
onnxruntime模型部署(番外2)模型量化之tensor量化
量化不是一个特别复杂的新技术,只是名字听着很唬人,其实本质就是将连续信号转化为离散信号的一种表现,如果把weight看作是一种连续信号,为了便于存储和计算,在减小一定精度的情况下进行离散,这既是量化的本质。
what and why
模型量化是指将模型的浮点数参数量化为定点整型,将浮点数运算都化为定点运算。
模型量化可以做到推理加速,与神经网络剪枝相比,泛用性更强。
数学原理
量化就是把浮点数化为整型,最简单的例子就是我们在将图像输入到模型中之前需要做归一化,将0到255的像素值归一化为0到1之间的浮点数。这个过程就可以理解为是反量化,模型输出的浮点数需要换算成像素值,这个过程就是量化。
根据换算方法的不同,可以分为多种量化方式。

均匀量化和非均匀量化

对称量化和非对称量化
均匀量化uniform quantization
三个参数:尺度因子scale,0点便宜offset【有些教程称为zero-point】,位宽bit-width【位宽就是量化后数据占用的bit大小,一般都是INT8,也就是8bit】
X
i
n
t
=
C
l
i
p
(
R
o
u
n
d
(
X
s
c
a
l
e
+
o
f
f
s
e
t
)
)
X
q
=
(
X
i
n
t
−
o
f
f
s
e
t
)
∗
s
c
a
l
e
E
r
r
o
r
=
∣
∣
X
−
X
q
∣
∣
X
\begin{align} X_{int} & = Clip(Round(\frac{X}{scale}+offset)) \\ X_q & = (X_{int}-offset)*scale \\ Error & = \frac{||X-X_q||}{X} \end{align}
XintXqError=Clip(Round(scaleX+offset))=(Xint−offset)∗scale=X∣∣X−Xq∣∣
Round函数是指四舍五入函数,clip函数是指将所有数据限制到一个范围内,比如量化为int8大小的整型,那么该函数的意义就是将所有输入限制在0到255之间。
offset是指偏移量,scale是指缩放尺度,当offset固定为0时,称为均匀对称量化。
可以有效量化的范围是
(
−
s
c
a
l
e
∗
o
f
f
s
e
t
,
s
c
a
l
e
∗
2
b
−
1
)
(-scale*offset,scale*2^b-1)
(−scale∗offset,scale∗2b−1),超过这个范围的数字都会被压缩为极限值,小于min的变成min,大于max的压缩为max,会导致误差增大。可以通过改变scale的大小来控制有效量化范围,但是scale太大又会导致量化范围内“分辨率”的稀疏,本来可以区分3.1和3.9的,scale太大之后统一量化为了3,也会导致误差增大。
所以scale的选择是一个超参数,需要平衡两种误差。
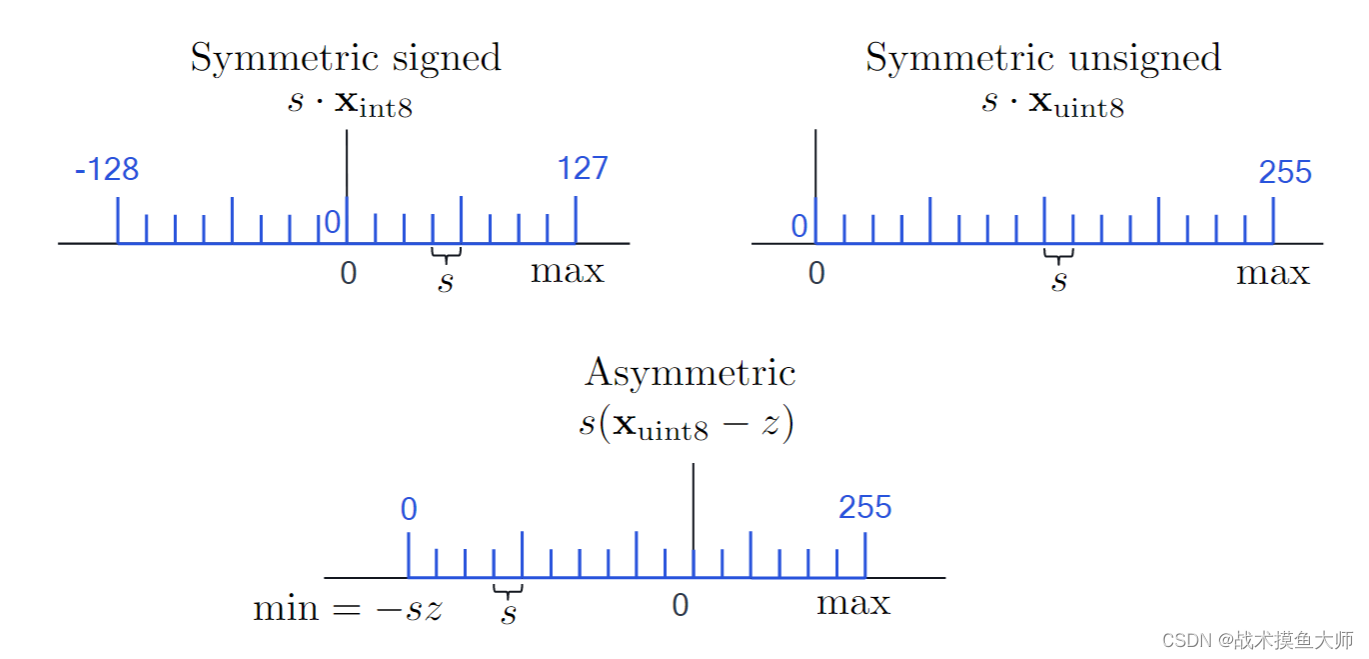
对于offset=0的对称量化,量化不会改变原参数的符号,所以需要考虑量化后的整型是否需要有符号

