
Mamba:能取代Transformers吗?
文章目录
许多研究工作都致力于使Transformers更高效。毫无疑问,Transformers非常出色,但它们需要大量的资源和数据。像Flash Attention、RetNet等研究显示出巨大的潜力,但不知何故Transformer仍然是王者。在本论文综述中,我们将讨论一种全新的架构,称为 Mamba。
它具有快速推理(比Transformers高5倍的吞吐量)和线性扩展的序列长度,其性能在真实数据上提高了百万长度的序列。Mamba作为一种通用的序列模型骨干,在语言、音频和基因组等多个领域实现了最先进的性能。在语言建模方面,我们的Mamba-3B模型在预训练和下游评估中的性能超过了相同规模的Transformers,并且与其两倍大小的Transformers相匹配。
目录
-
理解Attention的内存需求
-
解决内存问题的其他方法
-
Mamba为什么看起来很有前途?
-
RNN的问题
-
什么是“结构化状态空间模型”(SSM)?
-
Mamba 🐍
-
硬件加速
-
简化的SSM架构
理解Attention的内存需求
自注意力的有效性归功于其在上下文窗口内密集路由信息的能力,使其能够对复杂数据进行建模。然而,这种特性带来了基本的缺点:无法对有限窗口之外的任何内容进行建模,并且随着窗口长度的增加呈二次扩展。
自注意力的重大突破在于网络能够将输入的不同部分彼此关联起来,无论距离如何。这种重要性直接取决于输出。对于不同类型的输出,对输入数据序列中每个标记的关注程度会有相当大的差异。但问题在于扩展这种类型的系统。为了计算注意力分数,我们需要为长度为N的序列存储一个NxN的注意力分数矩阵。这意味着随着上下文窗口的顺序增加,扩展将变得越来越资源密集。
**注意:**这些注意力分数需要存储在缓存内存或RAM中,而不是硬盘中,这就是在本地训练LLMs如此困难的原因。
为了更好地理解内存需求,让我们考虑一个场景:
*一个像BERT-base这样的Transformer模型,具有1.1亿个参数;序列长度为512个标记;隐藏大小(d)为768;12个注意力头;批量大小为32;使用32位精度。*
-
**参数内存:**每个参数是32位浮点数,即4个字节。因此,参数的内存为110 × 10⁶ × 4字节。
-
**注意力分数矩阵内存:**大小为n² × h × b × 4字节(32位浮点数)。对于n = 512,ℎ = 12和b = 32,这给出了注意力分数矩阵所需的内存。
-
中间矩阵内存: Q、K和V矩阵的大小分别为n × d × b × 4字节。乘以3得到Q、K、V的内存。
在给定的场景中,总内存需求约为0.93 GB。
这表明即使对于一个相当小的模型,内存需求也很大,对于GPT这样规模的系统来说,它是成千上万倍的,因为存在二次扩展。他们甚至不得不建立一个全新的数据中心,以用大约1亿美元的预算来训练这样一个模型。
解决内存问题的其他方法
我最近读到的一篇非常有趣的论文与此相关,名为Flash Attention 2。
Flash Attention 2为什么更好?
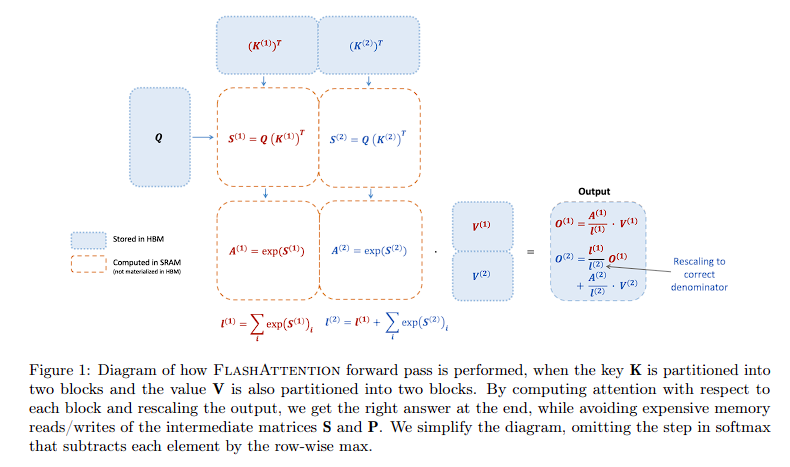
Flash Attention 2基本上将大多数计算保留在缓存或高带宽内存(HBM)中,但通常这些内存非常小,无法将整个注意力矩阵存储在其中。
**解决方案:**将注意力矩阵分成较小的块并为它们计算事物。
这会带来另一个问题,为了对注意力分数进行归一化,我们需要整行的注意力值。
**解决方案:**一种巧妙的归一化和重新缩放方法


