
【计算机视觉 | 图像模型】常见的计算机视觉 image model(CNNs & Transformers) 的介绍合集(六)
文章目录
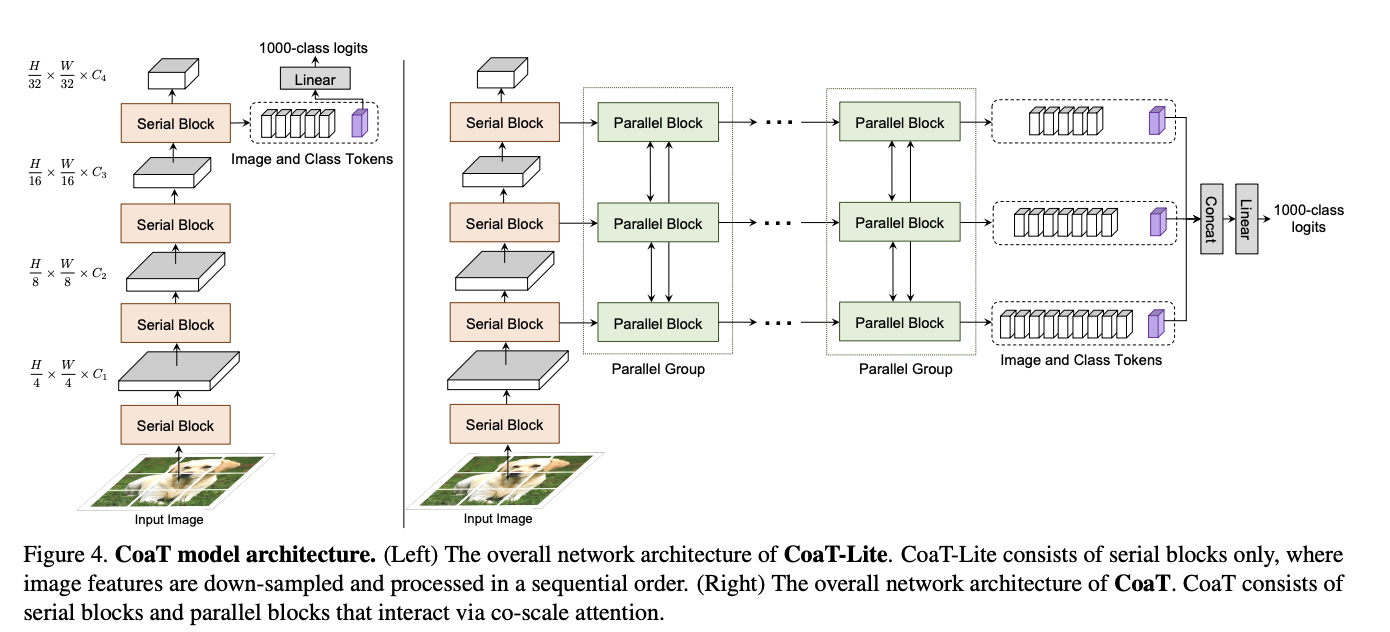
一、Co-Scale Conv-attentional Image Transformer(CoaT)
Co-Scale Conv-Attentional Image Transformer (CoaT) 是一种基于 Transformer 的图像分类器,配备了 co-scale 和 conv-attention 机制。 首先,共尺度机制保持了 Transformers 编码器分支在各个尺度上的完整性,同时允许在不同尺度上学习的表示有效地相互通信。 其次,通过在因子化注意力模块中实现相对位置嵌入公式来设计卷积注意力机制,并采用高效的类似卷积的实现。 CoaT 为图像 Transformers 提供了丰富的多尺度和上下文建模功能。

二、Pyramid Vision Transformer v2(PVTv2)
Pyramid Vision Transformer v2 (PVTv2) 是一种用于检测和分割任务的 Vision Transformer。 它通过多项设计改进对 PVTv1 进行了改进:(1) 重叠补丁嵌入,(2) 卷积前馈网络,以及 (3) 与 PVTv1 框架正交的线性复杂性注意层。

三、Class-Attention in Image Transformers(CaiT)
CaiT(图像变换器中的类注意力)是一种视觉变换器,在原始 ViT 的基础上进行了一些设计更改。 首先使用一种称为 LayerScale 的新层缩放方法,在每个残差块的输出上添加可学习的对角矩阵,初始化为接近(但不是)0,从而提高了训练动态。 其次,该架构中引入了类注意层。 这创建了一个架构,其中涉及补丁之间自注意力的变换器层与类注意力层明确分离——类注意力层致力于将处理后的补丁的内容提取到单个向量中,以便可以将其馈送到线性分类器。

