
【自然语言处理】【大模型】DeepSpeed+Transformers:简单快捷上手百亿参数模型微调
相关博客
【深度学习】混合精度训练与显存分析
【自然语言处理】【大模型】ChatGLM-6B模型结构代码解析(单机版)
【自然语言处理】【大模型】极低资源微调大模型方法LoRA以及BLOOM-LORA实现代码
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
【深度学习】【分布式训练】Collective通信操作及Pytorch示例
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
本文以百亿大模型FLAN-T5 XXL为例,展示如何使用DeepSpeed+Transformers来快速上手百亿参数模型的微调。
FLAN-T5是经过instruction tuning的T5模型,关于instruction tuning可以看文章【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器。本文选用FLAN-T5 XXL模型作为示例,该模型参数量约为11B。
此外,本文涉及到混合精度训练和ZeRO的配置,相关知识可以看文章:
一、模型训练相关代码
为了简洁明了,模型训练相关代码均假设在文件train.py中。
1. 导入依赖包
import nltk
import torch
import evaluate
import datasets
import numpy as np
from nltk.tokenize import sent_tokenize
from torch.utils.data import DataLoader
from torch.nn.utils.rnn import pad_sequence
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from transformers import Seq2SeqTrainer, Seq2SeqTrainingArguments
nltk.download("punkt")
2. 设置参数
dataset_name = "samsum" # 数据集名称
model_name="google/flan-t5-xxl" # 模型名称
max_input_length = 512
max_gen_length = 128
output_dir = "checkpoints"
num_train_epochs = 5
learning_rate = 5e-5
deepspeed_config = "./ds_config.json" # deepspeed配置文件
per_device_train_batch_size=1 # batch size设置为1,因为太大导致OOM
per_device_eval_batch_size=1
gradient_accumulation_steps=2 # 由于单卡的batch size为1,为了扩展batch size,使用梯度累加
tokenizer = AutoTokenizer.from_pretrained(model_name)
3. 加载数据
dataset = datasets.load_dataset(dataset_name)
print(dataset["train"][0])
数据集使用"samsum",其是一个对话摘要数据集。数据格式如下:
{‘id’: ‘13818513’,
‘dialogue’: “Amanda: I baked cookies. Do you want some?\r\nJerry: Sure!\r\nAmanda: I’ll bring you tomorrow 😃”,
‘summary’: ‘Amanda baked cookies and will bring Jerry some tomorrow.’}
4. tokenize
def preprocess(examples):
dialogues = ["summarize:" + dia for dia in examples["dialogue"]]
# summaries = [summ for summ in examples["summary"]]
model_inputs = tokenizer(dialogues, max_length=max_input_length, truncation=True)
labels = tokenizer(text_target=examples["summary"], max_length=max_gen_length, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
tokenized_dataset = dataset.map(preprocess, batched=True, remove_columns=["dialogue", "summary", "id"])
# print(tokenized_dataset["train"]["input_ids"][0]) # 打印结果
该步骤主要负责对输入的样本进行tokenizer,将padding的步骤放在后面进行。
5. collate_fn
def collate_fn(features):
batch_input_ids = [torch.LongTensor(feature["input_ids"]) for feature in features]
batch_attention_mask = [torch.LongTensor(feature["attention_mask"]) for feature in features]
batch_labels = [torch.LongTensor(feature["labels"]) for feature in features]
batch_input_ids = pad_sequence(batch_input_ids, batch_first=True, padding_value=tokenizer.pad_token_id)