注意: 现在这可能看起来像更多的计算,但请记住它们可以在HBM中保存大量计算,这就是它更快的原因。
减少非矩阵乘法操作: FlashAttention-2最小化非矩阵乘法FLOPs(每秒浮点运算次数),因为GPU上缺乏专门的计算单元来执行这些操作,所以这些操作速度较慢。通过专注于GPU可以更高效执行的矩阵乘法(matmul)操作,FlashAttention-2与硬件能力更好地对齐。
并行化和工作分区: 该算法不仅在批次大小和头数之间并行化注意力计算,还沿着序列长度维度进行并行化。这增强了GPU资源利用率。此外,在GPU上的每个线程块中,工作被分配给不同的warp(线程组),减少了对共享内存访问的需求,提高了计算效率。
我强烈建议阅读论文或听作者本人的演讲:点击这里
其他具有注意力近似的方法
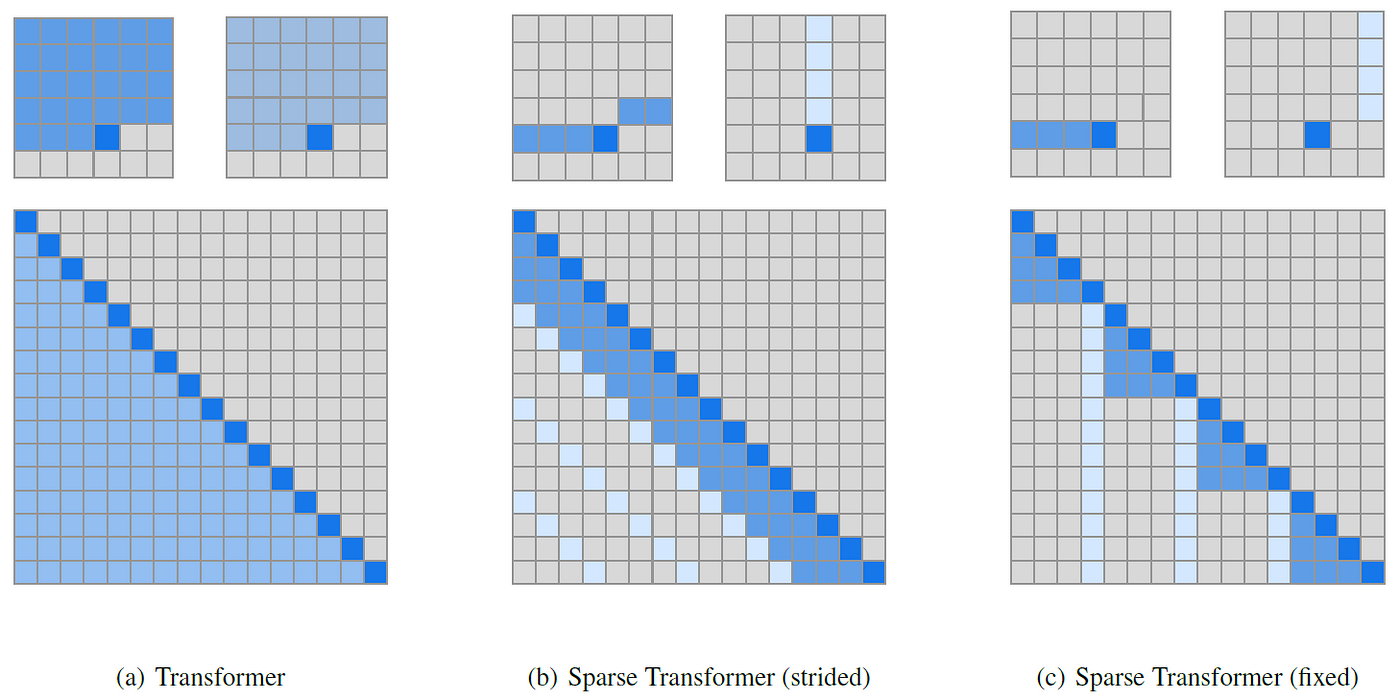
稀疏注意力: 稀疏注意力模式,如Longformer中使用的模式,选择性地关注一部分键值对,而不是全部。这可以涉及关注周围单词的固定窗口或实施确保每个单词定期获得全局视图的模式,例如对角线或跨距注意力。这将复杂度从二次降低到与序列长度成线性或对数线性关系。论文:点击这里

