
Transformers x SwanLab:可视化NLP模型训练
transformers
huggingface/transformers: 是一个基于 Python 的自然语言处理库,它使用了 PostgreSQL 数据库存储数据。适合用于自然语言处理任务的开发和实现,特别是对于需要使用 Python 和 PostgreSQL 数据库的场景。特点是自然语言处理库、Python、PostgreSQL 数据库。
项目地址:https://gitcode.com/gh_mirrors/tra/transformers
·
HuggingFace 的 Transformers 是目前最流行的深度学习训框架之一(100k+ Star),现在主流的大语言模型(LLaMa系列、Qwen系列、ChatGLM系列等)、自然语言处理模型(Bert系列)等,都在使用Transformers来进行预训练、微调和推理。

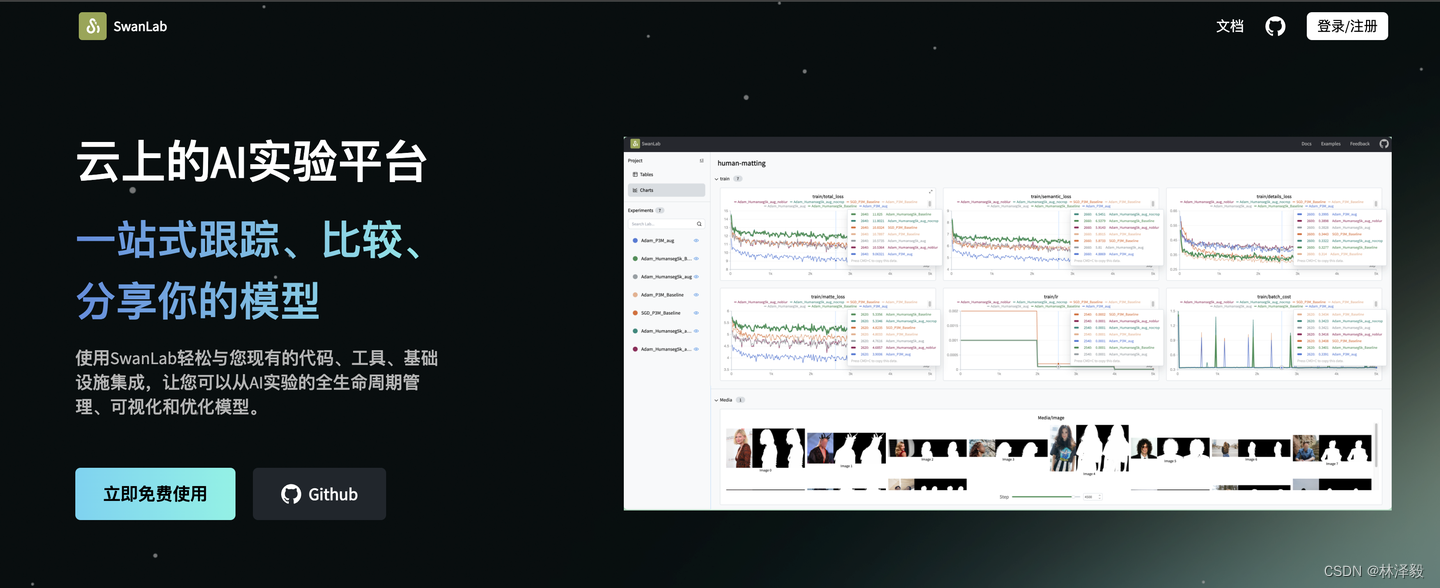
SwanLab是一个深度学习实验管理与训练可视化工具,由西安电子科技大学团队打造,融合了Weights & Biases与Tensorboard的特点,能够方便地进行 训练可视化、多实验对比、超参数记录、大型实验管理和团队协作,并支持用网页链接的方式分享你的实验。

你可以使用Transformers快速进行模型训练,同时使用SwanLab进行实验跟踪与可视化。
下面将用一个Bert训练,来介绍如何将Transformers与SwanLab配合起来:
1. 代码中引入SwanLabCallback
from swanlab.integration.huggingface import SwanLabCallback
SwanLabCallback是适配于Transformers的日志记录类。
SwanLabCallback可以定义的参数有:
- project、experiment_name、description 等与 swanlab.init 效果一致的参数, 用于SwanLab项目的初始化。
- 你也可以在外部通过
swanlab.init创建项目,集成会将实验记录到你在外部创建的项目中。
2. 传入Trainer
from swanlab.integration.huggingface import SwanLabCallback
from transformers import Trainer, TrainingArguments
...
# 实例化SwanLabCallback
swanlab_callback = SwanLabCallback()
trainer = Trainer(
...
# 传入callbacks参数
callbacks=[swanlab_callback],
)
3. 案例-Bert训练
查看在线实验过程:BERT-SwanLab

