构建系统简介以及分布式Ninja实现原理
cloudbuild分布式
构建系统介绍
构建系统(build system)是用来从源代码生成用户可以使用的目标(targets)的自动化工具。目标可以包括库、可执行文件、或者生成的脚本等等。常用的构建系统包括GNU Make、GNU autotools、CMake、Apache Ant(主要用于JAVA)。
make
GNU make 是一款较早期编译系统,开发者使用 Makefile 文件描述源码的编译规则和目标的依赖关系,使用 make 命令即可自动化完成项目编译。但人工编写 Makefile 文件十分繁琐,需要针对不同平台编写不同的 Makefile。make 工具最主要也是最基本的功能:就是通过 makefile文件来描述源程序之间的相互关系并自动维护编译工作。而 makefile文件 需要按照某种语法进行编写,文件中说明如何编译各个源文件,并连接生成可执行文件,并要求定义源文件之间的依赖关系。当执行 make 命令时,它会在当前目录中查找名为 Makefile 的文件。它会解析 Makefile ,并构建依赖树。根据在命令行上指定的 make 目标,make 检查该目标的依赖文件是否存在;如果它们存在,就比较文件时间戳,判断它们的更新时间是否在目标之后。
cmake
make需要根据makefile自动构建项目,但是软件规模大了之后makefile的编写也是及其繁琐且易出错的事情。于是有了makefile生成工具,例如CMake,AutoMake等,这类工具称之为元构建系统(Meta-Build System)。CMake就是一款元构建系统,它是一个开源、跨平台的编译、测试和打包工具,它使用比较简单的语言描述编译、安装的过程,输出Makefile或者project文件,再去执行构建。它能方便地管理依赖多个库的目录层次结构并生成 Makefile 配合使用 make 编译项目。CMake 工具解决了项目对不同平台的适配问题,但却未解决make 的执行效率低下的问题。
Ninja
Ninja 是一个专注于速度的小型构建系统。它与其他构建系统在两个主要方面有所不同:一是它被设计为由更高级别的构建系统生成 .ninja 文件作为其输入;二是它被设计为尽可能快地执行构建务。
为什么需要 Ninja 这么一个新的构建系统?如果说其他构建系统是高级语言的话,那么 Ninja 的目标是成为汇编语言。尽管 Ninja 的工程文件是可读的,但更多场合下,往往是从其他构建系统的工程文件自动生成 Ninja 的工程文件。Ninja 的工程文件可以快速地进行增量构建。
Ninja 将文件的相互依赖关系(通常是源代码和输出可执行文件之间的依赖关系)作为输入,并快速协调构建它们。Ninja 包含描述任意依赖关系图所需的最基本功能,但它的语法不支持表达复杂的决策,因为构建系统一旦需要做决策就会变慢。
Ninja 与生成 .ninja 输入文件的独立程序配合起来使用。独立的 .ninja 文件生成程序(如 autotools 项目中的 ./configure)可以分析系统依赖关系,并预先做出尽可能多的决策,以便使增量构建保持快速。除了自动工具之外,甚至诸如“我应该使用哪个编译器标志?”或“我应该构建调试版本或发布版本?”之类的构建时决策也交给 .ninja 生成器来负责。这是 Ninja 构建速度特别快的主要原因。
特别说明一下,Ninja 比其他构建系统更快,因为它非常非常简单。当你创建项目的 .ninja 文件时必须明确地告诉 Ninja 需要执行的操作。
分布式编译系统
distcc
distcc 是一款开源的分布式 C/C++ 编译器,是早期的分布式编译器,已经正确编译了许多软件和系统,例如 Linux Kernel、GNOME 等。distcc 通过向集群中的主机分配编译任务来加速编译[14],根据 Rosen Matev 的测试,使用 4 核虚拟机,本地编译与 80 核机器上的远程编译进行比较,在编译 Gaudi(LHCb 堆栈的基础) 时至少实现了 10 倍时间加速,其中瓶颈已经变成了非分布式工作比如链接。