稀疏注意力(图片来源)
**低秩注意力:**这种方法利用了注意力矩阵可以近似为两个较小矩阵的乘积的假设。通过降低这些矩阵的秩,可以减少执行注意力操作所需的计算量。这种方法是有效的,因为在实践中,注意力矩阵通常具有低秩结构,只有少数组件是显著的。论文:点击这里

低秩注意力
核化注意力: 在像Performer这样的模型中,softmax函数使用正定核进行近似。这些方法将原始向量映射到再生核希尔伯特空间(RKHS),其中注意力操作被近似为点积,从而允许使用线性复杂度对注意机制进行无偏估计。论文:点击此处
Reformer: 它使用局部敏感哈希来近似点积注意力。基于哈希相似性,令牌被排序到桶中,并且仅在每个桶内计算注意力。这种方法是高效的,因为它减少了需要进行的比较次数。论文:点击此处

LSH Attention
Linformer: Linformer模型使用学习的线性投影将键和值投影到较低维度的空间中,从而将时间和空间复杂度从二次降至与序列长度成线性关系。当注意力矩阵不需要捕捉数据内部极细粒度的关系时,这种方法效果很好。论文:点击这里
Longformer: Longformer模型使用滑动窗口机制,限制每个标记仅关注附近的标记,以及可以关注序列中任何标记的一些全局标记。这种混合方法可以有效地捕捉本地和全局上下文。论文:点击这里

为什么Mamba看起来很有前途?
Mamba在传统Transformer模型上实现了五倍的处理速度提升,展示了与序列长度成线性可扩展的特点,而不是典型的二次可扩展。这种效率可以应用于长度达到百万元素的序列。
这一进展不仅在基于文本的应用(如对话AI、摘要和搜索)方面开辟了新的道路,而且在音频合成、基因组分析和复杂时间序列预测等领域也是如此,这些领域对建模广泛序列至关重要。
“Mamba”这个名字的灵感来自于其基于S4模型的基础,S4代表“选择性结构化状态空间序列模型”——这个标题与其同名的蛇一样迅速而强大。🐍
至于为什么我们需要这个,以上部分已经详细定义了注意力得分矩阵的二次扩展。
要理解Mamba,我们还需要了解一些关于RNN的问题。
RNN的问题
几年前,RNN非常流行,但是有两个主要问题与循环网络相关。
-
RNN将所有信息压缩到一个隐藏空间中,并且在较长的序列上容易遗忘信息。
-
RNN在生成方面速度很快,但在训练方面速度较慢。
我们所说的“将所有信息压缩”是指想象一下将一个句子中的所有信息保存到一个小的隐藏空间中。在下面的图表中,我们可以看到模型在进行时必须选择性地记住它所经历的内容。

RNN记住选择性信息
在有限的潜在空间中捕捉全面的上下文是具有挑战性的,特别是在尝试保留序列开头和结尾的细节时。
在历史上,GRUs和LSTMs在它们的循环单元中利用门控机制来谨慎地保留或丢弃整个序列处理过程中的信息。
然而,隐藏状态保存上下文的能力是固有有限的,尽管采用了复杂的门控策略。
RNN的局限性加剧了它们训练缓慢的倾向,因为需要进行顺序计算,以及它们对“梯度消失”问题的敏感性,即在通过长序列进行反向传播时梯度可能会减小或变得过大。
什么是“结构化状态空间模型”(SSM)?
SSM是Mamba的核心,因此了解它们的工作方式很重要。我们可以将它们视为变压器中自注意机制的替代品。
状态空间模型(SSM)提供了一种有效表示和分析序列的结构化方法。在神经网络的上下文中,SSM可以用作处理序列的层,其核心概念是将输入信号映射到潜在状态,然后映射到输出信号。SSM的更新和输出方程为:

在这里,A,B,C和D是定义系统动力学的矩阵,其中A表示状态的演变,B表示输入对状态的影响,C表示状态如何转化为输出,D表示输入到输出的直接传递。
请注意,与您标准的循环网络不同 - 它只是完全线性的,并且没有LSTM或GRU内部的非线性变换。

时间步骤t时的隐藏状态(图片来源)

在时间步骤t处的输出(图片来源)
在神经网络中使用SSMs的直觉是将输入序列转换为一个更高维的空间(潜在状态),在将其投影到所需的输出之前,可以更有效地捕捉其动态。矩阵A、B和C将输入数据转换为随时间演化的潜在空间,使模型能够捕捉时间依赖性。SSM的离散版本使得将这种连续时间概念应用于离散时间数据(如机器学习任务中的序列)成为可能。
要在离散设置中使用SSMs,例如在神经网络训练中,通常会对模型进行离散化处理,使用类似双线性变换的方法,从而得到离散更新方程:

这些离散方程使得SSM能够以类似于递归神经网络(RNNs)的方式应用于输入序列,但在展开时具有像卷积神经网络(CNNs)一样的训练能力。这种方法可以显著提高对长序列建模的效率。
SSM离散化中使用的双线性变换方法就像决定何时拍摄这些快照,并确保连续的“电影”中的重要特征(如运动或场景变化)在这些离散的“帧”中得到准确捕捉一样。矩阵ˉAˉ和ˉBˉ是帮助我们将连续流转化为一系列步骤的工具,而不失去我们建模过程的本质。

SSM在RNN结构中的应用
序列建模是将上下文压缩成较小的状态,然后使用它来预测输出序列的艺术。
注意力并不压缩上下文,它使模型完全访问历史记录。注意力可以与RNN一起使用,并且过去已经使用过,但它的计算成本相当高。
模型压缩其状态的效果与效率之间存在权衡。如果您有一个小状态和很少的上下文,您将更有效率。如果您有大量上下文的大状态,模型将更慢但更准确。
Mamba 🐍
本文对SSM的贡献如下
-
一种选择机制,允许模型过滤掉不相关的信息,并无限期地记住相关信息。
-
一种硬件感知算法,可以递归计算模型,但不会在扩展状态中实现,优化GPU内存布局。
这两种技术的组合具有以下特性
-
在语言和其他具有长序列的数据上具有高质量的结果
-
训练和推理速度快
-
训练期间的内存和计算按序列长度线性扩展
-
推理涉及逐个元素展开模型,每个步骤的时间恒定,没有先前元素的缓存
-
长上下文-在实际数据上的性能提高,最长可达100万个序列长度
简而言之,Mamba是S4的高级版本。


硬件加速
该模型通过高速缓存(SRAM)高效地存储其参数,并在SRAM中执行离散化和循环,同时将最终输出写入高带宽内存(HBM)。

一个简化的SSM架构
选择性SSM块可以作为独立的转换被整合到神经网络中,就像你会将一个RNN单元(如LSTM或GRU)整合进去一样。下面是一个Mamba块的完整架构,并不仅仅是我们上面讨论过的SSM模块。在更大的Mamba块中,SSM块周围还有线性投影、卷积和非线性。

他们首先通过一个线性层将输入投影到上面,扩展输入的维度,他们还在右侧添加了一个类似于transformer的残差连接。
然后他们在线性层上运行一个1D卷积,在通过SiLU / Swish激活函数之前,它到达了我们上面讨论过的SSM块。
残差路径然后与SSM的输出连接,他们通过最后的线性层将维度缩小到与输入相同。
一个重要的联系:RNN的经典门控机制是SSM选择机制的一个实例。
就这些,关于结果和评估,我建议阅读参考中给出的原始论文。
参考资料
[1] https://arxiv.org/ftp/arxiv/papers/2312/2312.00752.pdf

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 26
26 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

{kind=link}
{kind=link}
所有评论(0)