batch_attention_mask = pad_sequence(batch_attention_mask, batch_first=True, padding_value=0)
batch_labels = pad_sequence(batch_labels, batch_first=True, padding_value=-100)
return {
"input_ids": batch_input_ids,
"attention_mask": batch_attention_mask,
"labels": batch_labels
}
# 用于测试的代码
# dataloader = DataLoader(tokenized_dataset["test"], shuffle=False, batch_size=4, collate_fn=collate_fn)
# batch = next(iter(dataloader))
# print(batch)
该步骤负责对batch数据进行padding,这样每个batch都会有动态长度。
6. 加载模型
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# 用于测试的代码
# dataloader = DataLoader(tokenized_dataset["test"], shuffle=False, batch_size=4, collate_fn=collate_fn)
# batch = next(iter(dataloader))
# output = model(**batch)
# print(output)
7. 定义评估函数
metric = evaluate.load("rouge")
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
decoded_preds = ["\n".join(sent_tokenize(pred.strip())) for pred in decoded_preds]
decoded_labels = ["\n".join(sent_tokenize(label.strip())) for label in decoded_labels]
result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
result = {k: round(v * 100, 4) for k, v in result.items()}
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
result["gen_len"] = np.mean(prediction_lens)
return result
8. 设置训练参数
training_args = Seq2SeqTrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=per_device_train_batch_size,
per_device_eval_batch_size=per_device_eval_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
eval_accumulation_steps=1, # 防止评估时导致OOM
predict_with_generate=True,
fp16=False,
learning_rate=learning_rate,
num_train_epochs=num_train_epochs,
# logging & evaluation strategies
logging_dir="logs",
logging_strategy="steps",
logging_steps=50, # 每50个step打印一次log
evaluation_strategy="steps",
eval_steps=500, # 每500个step进行一次评估
save_steps=500,
save_total_limit=2,
load_best_model_at_end=True,
deepspeed=deepspeed_config, # deepspeed配置文件的位置
report_to="all"
)
9. 模型训练
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
data_collator=collate_fn,
compute_metrics=compute_metrics,
)
trainer.train()
# 打印验证集上的结果
print(trainer.evaluate(tokenized_dataset["validation"]))
# 打印测试集上的结果
print(trainer.evaluate(tokenized_dataset["test"]))
# 保存最优模型
trainer.save_model("best")
二、DeepSpeed配置文件
ds_config.json
{
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": false
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
三、启动
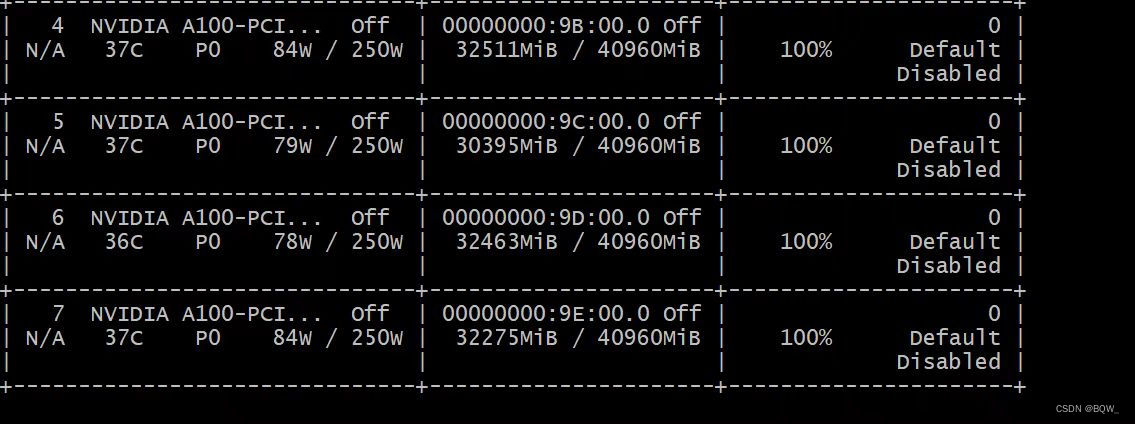
这里使用8张显卡的后4张。此外,使用ZeRO3需要有足够的内存。
deepspeed --include=localhost:4,5,6,7 train.py
四、显存

参考资料
https://www.philschmid.de/fine-tune-flan-t5-deepspeed
https://blog.csdn.net/bqw18744018044/article/details/127181072?spm=1001.2014.3001.5501

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 0
0 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)