有符号,无符号,;非对称,三种量化方式量化后的范围。
scale等于2的幂次的时候称为2次幂量化,这种情况下计算时只需要进行位移即可,更加高效,但是限制scale的取值也相应会影响精度。
量化实现
量化粒度
得知了量化的数学原理,我们需要为模型的weight和activation进行分别量化。衡量一个模型的量化水平的指标称为量化粒度(quantization granularity),最常见的量化粒度就是为weight和activation各定义一个量化器,这样实现起来最简单,称为per-tesnor quantization。如果想要提高精度,可以选择使用更细的粒度进行量化,例如为不同的output channel的weight分别定义一个量化器,单独设置参数。这种称为per-hannel quantization。更精细的量化粒度,不做讨论。
为什么per_channel比per_tensor粒度要细?
因为per_tensor是指整个tensor中的所有公用一个量化器,而per_channel是指每个channel一个量化器。例如一张图片存储为一个tensor,如果用per_tesnor,那就只有一个量化器,如果用per_channel,那就有3个量化器。
量化模拟
如何判断一个量化过的模型在推理设备上运行的效果,最简单的判断就是上机实战,但是有时候条件有限没法上机实战,可以考虑在训练设备上进行量化模拟。

左边是实际推理设备上的模型流程,右边是量化模拟中的模型推理流程,量化模拟就是在原本模型的基础上为weight和output添加一个quantizer,其实背后的计算还是用的浮点计算,即:用浮点计算来模拟量化后的定点运算。这种方法相较于在推理设备实战以及在训练设备上搞一套runtime要简单快捷的多,这种方案的运算是依靠pytorch这种训练框架实现的,需要自己实现的部分就只有quantizer,而且要注意,这里的quantizer的输入输出也还都是浮点数,添加quantizer只不过是为了模拟量化这个过程,以查看量化对精度的影响。
这种边量化查看效果边进行训练的方式就是PTQ动态量化,所有数据都还是浮点数,但是参数更新会受到量化的影响,进而避免了训练好模型再量化如果量化不合适会较大的精度损失的情况。
实现代码
import torch
from torch import nn
import torch.nn.functional as F
# Create a model
class Model_demo(nn.Module):
def __init__(self):
super(Model_demo, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# An instance of your model.
model = Model_demo()
quantized_model = torch.quantization.quantize_dynamic(model=model, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)
# Pytorch中动态量化不会对CNN的参数进行量化,可能是因为觉得CNN的参数较少,动态量化意义不大。
print(quantized_model.fc1.weight())
print(model.fc1.weight)
# 可以看到量化后的参数是有一些误差的
量化技术原理本身不难,难的是五花八门的模型结构,互不相同的框架,这些因素导致量化学起来很难,因为经常是量化完发现加速是明显了,精度损失也很明显。
至于非均匀量化以及算子融合等知识,后面再出blog讲解。
点赞+关注=催更

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)