
关于PaddleOCR-release-2.7代码训练自己的数据集出错的记录
1、首先点名骂一下某度给的代码,我用的官方的标注工具,官方的转换代码,一训练就报错,这是就脚趾头做的代码吗??
2、https://blog.csdn.net/weixin_51302403/article/details/134818251?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-2-134818251-blog-132078422.235%5Ev43%5Epc_blog_bottom_relevance_base6&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-2-134818251-blog-132078422.235%5Ev43%5Epc_blog_bottom_relevance_base6
参考这个大佬的连接,解决了问题了,
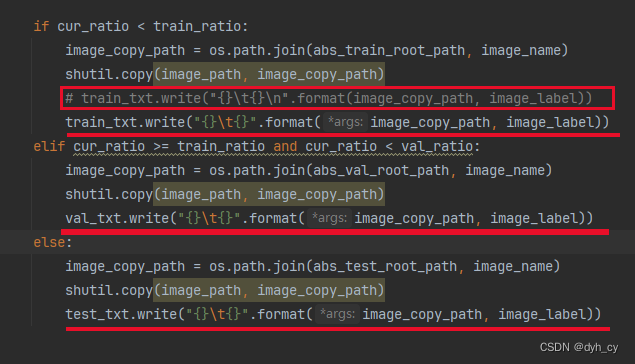
主要就是删掉代码中的\n,如图所示,红线标出来的地方都改了,再次运行就可以了

具体报错如下:
ppocr ERROR: When parsing line G:\zifu_shibie\train_data\rec\train\enhanced_
控制台会无限输出list out of range的报错
2、昨天标注的数据集训练会出现乱码,而且检测出来的字符不全,怀疑是数据集不够多,我就标注了100张
于是又多标注了一些,想着说吧两次标注的图片,crop_img直接复制过去,还有Label.txt和rec_gt.txt直接修改了就行了,结果是复制过去运行报错
但是在划分数据集的时候出现这个问题,运行的代码是
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath=G:\zifu_shibie\origin222
其中\n部分的代码,也就是gen_ocr_train_val_test.py这里边的三个\n已经按照上述说明删除了。
Traceback (most recent call last):
File “gen_ocr_train_val_test.py”, line 149, in
genDetRecTrainVal(args)
File “gen_ocr_train_val_test.py”, line 96, in genDetRecTrainVal
splitTrainVal(root, recAbsTrainRootPath, recAbsValRootPath, recAbsTestRootPath, recTrainTxt, recValTxt,
File “gen_ocr_train_val_test.py”, line 32, in splitTrainVal
image_relative_path, image_label = label_record_info.split(‘\t’)
网上也没找到解决办法,折腾到大半夜也没找到啥问题
 如图所示,reg_gt.txt和Label.txt的最后只能有一个空行,这两个文件,多了空行,就会出现上述问题,尤其是两次分开标注,在复制文件时,要注意看看,记事本看不出来,用pycharm’可以
如图所示,reg_gt.txt和Label.txt的最后只能有一个空行,这两个文件,多了空行,就会出现上述问题,尤其是两次分开标注,在复制文件时,要注意看看,记事本看不出来,用pycharm’可以
最后经过多次对比,发现reg_gt.txt多了一行,就是最后一行多了一个空行,估计是我回车了,删除空行后,重新运行数据集划分代码,问题解决

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)