下面是一个基于Transformers框架,使用BERT模型在imdb数据集上做微调,同时用SwanLab进行可视化的案例代码
"""
用预训练的Bert模型微调IMDB数据集,并使用SwanLabCallback回调函数将结果上传到SwanLab。
IMDB数据集的1是positive,0是negative。
"""
import torch
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from swanlab.integration.huggingface import SwanLabCallback
import swanlab
def predict(text, model, tokenizer, CLASS_NAME):
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
predicted_class = torch.argmax(logits).item()
print(f"Input Text: {text}")
print(f"Predicted class: {int(predicted_class)} {CLASS_NAME[int(predicted_class)]}")
return int(predicted_class)
# 加载IMDB数据集
dataset = load_dataset('imdb')
# 加载预训练的BERT tokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
# 定义tokenize函数
def tokenize(batch):
return tokenizer(batch['text'], padding=True, truncation=True)
# 对数据集进行tokenization
tokenized_datasets = dataset.map(tokenize, batched=True)
# 设置模型输入格式
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format('torch', columns=['input_ids', 'attention_mask', 'labels'])
# 加载预训练的BERT模型
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# 设置训练参数
training_args = TrainingArguments(
output_dir='./results',
eval_strategy='epoch',
save_strategy='epoch',
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
logging_first_step=100,
# 总的训练轮数
num_train_epochs=3,
weight_decay=0.01,
report_to="none",
# 单卡训练
)
CLASS_NAME = {0: "negative", 1: "positive"}
# 设置swanlab回调函数
swanlab_callback = SwanLabCallback(project='BERT',
experiment_name='BERT-IMDB',
config={'dataset': 'IMDB', "CLASS_NAME": CLASS_NAME})
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets['train'],
eval_dataset=tokenized_datasets['test'],
callbacks=[swanlab_callback],
)
# 训练模型
trainer.train()
# 保存模型
model.save_pretrained('./sentiment_model')
tokenizer.save_pretrained('./sentiment_model')
# 测试模型
test_reviews = [
"I absolutely loved this movie! The storyline was captivating and the acting was top-notch. A must-watch for everyone.",
"This movie was a complete waste of time. The plot was predictable and the characters were poorly developed.",
"An excellent film with a heartwarming story. The performances were outstanding, especially the lead actor.",
"I found the movie to be quite boring. It dragged on and didn't really go anywhere. Not recommended.",
"A masterpiece! The director did an amazing job bringing this story to life. The visuals were stunning.",
"Terrible movie. The script was awful and the acting was even worse. I can't believe I sat through the whole thing.",
"A delightful film with a perfect mix of humor and drama. The cast was great and the dialogue was witty.",
"I was very disappointed with this movie. It had so much potential, but it just fell flat. The ending was particularly bad.",
"One of the best movies I've seen this year. The story was original and the performances were incredibly moving.",
"I didn't enjoy this movie at all. It was confusing and the pacing was off. Definitely not worth watching."
]
model.to('cpu')
text_list = []
for review in test_reviews:
label = predict(review, model, tokenizer, CLASS_NAME)
text_list.append(swanlab.Text(review, caption=f"{label}-{CLASS_NAME[label]}"))
if text_list:
swanlab.log({"predict": text_list})
swanlab.finish()




4. 相关链接
- Transformers文档:🤗 Transformers
- SwanLab官网:SwanLab - 在线AI实验平台,一站式跟踪、比较、分享你的模型
- SwanLab官方文档:SwanLab官方文档 | 先进的AI团队协作与模型创新引擎
huggingface/transformers: 是一个基于 Python 的自然语言处理库,它使用了 PostgreSQL 数据库存储数据。适合用于自然语言处理任务的开发和实现,特别是对于需要使用 Python 和 PostgreSQL 数据库的场景。特点是自然语言处理库、Python、PostgreSQL 数据库。
最近提交(Master分支:3 个月前 )
13493215
* remove v4.44 deprecations
* PR comments
* deprecations scheduled for v4.50
* hub version update
* make fiuxp
---------
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> 6 天前
8d50fda6
* Remove FSDP wrapping from sub-models.
* solve conflict trainer.py
* make fixup
* add unit test for fsdp_auto_wrap_policy when using auto_find_batch_size
* put back extract_model_from_parallel
* use transformers unwrap_model 6 天前

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)