
onnxruntime和tensorrt多batch推理
onnxruntime
microsoft/onnxruntime: 是一个用于运行各种机器学习模型的开源库。适合对机器学习和深度学习有兴趣的人,特别是在开发和部署机器学习模型时需要处理各种不同框架和算子的人。特点是支持多种机器学习框架和算子,包括 TensorFlow、PyTorch、Caffe 等,具有高性能和广泛的兼容性。
项目地址:https://gitcode.com/gh_mirrors/on/onnxruntime
·
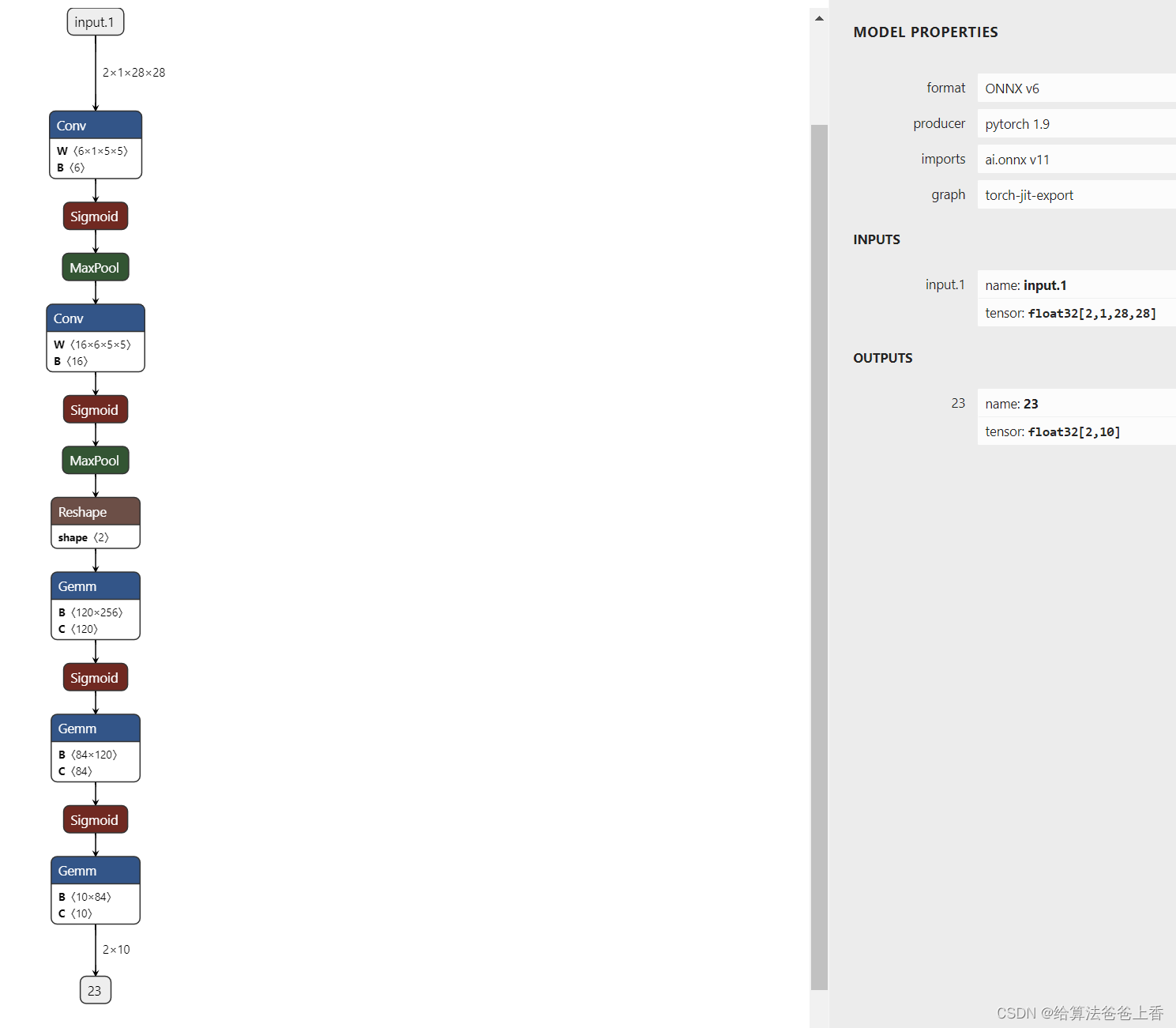
以lenet网络为例。
onnxruntime多batch推理
当batch size为2时,导出如下结构的onnx文件:

python推理:
import cv2
import numpy as np
import onnxruntime
img0 = cv2.imread("2.png", 0)
img1 = cv2.imread("10.png", 0)
blob0 = cv2.dnn.blobFromImage(img0, 1/255., size=(28,28), swapRB=True, crop=False)
blob1 = cv2.dnn.blobFromImage(img1, 1/255., size=(28,28), swapRB=True, crop=False)
onnx_session = onnxruntime.InferenceSession("lenet.onnx", providers=['CPUExecutionProvider'])
input_name = []
for node in onnx_session.get_inputs():
input_name.append(node.name)
output_name = []
for node in onnx_session.get_outputs():
output_name.append(node.name)
inputs = {}
for name in input_name:
inputs[name] = np.concatenate((blob0, blob1), axis=0)
outputs = onnx_session.run(None, inputs)[0]
print(np.argmax(outputs, axis=1))
C++推理:
#include <iostream>
#include <opencv2/opencv.hpp>
#include <onnxruntime_cxx_api.h>
int main(int argc, char* argv[])
{
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "lenet");
Ort::SessionOptions session_options;
session_options.SetIntraOpNumThreads(1);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_EXTENDED);
const wchar_t* model_path = L"lenet.onnx";
Ort::Session session(env, model_path, session_options);
Ort::AllocatorWithDefaultOptions allocator;
std::vector<const char*> input_node_names;
for (size_t i = 0; i < session.GetInputCount(); i++)
{
input_node_names.push_back(session.GetInputName(i, allocator));
}
std::vector<const char*> output_node_names;
for (size_t i = 0; i < session.GetOutputCount(); i++)
{
output_node_names.push_back(session.GetOutputName(i, allocator));
}
const size_t input_tensor_size = 2 * 1 * 28 * 28;
std::vector<float> input_tensor_values(input_tensor_size);
cv::Mat image0 = cv::imread("2.png", 0);
cv::Mat image1 = cv::imread("10.png", 0);
image0.convertTo(image0, CV_32F, 1.0 / 255);
image1.convertTo(image1, CV_32F, 1.0 / 255);
for (int i = 0; i < 28; i++)
{
for (int j = 0; j < 28; j++)
{
input_tensor_values[i * 28 + j] = image0.at<float>(i, j);
input_tensor_values[28 * 28 + i * 28 + j] = image1.at<float>(i, j);
}
}
std::vector<int64_t> input_node_dims = { 2, 1, 28, 28 };
