
【经验总结】超算互联网服务器 transformers 加载本地模型
transformers
huggingface/transformers: 是一个基于 Python 的自然语言处理库,它使用了 PostgreSQL 数据库存储数据。适合用于自然语言处理任务的开发和实现,特别是对于需要使用 Python 和 PostgreSQL 数据库的场景。特点是自然语言处理库、Python、PostgreSQL 数据库。
项目地址:https://gitcode.com/gh_mirrors/tra/transformers
·
1. 背景
使用 超算互联网 的云服务,不能连接外网,只能把模型下载到本地,再上传上去到云服务。
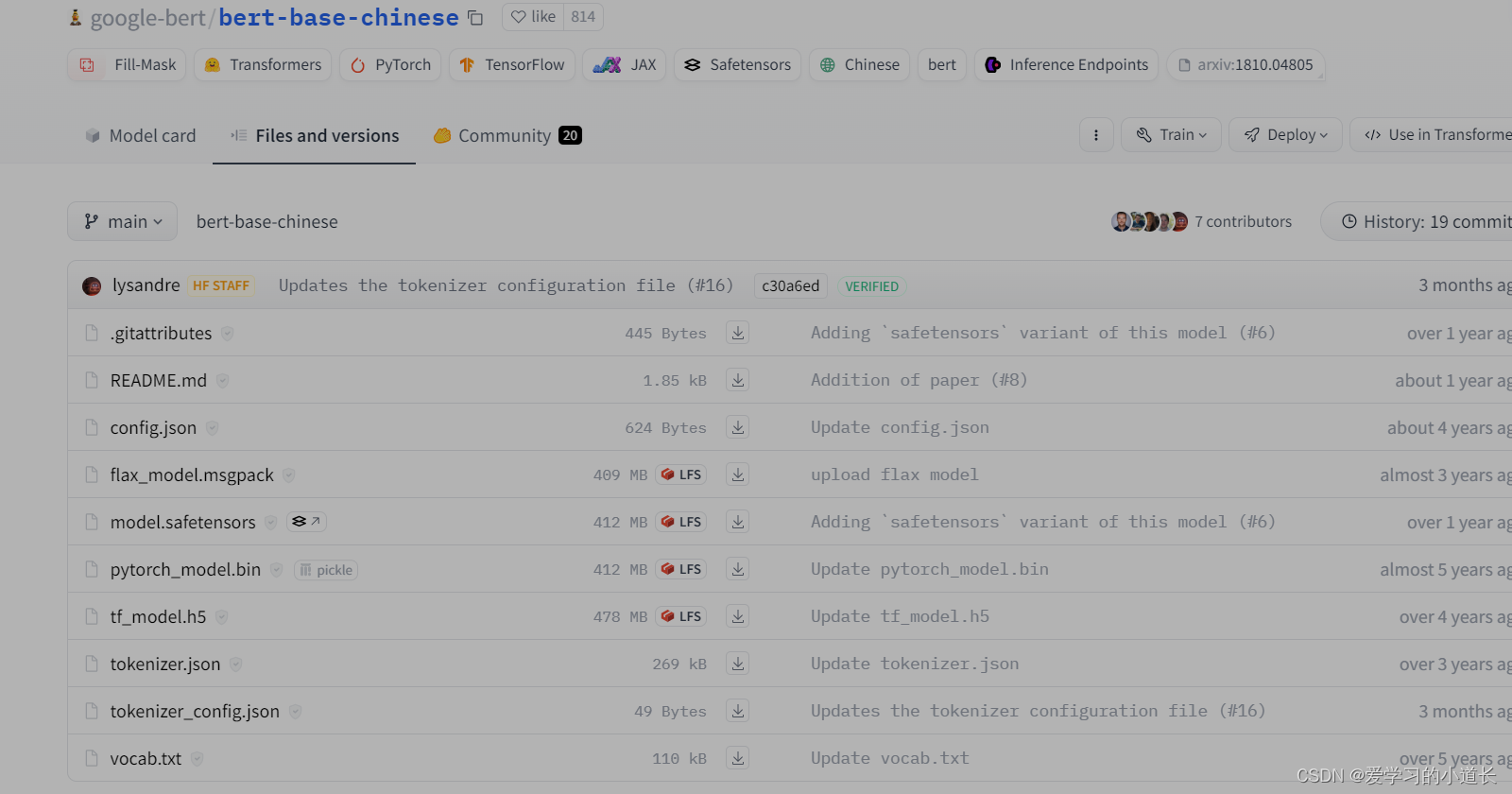
2. 模型下载
在 模型中 https://huggingface.co/models 找到所需的模型后