四、PoolFormer
PoolFormer 是通过将令牌混合器指定为极其简单的运算符(池)从 MetaFormer 实例化的。 PoolFormer 被用作验证 MetaFormer 假设“MetaFormer 实际上是您所需要的”(相对于“注意力就是您所需要的”)的工具。

五、ScaleNet
ScaleNet(或称尺度聚合网络)是一种卷积神经网络,它学习神经元分配以聚合深度网络的不同构建块中的多尺度信息。 每个块中信息最丰富的输出神经元被保留,而其他神经元被丢弃,因此多个尺度的神经元被竞争性和自适应地分配。 尺度聚合(SA)块连接各种尺度的特征图。 每个尺度的特征图是通过一堆下采样、卷积和上采样操作生成的。

六、VoVNet
VoVNet 是一种卷积神经网络,旨在通过在最后一个特征图中仅连接一次所有特征来提高 DenseNet 的效率,这使得输入大小恒定并能够扩大新的输出通道。 在右图中,代表一个卷积层并且表示串联。

七、Siamese U-Net
Siamese U-Net 模型采用预训练的 ResNet34 架构作为编码器,用于数据高效的变化检测

八、Single-path NAS
Single-Path NAS 是通过单路径神经架构搜索方法发现的卷积神经网络架构。 NAS 使用单路径搜索空间。 具体来说,与之前的可微分 NAS 方法相比,单路径 NAS 使用一个单路径过参数化 ConvNet 通过共享卷积核参数对所有架构决策进行编码。 该方法基于这样的观察:NAS 中的不同候选卷积操作可以被视为单个超级内核的子集。 不必像多路径方法中那样在不同的路径/操作之间进行选择,我们而是将 NAS 问题解决为找到在每个 ConvNet 层中使用哪个内核权重子集。 通过共享卷积核权重,我们将所有候选 NAS 操作编码到单个超级内核中。
该架构本身使用 MobileNetV2 的反向残差块作为其基本构建块。

九、XCiT
交叉协方差图像变换器(XCiT)是一种视觉变换器,旨在将传统变换器的准确性与卷积架构的可扩展性结合起来。
变压器底层的自注意力操作产生所有标记(即单词或图像块)之间的全局交互,并且能够对超出卷积局部交互的图像数据进行灵活建模。 然而,这种灵活性伴随着时间和内存的二次复杂性,阻碍了长序列和高分辨率图像的应用。 作者提出了一种称为交叉协方差注意力的自注意力“转置”版本,它跨特征通道而不是令牌进行操作,其中交互基于键和查询之间的交叉协方差矩阵。

十、CrossViT
CrossViT 是一种视觉转换器,它使用双分支架构来提取多尺度特征表示以进行图像分类。 该架构结合了不同大小的图像块(即变压器中的标记),以产生更强的图像分类视觉特征。 它使用不同计算复杂度的两个独立分支处理小型和大型补丁令牌,并且这些令牌多次融合在一起以相互补充。
融合是通过高效的交叉注意力模块实现的,其中每个变压器分支创建一个非补丁令牌作为代理,通过注意力与其他分支交换信息。 这允许在融合中线性时间生成注意力图,而不是二次时间。

十一、PeleeNet
PeleeNet 是一种卷积神经网络和对象检测主干网,是 DenseNet 的变体,并进行了优化以满足内存和计算预算。 与竞争网络不同,它不使用深度卷积,而是依赖于常规卷积。

十二、ConViT
ConViT 是一种视觉变换器,它使用门控位置自注意力模块(GPSA),这是一种位置自注意力形式,可以配备“软”卷积归纳偏置。 GPSA 层被初始化为模仿卷积层的局部性,然后通过调整控制对位置与内容信息的注意力的门控参数,使每个注意力头可以自由地逃避局部性。

十三、CrossTransformers
CrossTransformers 是一种基于 Transformer 的神经网络架构,它可以采用少量标记图像和未标记查询,找到查询和标记图像之间的粗略空间对应关系,然后通过计算空间对应特征之间的距离来推断类成员关系。

十四、SKNet
SKNet 是一种卷积神经网络,在其架构中采用选择性内核单元和选择性内核卷积。 这允许一种注意力类型,网络可以学习关注不同的感受野。

十五、SqueezeNeXt
SqueezeNeXt 是一种卷积神经网络,它使用 SqueezeNet 架构作为基线,但进行了一些更改。 首先,通过合并两级挤压模块来更积极地减少通道。 这显着减少了 3×3 卷积使用的参数总数。 其次,它使用可分离的3×3卷积来进一步减小模型尺寸,并去除了squeeze模块之后额外的1×1分支。 第三,该网络使用类似于 ResNet 架构的逐元素加法跳跃连接。


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 0
0 0
0- 0



 已为社区贡献119条内容
已为社区贡献119条内容

所有评论(0)