
【自然语言处理 | Transformers】Transformers 常见算法介绍合集(二)
文章目录
一、DistilBERT
DistilBERT 是一个基于 BERT 架构的小型、快速、廉价且轻量级的 Transformer 模型。 在预训练阶段进行知识蒸馏,将 BERT 模型的大小减少 40%。 为了利用大型模型在预训练过程中学到的归纳偏差,作者引入了结合语言建模、蒸馏和余弦距离损失的三重损失。

二、ELECTRA
ELECTRA 是一种采用新预训练方法的变压器,可训练两个变压器模型:生成器和鉴别器。 生成器替换序列中的标记 - 作为掩码语言模型进行训练 - 鉴别器(ELECTRA 贡献)尝试识别序列中哪些标记被生成器替换。 此预训练任务称为替换标记检测,是屏蔽输入的替代方法。

三、Electric
Electric 是一种基于能量的完形填空模型,用于文本表示学习。 与 BERT 一样,它是给定上下文的 token 的条件生成模型。 然而,Electric 不使用屏蔽或输出上下文中可能发生的令牌的完整分布。 相反,它为每个输入标记分配一个标量能量分数,指示它被赋予上下文的可能性。


四、Longformer
Longformer 是一种改进的 Transformer 架构。 传统的基于 Transformer 的模型由于其自注意力操作而无法处理长序列,自注意力操作与序列长度呈二次方缩放。 为了解决这个问题,Longformer 使用了一种随序列长度线性缩放的注意力模式,从而可以轻松处理数千个标记或更长的文档。 注意力机制是标准自注意力的直接替代品,并将局部窗口注意力与任务驱动的全局注意力结合起来。
使用的注意力模式包括:滑动窗口注意力、扩张滑动窗口注意力和全局+滑动窗口。 这些可以在此页面的组件部分中查看。

五、mT5
mt5 是 T5 的多语言变体,在新的基于 Common Crawl 的数据集上进行了预训练,涵盖101语言。

六、Pathways Language Model(PaLM)
PaLM(Pathways 语言模型)在仅解码器设置中使用标准 Transformer 模型架构(Vaswani 等人,2017)(即每个时间步只能关注自身和过去的时间步),并进行了一些修改。 PaLM 在 7800 亿个代币上被训练为一个 5400 亿个参数、密集激活的自回归 Transformer。 PaLM 利用 Pathways(Barham 等人,2022),可以跨数千个加速器芯片对超大型神经网络进行高效训练。

七、Performer
Performer 是一种 Transformer 架构,它可以以可证明的精度来估计常规(softmax)全秩注意力 Transformer,但仅使用线性(而不是二次)空间和时间复杂度,而不依赖于任何先验,例如稀疏性或低秩性。 Performers 是与常规 Transformer 完全兼容的线性架构,并具有强大的理论保证:注意力矩阵的无偏或近无偏估计、均匀收敛和低估计方差。 为了近似 softmax 注意力核,表演者使用通过正正交随机特征的快速注意力方法 (FAVOR+),利用新方法来近似 softmax 和高斯核。

八、Transformer-XL
Transformer-XL(意为超长)是一种 Transformer 架构,它将递归的概念引入了深度自注意力网络。 Transformer-XL 不会重新计算每个新段的隐藏状态,而是重用在先前段中获得的隐藏状态。 重用的隐藏状态充当当前段的内存,从而在段之间建立循环连接。 因此,对非常长期的依赖关系进行建模变得可能,因为信息可以通过循环连接传播。 作为一项额外的贡献,Transformer-XL 使用了一种新的相对位置编码公式,该公式可以泛化到比训练期间观察到的注意力长度更长的注意力长度。