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(memory_info, input_tensor_values.data(), input_tensor_size, input_node_dims.data(), input_node_dims.size());
std::vector<Ort::Value> inputs;
inputs.push_back(std::move(input_tensor));
std::vector<Ort::Value> outputs = session.Run(Ort::RunOptions{ nullptr }, input_node_names.data(), inputs.data(), input_node_names.size(), output_node_names.data(), output_node_names.size());
const float* rawOutput = outputs[0].GetTensorData<float>();
std::vector<int64_t> outputShape = outputs[0].GetTensorTypeAndShapeInfo().GetShape();
size_t count = outputs[0].GetTensorTypeAndShapeInfo().GetElementCount();
std::vector<float> preds(rawOutput, rawOutput + count);
int predict_label0 = std::max_element(preds.begin(), preds.begin() + 10) - preds.begin();
int predict_label1 = std::max_element(preds.begin() + 10, preds.begin() + 20) - preds.begin() - 10;
std::cout << predict_label0 << std::endl;
std::cout << predict_label1 << std::endl;
return 0;
}
tensorrt多batch推理
python推理:
import cv2
import numpy as np
import tensorrt as trt
import pycuda.autoinit #负责数据初始化,内存管理,销毁等
import pycuda.driver as cuda #GPU CPU之间的数据传输
# 创建logger:日志记录器
logger = trt.Logger(trt.Logger.WARNING)
# 创建runtime并反序列化生成engine
with open("lenet.engine", "rb") as f, trt.Runtime(logger) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
context = engine.create_execution_context()
# 分配CPU锁页内存和GPU显存
h_input = cuda.pagelocked_empty(trt.volume(context.get_binding_shape(0)), dtype=np.float32)
h_output = cuda.pagelocked_empty(trt.volume(context.get_binding_shape(1)), dtype=np.float32)
d_input = cuda.mem_alloc(h_input.nbytes)
d_output = cuda.mem_alloc(h_output.nbytes)
# 创建cuda流
stream = cuda.Stream()
#加载图片
img0 = cv2.imread("2.png", 0)
img1 = cv2.imread("10.png", 0)
blob0 = cv2.dnn.blobFromImage(img0, 1/255., size=(28,28), swapRB=True, crop=False)
blob1 = cv2.dnn.blobFromImage(img1, 1/255., size=(28,28), swapRB=True, crop=False)
np.copyto(h_input, np.concatenate((blob0, blob1), axis=0).ravel())
# 创建context并进行推理
with engine.create_execution_context() as context:
# Transfer input data to the GPU.
cuda.memcpy_htod_async(d_input, h_input, stream)
# Run inference.
context.execute_async_v2(bindings=[int(d_input), int(d_output)], stream_handle=stream.handle)
# Transfer predictions back from the GPU.
cuda.memcpy_dtoh_async(h_output, d_output, stream)
# Synchronize the stream
stream.synchronize()
