/connect-distributed.properties
11、检查是否启动成功
jps
#kafka 表示kafka启动成功
#ConnectDistributed 表示kafka connect启动成功
12、创建生产者和消费者测试kafka
创建主题
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 -topic 主题名称
创建生产者
kafka-console-producer.sh --broker-list localhost:9092 --topic 主题名称
创建消费者
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic 主题名称
六、安装MySQL
1、卸载已有mysql
# 检查 MariaDB 是否安装
yum list installed | grep mariadb
# 卸载全部 MariaDB 相关
yum -y remove mariadb*
# 查看已经安装的服务
yum list installed | grep -i mysql # -i 无论大小写
# 删除查出来的服务(去掉后缀)
yum -y remove myql名字
# 查看残留的目录:
whereis mysql
# 删除相关文件:
rm –rf /usr/lib64/mysql
rm –rf /usr/my.cnf
rm -rf /var/lib/mysql
# 如果这个目录如果不删除,再重新安装之后,密码还是之前的密码,不会重新初始化!
2、把mysql压缩包放到/app/installationPackage目录下
3、将mysql压缩包解压到/usr/local目录下
tar -zxvf mysql-5.7.26-linux-glibc2.12-x86_64.tar -C /usr/local
4、进入到/usr/local目录下并重命名mysql-5.7.26-linux-glibc2.12-x86_64
cd /usr/local
mv mysql-5.7.26-linux-glibc2.12-x86_64 mysql
5、创建mysql用户组和用户
groupadd mysql
useradd -r -g mysql mysql
6、创建数据目录并赋予权限
mkdir -p /data/mysql #创建目录
chown mysql:mysql -R /data/mysql #赋予权限
7、配置my.cnf
vim /etc/my.cnf
按i进入到insert模式,在文件中输入
[mysqld]
bind-address=0.0.0.0
port=3306
user=mysql
basedir=/usr/local/mysql
datadir=/data/mysql
socket=/tmp/mysql.sock
log-error=/data/mysql/mysql.err
pid-file=/data/mysql/mysql.pid
#character config
character_set_server=utf8mb4
symbolic-links=0
explicit_defaults_for_timestamp=true
8、进入/usr/local/mysql/bin/目录下,初始化数据库
cd /usr/local/mysql/bin/
./mysqld --defaults-file=/etc/my.cnf --basedir=/usr/local/mysql/ --datadir=/data/mysql/ --user=mysql --initialize
9、查看密码
cat /data/mysql/mysql.err
10、将mysql.server放到/etc/init.d/mysql中,然后就可以使用此命令启动/关闭 mysql:
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql
11、启动mysql
service mysql start # 启动mysql
补充:
service mysql stop # 停止mysql
service mysql restart # 重启mysql
出现Starting MySAL… SUCCESS!表示安装成功
12、登录mysql
./mysql -u root -p #bin目录下
# 输入上面拿到的初始密码
13、修改默认密码
SET PASSWORD = PASSWORD('123456');
ALTER USER 'root'@'localhost' PASSWORD EXPIRE NEVER;
FLUSH PRIVILEGES; # 刷新使其生效
14、开启远程访问
use mysql #进入到mysql库中
update user set host = '%' where user = 'root'; # 使root能再任何host访问
FLUSH PRIVILEGES; # 刷新
15、建立软链接,不用到mysql的bin目录下执行mysql命令
ln -s /usr/local/mysql/bin/mysql /usr/bin
此时已经可以通过数据库工具来连接该数据库了
16、此时可以在数据库中新建一个database并在该database下新建一个表,作为我们一会儿要监控的表
七、安装canal服务端(canal监控mysql数据发送到kafka)
1、把canal压缩包放到/app/installationPackage目录下
2、进入到/app/path/目录下 创建canal_server文件夹
cd /app/path
mkdir canal_server
3、解压到/app/path/canal_server目录下
tar -zxvf canal.deployer-1.1.4.tar.gz -C ../path/canal_server
4、开启myql Binlog写入功能,配置 binlog-format 为 ROW 模式
vim /etc/my.cnf
按i进入到insert模式,在文件最下方输入
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
注意:针对阿里云 RDS for MySQL , 默认打开了 binlog , 并且账号默认具有 binlog dump 权限 , 不需要任何权限或者 binlog 设置,可以直接跳过这一步
5、授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%'; #账号密码都为canal
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES; # 刷新
这里建议可以重启一下mysql服务,以免改动未生效。
6、修改监控配置
vim /app/path/canal_server/conf/example/instance.properties
按i进入到insert模式,在文件最下方输入
canal.instance.master.address = localhost:3306 # 数据库地址
canal.instance.dbUsername = canal # 数据库账号
canal.instance.dbPassword = canal # 数据库密码
canal.instance.filter.regex = 数据库名.要监控的表名
配置里默认Kafka主题为example,可自行更改,如果使用默认主题,要记得再kafka中创建这个主题
7、修改kafka相关配置
vim /app/path/canal_server/conf/canal.properties
按i进入到insert模式,在文件最下方输入
canal.serverMode = kafka # 发送到kafka
canal.mq.servers = localhost:9092 # kafka集群地址
8、进入到/app/path/canal_server/bin目录下
sh ./startup.sh # 启动
sh ./stop.sh # 停止
八、测试是否可以监控到数据
1、我们前面已经mysql数据库中新建好数据库以及我们要中的表并且已经将其填写到了canal的instance.properties中
2、新建kafka主题
kafka-topics.sh --create --zookeeper 你的ip:2181 --replication-factor 3 --partitions 1 -topic 主题名称
3、创建kafka消费者
kafka-console-consumer.sh --bootstrap-server 你的ip:9092 --topic 主题名称
4、在我们监控的表中新增、修改、删除数据、修改表结构
5、我们的kafka消费者都会传来对应的数据
九、结语
如果上面你的kafka消费者能传来你对该表的增删改,那么恭喜你。你已经完成了以上环境的搭建,给自己鼓鼓掌吧。
由于我自己才学没多久,在搭建的过程中遇到好多问题,踩过好多坑,所以把搭建步骤尽可能详细地记录下来,当作自己学习的一个记录,也希望能够帮到有需要的人。
如果以上步骤中有什么问题或需要补充的话,也希望各位大佬不吝赐教。最后,祝大家工作顺利,心想事成!

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)