
Python3.10.9安装paddleocr识别jpg图片文字,windows10
先后尝试了easyocr,ddddocr,pytessract,都失败了,只有这个测试完成,有一两个细节分享给大家
参考:使用paddleocr实现图片文字智能提取_paddleocr原理-CSDN博客
这个ocr测试安装软件少,硬件要求低,相对简单容易成功,python3.10.9,cmd命令行操作pip,
Windows10系统cpu支持avx(如果cpu不支持需要选paddleocr版本),无独立显卡,使用cpu集成显卡,
cmd命令行操作,python自带的代码编辑器,
pip install paddleocr
还有各种辅助用的pip安装上,
下载模型解压缩后放到以下目录中,
https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar
https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar
https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_det_infer.tar
https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_rec_infer.tar
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
解压缩后分别放到以下目录中:
C:\Users\Administrator\.paddleocr\whl\det\ch_PP-OCRv4_det_infer
C:\Users\Administrator\.paddleocr\whl\rec\ch_PP-OCRv4_rec_infer
C:\Users\Administrator\.paddleocr\whl\cls\ch_ppocr_mobile_v2.0_cls_infer
图片放到Python310\目录下,程序文件py也放在这里
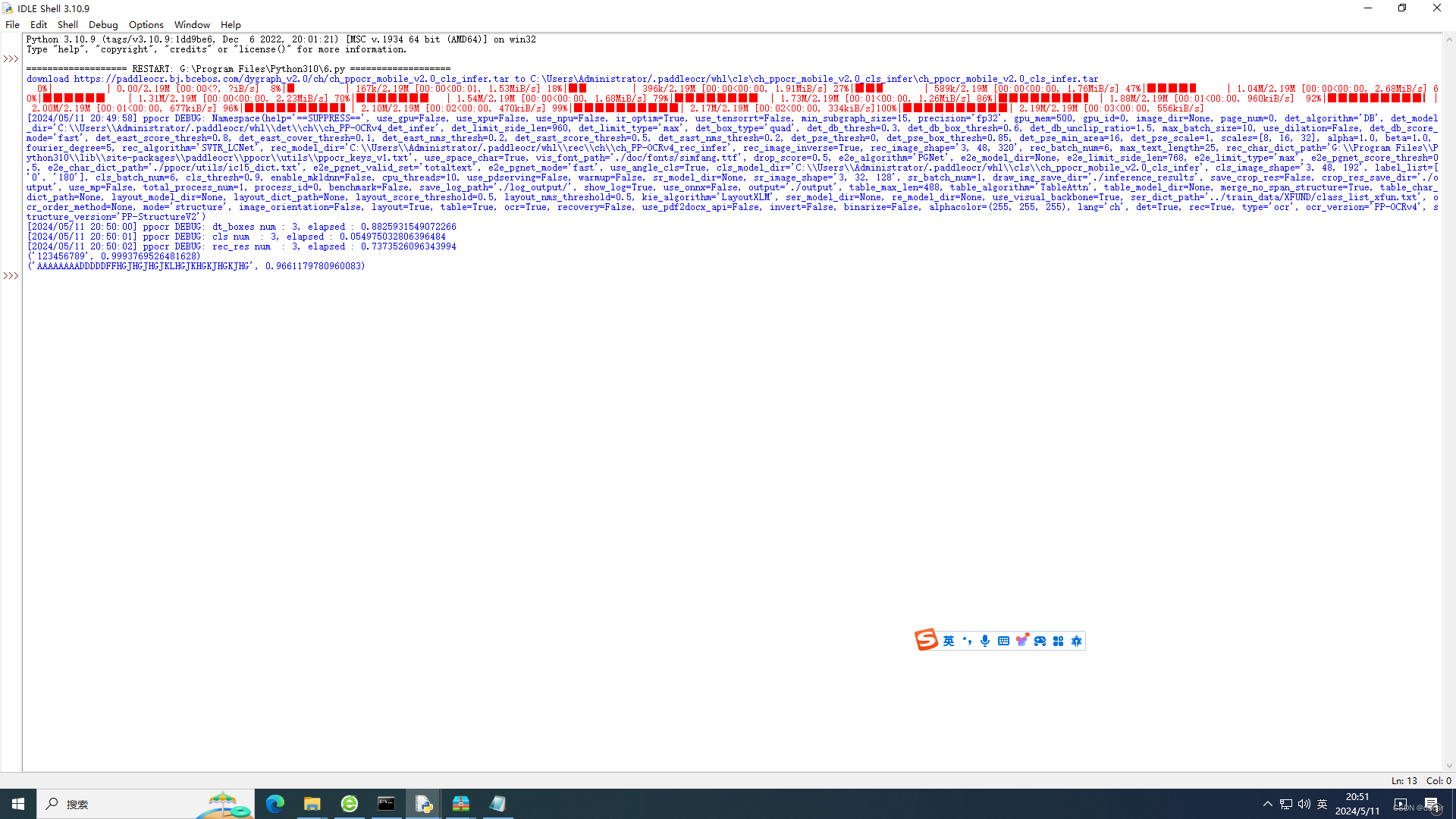
这是程序,以及运行后的结果:
from paddleocr import PaddleOCR
from PIL import Image
import numpy as np
image = Image.open('11.jpg')
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False, ocr_version='PP-OCRv4')
text = ocr.ocr(np.asarray(image), cls=True)
for t in text[0]:
print(t[1])识别了数字和字母,没有识别中文:

代码:
from paddleocr import PaddleOCR
image2 = r"11.jpg"
ocr = PaddleOCR(use_angle_cls=False, lang="ch")
result = ocr.ocr(image2, cls=False)
content_list=[]
for idx in range(len(result)):
res = result[idx]
for line in res:
content_list.append(line[-1][0])
content=''.join(content_list)
print(content)识别了中文和英文:


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)