Yadcc
Yadcc 是一套腾讯广告自研的工业级 C++ 分布式编译系统,2021 年 6 月正式开源。Yadcc 主要通过本地预处理、集群编译和分布式缓存对编译进行加速,Yadcc 集群中的每一个机器都可在编译时提交任务,并且在空闲时间贡献一部分算力到集群中。
在 Yadcc 集群中提供具备全局视图的中心调度器和专门的缓存服务器。调度器负责将编译任务分配到机器上和负载均衡,缓存服务器使用 2 级缓存对已经执行的任务进行缓存。当其它节点请求同一任务时,即可直接返回无需编译。
Yadcc 将客户端伪装为编译器进行使用,Yadcc 会按照命令行对源代码进行预处理,得到一个自包含的预处理结果,以预处理结果、编译器签名、命令行参数等为哈希,查询缓存。如果命中,直接返回结果。如果不命中,就请求调度器获取一个编译节点,分发任务去编译,等待直到从编译集群中得到编译结果,并更新缓存
Bazel
Bazel是Google开源的,类似于Make、Maven或Gradle的构建和测试工具。Bazel 是基于 Artifact 的构建系统。Artifact 是指源文件或者生成的文件,对于 Bazel 的每一个 Action 来说,它的输入的 Artifact 都是确定的,因此它输出的Artifact 也是确定的,不论这个 Action 是在哪种环境下运行亦或是多次运行输出都是确定的。因此对于 Bazel 来说,一个 Action 可以在本地沙盒执行得到结果,也可通过远程执行得到结果。
Bazel 与其他构建系统项目有三点优势:一是Bazel使用高层次的构建语言,抽象出了库、脚本、二进制数据集等概念,在编写构建脚本时更加方便。二是Bazel支持高度并行构建和精准的增量构建。Bazel在构建过程中能够缓存所有已经完成的工作步骤,并且跟踪文件内容、构建命令的变动情况,避免重复构建。三是Bazel扩展性好,除了原生支持C/C++,Java等语言外,支持扩展其他语言。
Bazel的构建时主要包括3个阶段
- 加载阶段,Bazel加载并执行项目中所有的.bzl和所有的BUILD。规则进行实例化,并加入目标图中。
- 分析阶段,会执行定义规则的implementation函数,实例化actions,将加载阶段的目标图转化为构建图。
- 执行阶段,根据分析阶段生成的依赖关系,调用编译器、shell命令等,执行构建图中的actions。
Bazel使用首先需要定义工作空间,即在工作目录下新建WORKSPACE文件,工作空间中除WORKSPACE文件外还包含源码和构建结果的符号连接。工程如何构建由BUILD文件描述,BUILD存在于每个包中,定义当前包的构建要素,例如使用何种Rule构建特定的目标。Bazel有一套自己的代码组织方式,需要严格明确项目的工具链和依赖等信息,各大公司若想要对接 Bazel需要花费极大精力对自身项目进行改造。
CloudBuild(基于Ninja的分布式构建系统)
我们团队基于Ninja实现了分布式构建系统,CloudBuild。可参考https://gitee.com/cloudbuild888
Ninja并行执行编译命令
当编译开始后,编译客户端首先读取项目下的构建清单 (默认是 build.ninja文件) 解析并生成依赖图。Ninja 生成的依赖图是用构建清单中所有的 build 语句代表的边组成一张无向无环图。Ninja项目的依赖图如下所示: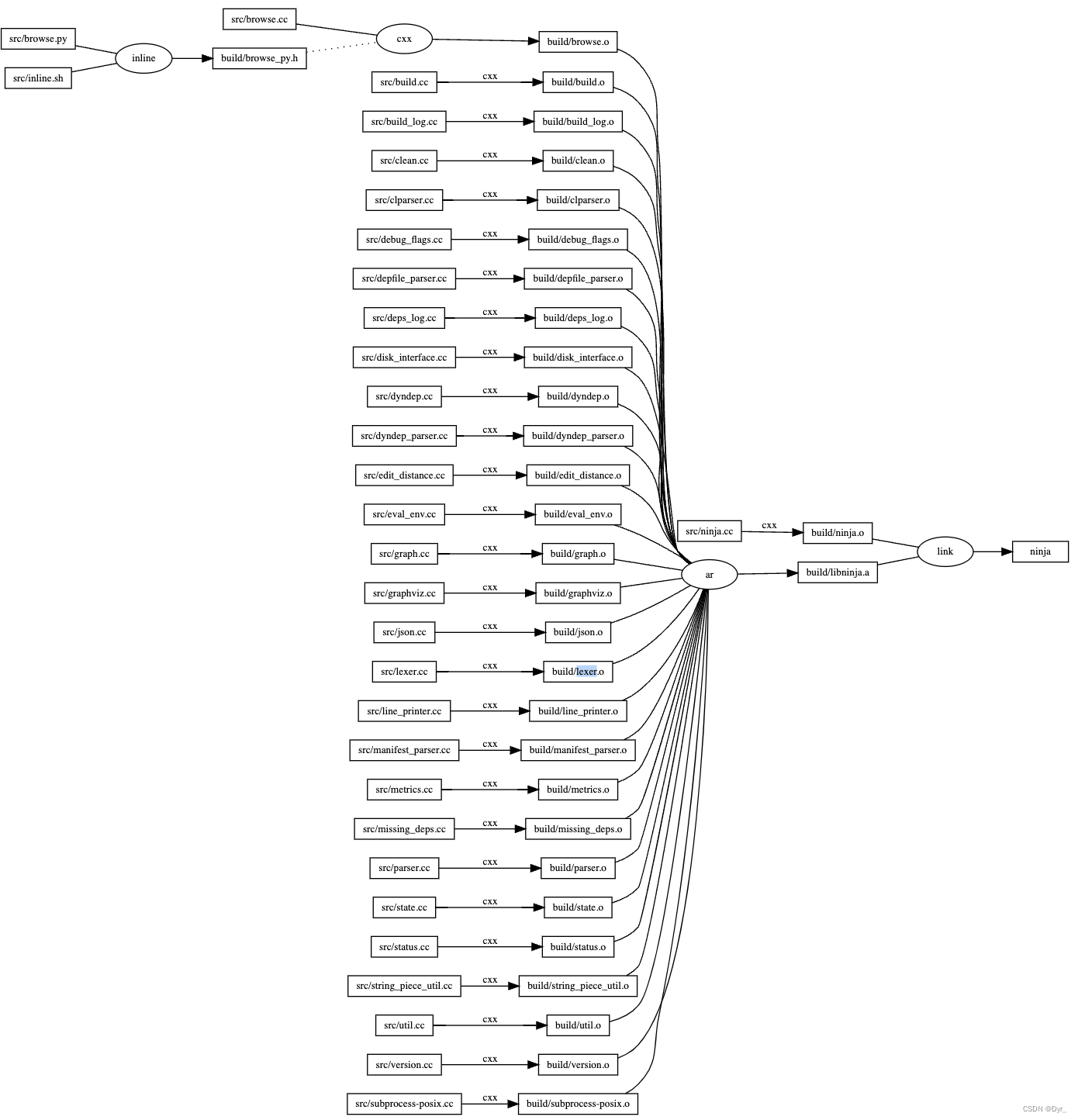