# Return the host output. 该数据等同于原始模型的输出数据
pred = np.argmax(h_output.reshape(2, 10), axis=1)
print(pred)
C++推理:
// tensorRT include
#include <NvInfer.h>
#include <NvInferRuntime.h>
#include <NvOnnxParser.h> // onnx解析器的头文件
// cuda include
#include <cuda_runtime.h>
#include <opencv2/opencv.hpp>
// system include
#include <stdio.h>
#include <fstream>
inline const char* severity_string(nvinfer1::ILogger::Severity t)
{
switch (t)
{
case nvinfer1::ILogger::Severity::kINTERNAL_ERROR: return "internal_error";
case nvinfer1::ILogger::Severity::kERROR: return "error";
case nvinfer1::ILogger::Severity::kWARNING: return "warning";
case nvinfer1::ILogger::Severity::kINFO: return "info";
case nvinfer1::ILogger::Severity::kVERBOSE: return "verbose";
default: return "unknow";
}
}
class TRTLogger : public nvinfer1::ILogger
{
public:
virtual void log(Severity severity, nvinfer1::AsciiChar const* msg) noexcept override
{
if (severity <= Severity::kINFO)
{
if (severity == Severity::kWARNING)
printf("\033[33m%s: %s\033[0m\n", severity_string(severity), msg);
else if (severity <= Severity::kERROR)
printf("\033[31m%s: %s\033[0m\n", severity_string(severity), msg);
else
printf("%s: %s\n", severity_string(severity), msg);
}
}
} logger;
std::vector<unsigned char> load_file(const std::string & file)
{
std::ifstream in(file, std::ios::in | std::ios::binary);
if (!in.is_open())
return {};
in.seekg(0, std::ios::end);
size_t length = in.tellg();
std::vector<uint8_t> data;
if (length > 0)
{
in.seekg(0, std::ios::beg);
data.resize(length);
in.read((char*)& data[0], length);
}
in.close();
return data;
}
void inference()
{
// ------------------------------ 1. 准备模型并加载 ----------------------------
TRTLogger logger;
auto engine_data = load_file("lenet.engine");
// 执行推理前,需要创建一个推理的runtime接口实例。与builer一样,runtime需要logger:
nvinfer1::IRuntime* runtime = nvinfer1::createInferRuntime(logger);
// 将模型从读取到engine_data中,则可以对其进行反序列化以获得engine
nvinfer1::ICudaEngine* engine = runtime->deserializeCudaEngine(engine_data.data(), engine_data.size());
if (engine == nullptr)
{
printf("Deserialize cuda engine failed.\n");
runtime->destroy();
return;
}
nvinfer1::IExecutionContext* execution_context = engine->createExecutionContext();
cudaStream_t stream = nullptr;
// 创建CUDA流,以确定这个batch的推理是独立的
cudaStreamCreate(&stream);
// ------------------------------ 2. 准备好要推理的数据并搬运到GPU ----------------------------
int input_numel = 2 * 1 * 28 * 28;
