
SegFormer:Simple and Efficient Design for SemanticSegmentation with Transformers阅读笔记
主要讲一下本文最大的两个创新点 和 一些细节
1.无位置编码 分层的transformer encoder
这里要先说一下VIT留下来的缺点
1.ViT的结构不太适合做语义分割,因为ViT是柱状结构,全程只能输出固定分辨率的feature map, 比如1/16, 这么低的分辨率对于语义分割不太友好,尤其是对轮廓等细节要求比较精细的场景
2.在处理大型图像时 计算量大 ViT的柱状结构意味着一旦增大输入图片或者缩小patch大小,计算量都会成平方级提高,对显存的负担非常大,32G的V100也可能hold不住
3.位置编码. ViT 用的是固定分辨率的positional embedding, 但是语义分割在测试的时候往往图片的分辨率不是固定的,这时要么对positional embedding做双线性插值,这会损害性能, 要么做固定分辨率的滑动窗口测试,这样效率很低而且很不灵活
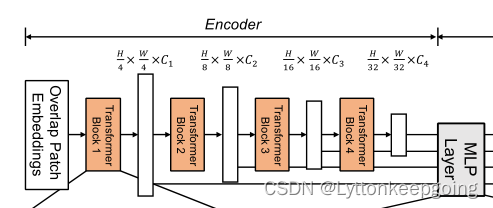
首先是Hierarchical Transformer Encoder
不像VIT只能获得单一的feature map,该模型的目标就是输入一张image,产生和CNN类似的多层次的feature map。通常这些多层的feature map提供的高分辨率的粗特征和低分辨率提供的精细特征可以提高语义分割的性能。用数学语言来表达就是
Input resolution:H×W×3;
我们进行patch merge,得到分辨率为![]() 的 hierarchical feature map i代表四次encoder 第一个encoder 就是四分之一的H W 对应结构图中的这一部分 这样可以获得多尺度的特征
的 hierarchical feature map i代表四次encoder 第一个encoder 就是四分之一的H W 对应结构图中的这一部分 这样可以获得多尺度的特征

然后就是 Overlapped Patch Merging
VIT中将一个输入N*N*c的image,合并为1*1*C的向量。利用这种特性,很容易的可以将特征图的分辨率缩小两倍,如![]() 这个过程最初用来组合non-overlapping的图像或特征块,但它不能保持这些patch周围的局部连续性。所以我们使用overlapping的图像来融合,这样就可以保证patch周围的局部连续性了。为此我们设置的三个参数K,S,P。K是patch size,S是stride,P是padding。在实验中我们分别设K,S,P为(7,4,3)和(3,2,1)的参数来执行overlapping的图像的融合过程并得到和non-overlapping图像融合一样大小的feature 其实这里不是很懂 为什么用overlapped embedding
这个过程最初用来组合non-overlapping的图像或特征块,但它不能保持这些patch周围的局部连续性。所以我们使用overlapping的图像来融合,这样就可以保证patch周围的局部连续性了。为此我们设置的三个参数K,S,P。K是patch size,S是stride,P是padding。在实验中我们分别设K,S,P为(7,4,3)和(3,2,1)的参数来执行overlapping的图像的融合过程并得到和non-overlapping图像融合一样大小的feature 其实这里不是很懂 为什么用overlapped embedding
最后就是最重要的Mix-FFN
VIT使用位置编码PE(Position Encoder)来插入位置信息,但是插入的PE的分辨率是固定的,这就导致如果训练图像和测试图像分辨率不同的话,需要对PE进行插值操作,这会导致精度下降。为了解决这个问题CPVT(Conditional positional encodings for vision transformers. arXiv, 2021)使用了3X3的卷积和PE一起实现了data-driver PE。我们认为语义分割中PE并不是必需的。引入了一个 Mix-FFN,考虑了padding对位置信息的影响,直接在 FFN (feed-forward network)中使用 一个3x3 的卷积,MiX-FFN可以表示如下:![]() 对应模型图中的
对应模型图中的

 其中X in是从self-attention中输出的feature。Mix-FFN混合了一个3*3的卷积和MLP在每一个FFN中。即根据上式可以知道MiX-FFN的顺序为:输入经过MLP,再使用Conv3*3操作,然后经过一个GELU激活函数,再通过MLP操作,最后将输出和原始输入值进行叠加操作,作为MiX-FFN的总输出。在实验中作者展示了3*3的卷积可以为transformer提供PE
其中X in是从self-attention中输出的feature。Mix-FFN混合了一个3*3的卷积和MLP在每一个FFN中。即根据上式可以知道MiX-FFN的顺序为:输入经过MLP,再使用Conv3*3操作,然后经过一个GELU激活函数,再通过MLP操作,最后将输出和原始输入值进行叠加操作,作为MiX-FFN的总输出。在实验中作者展示了3*3的卷积可以为transformer提供PE
为什么这样就能代替PE?? 3x3卷积怎么提供位置信息
2.将轻量级的MLP作为decoder
使用这种简单编码器的关键点是作者提出的多级Transformer Encoder比传统的CNN Encoder可以获得更大的感受野ALL-MLP由四步组成。第一,从MIT中提取到的多层次的feature,记作Fi,通过MLP层统一channel数。第二,Fi被上采样到四分之一大小,然后再做一次concat操作。第三,MLP对concat之后的特征进行融合。最后,另一个MLP对融合的特征进行预测,输出分辨率为![]()
对应图中
对应过程为
然后解释了为什么设置MLP会有效 也叫有效感受野分析

即使在最深的阶段,deeplabv3+的ERF还是非常小
SegFormer的编码器自然地产生local attentions,类似于较低阶段的卷积,同时能够输出高度non-local attentions,有效地捕获编码器第四阶段的上下文。
将图片放大,MLP的MLPhead阶段(蓝框)明显和Stage-4阶段(红框)的不同,可以看出local attentions更多了
本文中的decoder设计受益于transformer中的non-local attention,并且在不导致模型变复杂的情况下使得感受野变大。但是相同的decoder接在CNN的backbone的时候效果并不是很好,因为Stage4的感受野有限。更重要的是在设计decoder的时候利用了Transformer的induced feature,该特性可以同时产生高度的local attention和低层的non-local attention,通过互补这两种attention,编码器在增加少量参数的情况下来实现互补和强大的表现
这里又有一个感受野的问题 为什么Transformer Encoder的感受野比CNN大??
后面就是一些实验的细节 就不讲了
三个遗留问题 希望明天能解决 3X3 AND 感受野 AND overlapped Embedding

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)