在这个图中,节点由矩形标出,椭圆形状和cxx都代表一条rule,边的输入按照rule生成输出。Ninja在添加编译目标(AddTarget)后得到了两条边集合 ready和want。其中ready记录可以执行的边(所有输入都已经就绪),want表示为了编译出目标需要执行的边。以上述DAG图为例,构建过程如下,节点Ninja的输入边link需要执行,但是link的输入文件build/ninja.o和build/libninja.a都不存在,故这两个都放入了want集合,接着按照深度优先搜索的方法,执行build/ninja.o,发现其所需src/ninja.cc已经存在,则可将该边放入ready队列并回溯检查下一个节点build/libninja.a以此类推。深度优先搜索结束后,ready集合中的边必然没有相互依赖的关系,因此可以并发的执行。在Ninja构建过程中会动态的在EdgeFinished将want中输入全部存在的边加入到ready队列。
remoteapi介绍
Remote Execute API 官网文档
Remote Execution API 提供了一种远程执行机制,以便众多客户端可以共享它,并允许作业的实际执行发生在分布式网络中,而不只是在执行构建的机器上,允许构建的大规模并行化并显着的加速。
API 的核心是摘要消息,用于获取唯一引用blob(二进制大对象,或只是一个字节序列)的哈希。由于 proto 消息可以编码为 blob,我们可以使用 Digests 不仅引用上传的文件,还可以引用我们希望用于与服务器通信的各种 proto 消息。
Execute Service
Execute Service提供远程执行服务,在向远程执行服务器提交请求之前,构建客户端首先需要确保所有输入文件在 CAS 中都可用,远程执行服务器和最终接受任务的worker将能够访问他们。
Content Addressable Storage Service
ContentAddressableStorage 服务用于存储操作的输入和输出文件。 内容可寻址存储(简称CAS)是通过其哈希寻址内容的存储层,这使得为内容生成唯一密钥变得容易,也确保内容不会意外上传错误的密钥,因为 CAS 将拒绝未正确散列的内容。 CAS 是远程执行/分布式构架构的关键元素,并在不同组件之间共享。 它本质上是一个存储任意二进制数据的数据库。每个条目包括一个二进制 blob,都由一个 Digest 索引:一个包含数据散列的值(通常是 SHA-256)及其大小(以字节为单位)。 虽然单独的哈希足以唯一地标识一个 blob,但具有大小允许实现轻松预测服务特定请求所需的资源。
CAS 支持两种基本操作:创建新条目和获取现有条目。 对于后者,有必要知道要获取的 blob 的哈希值,因此它被称为内容可寻址。 在整个 REAPI 中都使用摘要来引用特定的数据。
由于对实际内容没有限制,CAS服务器不仅可以存储源文件和结果,还可以作为Remote Execution API的protobuf消息的缓存。 (例如,表示树结构的目录消息与其中包含的文件一起存储。)因此,将CAS 中的条目称为 blob 而不是文件。
ActionCache
ActionCache 服务负责将 Action 映射到描述其过去执行的 ActionResult,用于查询给定Action 是否已经执行。在远程执行完成后,服务端会返回ActionResult,但不会直接返回output本身内容,客户端按需从cas中获取。客户端应该在向远程执行服务器发送一个Action之前,使用该Action摘要的 查询ActionCache,如果该Action在缓存中命中,则可以直接获取结果而无需进行任何计算。
Capabilities Server
远程执行客户端可以使用 Capabilities 服务来查询各种服务器属性,以便自行配置或返回有意义的错误消息。
远程执行服务
buildbuddy

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)