float* input_data_host = nullptr;
cudaMallocHost(&input_data_host, input_numel * sizeof(float));
cv::Mat image0 = cv::imread("2.png", 0);
image0.convertTo(image0, CV_32FC1, 1.0f / 255.0f);
float* pimage = (float*)image0.data;
for (int i = 0; i < 28 * 28; i++)
{
input_data_host[i] = pimage[i];
}
cv::Mat image1 = cv::imread("10.png", 0);
image1.convertTo(image1, CV_32FC1, 1.0f / 255.0f);
pimage = (float*)image1.data;
for (int i = 0; i < 28 * 28; i++)
{
input_data_host[28 * 28 + i] = pimage[i];
}
float* input_data_device = nullptr;
float output_data_host[20];
float* output_data_device = nullptr;
cudaMalloc(&input_data_device, input_numel * sizeof(float));
cudaMalloc(&output_data_device, sizeof(output_data_host));
cudaMemcpyAsync(input_data_device, input_data_host, input_numel * sizeof(float), cudaMemcpyHostToDevice, stream);
// 用一个指针数组指定input和output在gpu中的指针
float* bindings[] = { input_data_device, output_data_device };
// ------------------------------ 3. 推理并将结果搬运回CPU ----------------------------
bool success = execution_context->enqueueV2((void**)bindings, stream, nullptr);
cudaMemcpyAsync(output_data_host, output_data_device, sizeof(output_data_host), cudaMemcpyDeviceToHost, stream);
cudaStreamSynchronize(stream);
int predict_label0 = std::max_element(output_data_host, output_data_host + 10) - output_data_host;
int predict_label1 = std::max_element(output_data_host + 10, output_data_host + 20) - output_data_host - 10;
std::cout << predict_label0 << std::endl;
std::cout << predict_label1 << std::endl;
// ------------------------------ 4. 释放内存 ----------------------------
cudaStreamDestroy(stream);
execution_context->destroy();
engine->destroy();
runtime->destroy();
}
int main()
{
inference();
return 0;
}
microsoft/onnxruntime: 是一个用于运行各种机器学习模型的开源库。适合对机器学习和深度学习有兴趣的人,特别是在开发和部署机器学习模型时需要处理各种不同框架和算子的人。特点是支持多种机器学习框架和算子,包括 TensorFlow、PyTorch、Caffe 等,具有高性能和广泛的兼容性。
最近提交(Master分支:1 个月前 )
1bda91fc
### Description
Fixes the problem of running into failure when GPU inputs shuffled
between iterations. 9 天前
52a8c1ca
### Description
Enables using the MLTensor to pass data between models.
### Motivation and Context
Using MLTensor instead of ArrayBuffers reduces the number of copies
between the CPU and devices as well as the renderer and GPU process in
Chromium. 10 天前

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 6
6 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)