
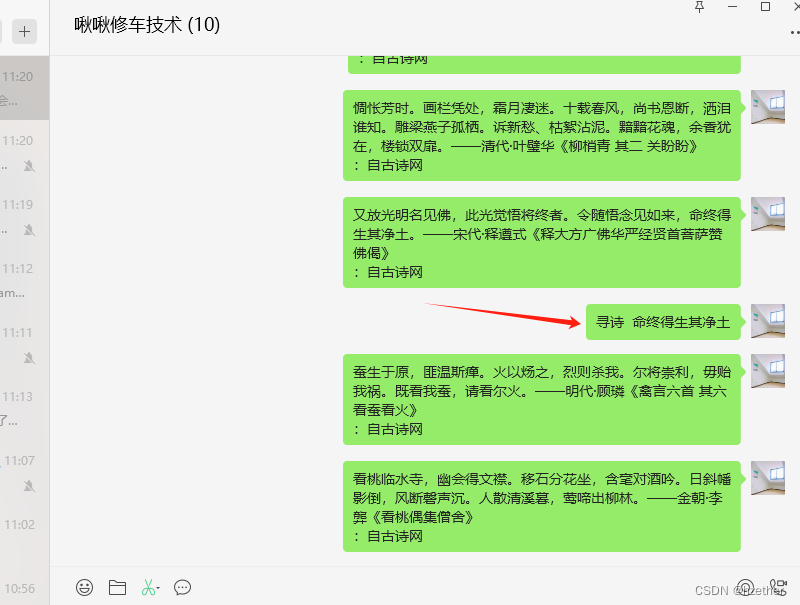
用paddleocr识别微信聊天的内容,自动发送相关的古诗
PaddleOCR
Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices)
项目地址:https://gitcode.com/gh_mirrors/pa/PaddleOCR
·
自动识别朋友或群的的发送信息
发现有人写:寻诗 XXXXX的内容,则自动去古诗网查询将得到的诗发送到微信聊天中,当然QQ聊天也可以。
这里注意的是要截取到聊天进行识别:
import sys
import time
import pyautogui
import pyperclip
from paddleocr import PaddleOCR, draw_ocr
from PIL import Image
import requests
import re
#这里使用中文识别
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
def sendWxMessage(target, msg, delay_time=2):
"""
实现原理:
通过搜索快捷键ctrl+f,打开搜索窗口
通过ctrl+v快捷键实现输入功能
通过ctrl+enter快捷键实现搜索or发送功能
:param target: 发送目标
:param msg: 需要发送的消息
:param delay_time: 延迟时间 默认2秒
:return:无返回值
"""
try:
# 清空剪切板并将目标写入到剪切板
pyperclip.copy("")
pyperclip.copy(target)
# 打开微信窗口
# pyautogui.hotkey("ctrl", "alt", "w")
# time.sleep(delay_time)
# 使用快捷键ctrl+f定位到微信搜索栏
pyautogui.hotkey("ctrl", "f")
time.sleep(delay_time)
# 使用快捷键ctrl+v将目标粘贴到微信搜索栏,微信将自动搜索
pyautogui.hotkey("ctrl", "v")
time.sleep(delay_time)
# 按回车键打开搜索出的目标
pyautogui.press("enter")
time.sleep(delay_time)
# 清空剪切板并将未点检信息写入到剪切板
pyperclip.copy("")
pyperclip.copy(msg)
# 使用快捷键ctrl+v将信息粘贴到微信输入框,按回车发送消息
pyautogui.hotkey("ctrl", "v")
time.sleep(delay_time)
pyautogui.press("enter")
# log
print("发送微信消息")
im = pyautogui.screenshot()
im.save('screenshot.png')
except Exception as ex:
print("发送微信消息出现异常: " + str(ex))
sys.exit(0)
#截取微信聊天窗口 自行调整
def cutscreen():
screenshot = pyautogui.screenshot(region=(259, 64, 703, 637))
# 如果你想将截图保存为文件
screenshot.save('screenshot_region.png')
#这里是识别文字以及输出图片
def ocrImg(language, img_path, result_img):
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False,
lang=language) # need to run only once to download and load model into memory
img_path = img_path
result = ocr.ocr(img_path, cls=True)
worlds=""
for line in result:
print(line[-1][0], line[-1][1])
#print(line)
worlds=worlds+str(line[-1][0])
# 显示结果#
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores)
im_show = Image.fromarray(im_show)
im_show.save(result_img)
return worlds #这里获取别识别的文字
#查询到古诗
def getpoems(words):
poem=""
response = requests.get("https://so.gushiwen.cn/search.aspx?value=" + words + "&valuej=" + words[0])
target_string = response.text
#print(target_string)
matches = re.findall(r'<textarea[^>]*?id="([^"]*)"', target_string)
for match in matches:
#print(match) # 打印id的值
textarea_id = match
textarea_content_pattern = re.compile(f'<textarea .*?id="{textarea_id}".*?>(.*?)</textarea>', re.DOTALL)
textarea_content_match = textarea_content_pattern.search(target_string)
if textarea_content_match:
textarea_content = textarea_content_match.group(1)
clean_text = re.sub(r"http[s]?://\S+", "", textarea_content)
if poem!="":
poem=poem+"|"+clean_text
else:
poem =clean_text
else:
poem="无此诗歌"
return poem
注意一下我的开发环境为 python 3.7 以及用的conda
以下是运行结果:

Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices)
最近提交(Master分支:4 个月前 )
0697d248
2 天前
04c989b7
6 天前

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)