点击下载 config.json pytorch_model.bin vocab.txt
3. 上传模型文件
打开文件管理 e-file
点击 上传,选择 本地上传

4. 运行代码
由原来的代码:
from transformers import BertTokenizer, BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=2)
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
改成这样的:
from transformers import BertTokenizer, BertForSequenceClassification
path_to_local_model_directory="/public/home/acc5trotmy/jupyter/models/bert-base-chinese"
model = BertForSequenceClassification.from_pretrained(path_to_local_model_directory, num_labels=2)
tokenizer = BertTokenizer.from_pretrained(path_to_local_model_directory)
或者:
from transformers import BertTokenizer, BertForSequenceClassification, BertConfig
config = BertConfig.from_pretrained(path_to_local_model_directory)
model = BertForSequenceClassification.from_pretrained(path_to_local_model_directory, config=config)
tokenizer = BertTokenizer.from_pretrained(path_to_local_model_directory)
huggingface/transformers: 是一个基于 Python 的自然语言处理库,它使用了 PostgreSQL 数据库存储数据。适合用于自然语言处理任务的开发和实现,特别是对于需要使用 Python 和 PostgreSQL 数据库的场景。特点是自然语言处理库、Python、PostgreSQL 数据库。
最近提交(Master分支:2 个月前 )
33868a05
* [i18n-HI] Translated accelerate page to Hindi
* Update docs/source/hi/accelerate.md
Co-authored-by: K.B.Dharun Krishna <kbdharunkrishna@gmail.com>
* Update docs/source/hi/accelerate.md
Co-authored-by: K.B.Dharun Krishna <kbdharunkrishna@gmail.com>
* Update docs/source/hi/accelerate.md
Co-authored-by: K.B.Dharun Krishna <kbdharunkrishna@gmail.com>
* Update docs/source/hi/accelerate.md
Co-authored-by: K.B.Dharun Krishna <kbdharunkrishna@gmail.com>
---------
Co-authored-by: Kay <kay@Kays-MacBook-Pro.local>
Co-authored-by: K.B.Dharun Krishna <kbdharunkrishna@gmail.com> 3 小时前
e2ac16b2
* rework converter
* Update modular_model_converter.py
* Update modular_model_converter.py
* Update modular_model_converter.py
* Update modular_model_converter.py
* cleaning
* cleaning
* finalize imports
* imports
* Update modular_model_converter.py
* Better renaming to avoid visiting same file multiple times
* start converting files
* style
* address most comments
* style
* remove unused stuff in get_needed_imports
* style
* move class dependency functions outside class
* Move main functions outside class
* style
* Update modular_model_converter.py
* rename func
* add augmented dependencies
* Update modular_model_converter.py
* Add types_to_file_type + tweak annotation handling
* Allow assignment dependency mapping + fix regex
* style + update modular examples
* fix modular_roberta example (wrong redefinition of __init__)
* slightly correct order in which dependencies will appear
* style
* review comments
* Performance + better handling of dependencies when they are imported
* style
* Add advanced new classes capabilities
* style
* add forgotten check
* Update modeling_llava_next_video.py
* Add prority list ordering in check_conversion as well
* Update check_modular_conversion.py
* Update configuration_gemma.py 9 小时前

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 8
8 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)