九、DeBERTa
DeBERTa 是一种基于 Transformer 的神经语言模型,旨在通过两种技术改进 BERT 和 RoBERTa 模型:解开注意力机制和增强型掩码解码器。 解缠结注意力机制是每个单词使用分别编码其内容和位置的两个向量不变地表示,并且单词之间的注意力权重使用其内容和相对位置的解缠结矩阵计算。 增强型掩码解码器用于替换输出softmax层来预测模型预训练的掩码标记。 此外,还使用新的虚拟对抗训练方法进行微调,以提高模型对下游任务的泛化能力。

十、mBART
mBART 是一种序列到序列去噪自动编码器,使用 BART 目标在多种语言的大规模单语语料库上进行了预训练。 通过屏蔽短语和排列句子对输入文本进行噪声处理,并学习单个 Transformer 模型来恢复文本。 与其他机器翻译预训练方法不同,mBART 预训练完整的自回归 Seq2Seq 模型。 mBART 针对所有语言进行一次训练,提供一组参数,可以在监督和无监督设置中针对任何语言对进行微调,而无需任何特定于任务或特定于语言的修改或初始化方案。

十一、XLM
XLM 是一种基于 Transformer 的架构,使用以下三种语言建模目标之一进行预训练:
因果语言建模 - 对给定句子中前面的单词的单词的概率进行建模。
Masked Language Modeling - BERT 的屏蔽语言建模目标。
翻译语言建模 - 用于改进跨语言预训练的(新)翻译语言建模目标。
作者发现 CLM 和 MLM 方法都提供了强大的跨语言特征,可用于预训练模型。

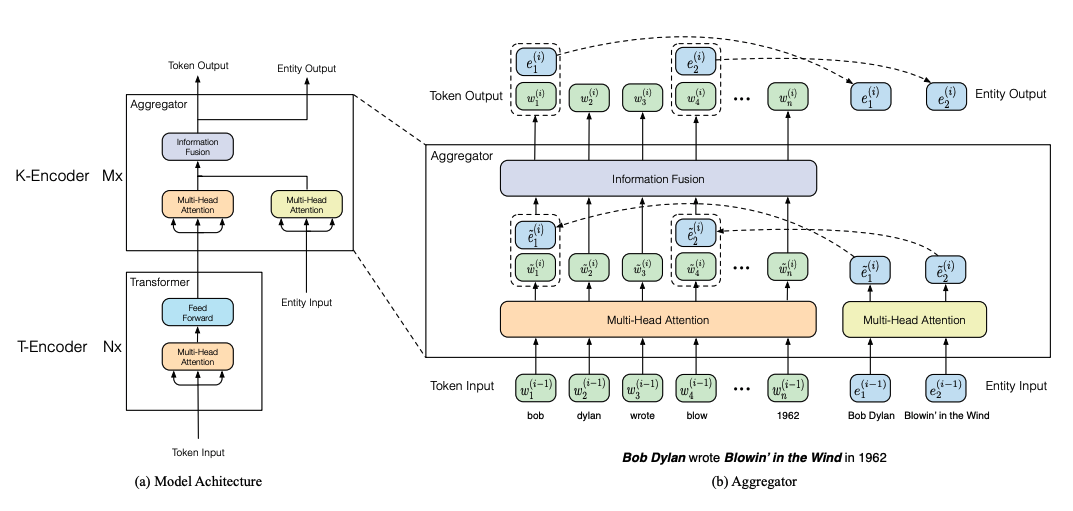
十二、ERNIE
ERNIE 是一个基于 Transformer 的模型,由两个堆叠模块组成:1)文本编码器和 2)知识编码器,负责将额外的面向标记的知识信息集成到文本信息中。 该层由堆叠聚合器组成,旨在对令牌和实体进行编码以及融合它们的异构特征。 为了通过知识整合这一层增强表示,ERNIE 采用了一种特殊的预训练任务 - 它涉及随机屏蔽令牌实体对齐并训练模型以基于对齐令牌预测所有相应实体(又名去噪实体自动编码器) 。


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献119条内容
已为社区贡献119条内容

所有评论(0)