
使用PaddleOCR在Ubuntu上实现一键截屏OCR提取文本
PaddleOCR
Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices)
项目地址:https://gitcode.com/gh_mirrors/pa/PaddleOCR
·
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
一、项目简介
1.1 简要说明
- 最近在折腾Ubuntu,有一个截屏然后OCR提取文本的应用需求。
- 在Windws上这样的工具很好找,但是在Linux没有现成的软件可用,得自己解决。
- 网上流行的方案是使用tesseract,试了一下,效果并不好,中文能给识别出一堆乱码。
- 于是想到PaddleOCR有预训练模型可以用,于是尝试了一下。
- 这里把用到的两个脚本文件ocr.py和ocr.sh一起放到了这个项目中,fork本项目后可直接下载使用。
1.2 效果对比
- 先来看看tesseract的效果:
- 上图是在放大了4倍之后用tesseract设别的,可以看到明显的错误:
- “[源代码]”给识别成了“(JAC 53)”,这就太离谱了
- 出现了一个不想要的空行(第二行)
- 出现了无法识别的内容(第四行)
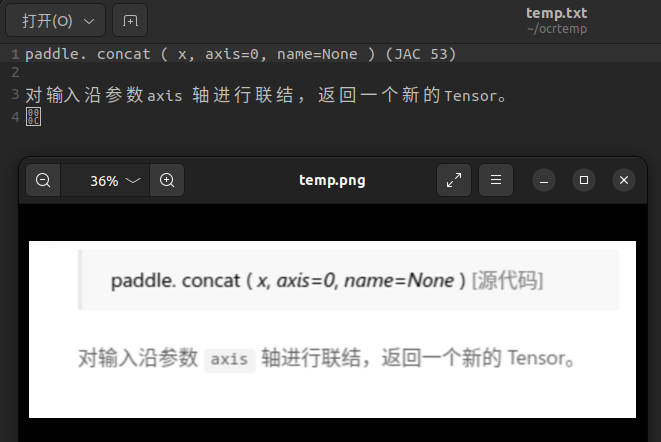
- 同样的内容,再看看PaddleOCR的效果:
- 上图是在没有进行放大的情况下用PaddleOCR调默认模型识别的结果,除了把数字“0”识别成了字母“o”之外,没有其他错误,这个效果就好太多了。


二、环境准备
- 操作系统是Ubuntu22.04
- 需要使用几个软件包:
- 截屏工具(必需):sudo apt install gnome-screenshot
- 图片放大工具(可以不用):sudo apt install imagemagick
- 剪切板工具(可以不用):sudo apt install xclip
- PaddleOCR直接安装就好:pip install paddleocr
三、实现思路
- 流程设计
- Step1 快捷键触发截屏,保存图片
- Step2 调PaddleOCR识别图片中的文字,输出识别结果
- Step3 展示识别结果
- 实施方案
- Ubuntu可以自定义快捷键
- 虽然可以用python脚本来完成所有操作,但是一方面代码量太大不便于实现,另一方面python的速度不会太快,所以考虑除了推理和结果处理部分使用python,其余操作都用shell脚本来完成
- 于是需要一个python脚本,用来执行推理和结果处理
- 还需要一个shell脚本,用来截屏、调python脚本、展示处理结果
四、创建python脚本文件
- 创建一个python脚本文件,名为 ocr.py 并填充以下内容
#!/usr/bin/env python3
# copy from https://aistudio.baidu.com/aistudio/projectdetail/5665249
from paddleocr import PaddleOCR, draw_ocr
import sys
import getopt
from PIL import Image
# 执行ocr并写入txt文件
def exe_ocr(img_path,file_txt = "result.txt",img_result = "result.jpg"):
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=False, lang="ch") # need to run only once to download and load model into memory
result = ocr.ocr(img_path, cls=False)
res = result[0] # 因为只有一张图片,所以结果只有1个,直接取出
boxes = [] # 检测框坐标
txt = "" # 检测识别结果
for line in res:
#print(line[1][0])
txt += line[1][0]+"\n" # 取出文本
boxes.append(line[0]) # 取出检测框
with open(file_txt, 'w')as f: # 以w方式打开,没有就创建,有就覆盖
f.write(txt)
image = Image.open(img_path).convert('RGB') # 读取原图片
im_show = draw_ocr(image, boxes) # 画检测框
im_show = Image.fromarray(im_show) # 转换
im_show.save(img_result) # 保存
# 主函数
def main(argv):
img_path = "" # 图片路径
file_txt = "result.txt" # 输出的文本文件路径
img_result = "result.jpg" # 检测结果图片路径
# 解析参数
# "hi:o:": 短格式分析串, h 后面没有冒号, 表示后面不带参数; i 和 o 后面带有冒号, 表示后面带参数
# ["help", "input_file=", "output_file="]: 长格式分析串列表, help后面没有等号, 表示后面不带参数; input_file和output_file后面带冒号, 表示后面带参数
# 返回值包括 `opts` 和 `args`, opts 是以元组为元素的列表, 每个元组的形式为: (选项, 附加参数),如: ('-i', 'test.png');
# args是个列表,其中的元素是那些不含'-'或'--'的参数
opts, args = getopt.getopt(argv[1:], "hi:o:", ["help", "input_file=", "output_file="])
for opt, arg in opts:
if opt in ("-h", "--help"):
print('python3 ocr.py -i <input_file.png> -o <output_file.txt>')
print('or: python3 ocr.py --input_file=<input_file.png> --output_file=<output_file.txt>')
sys.exit()
elif opt in ("-i", "--input_file"):
img_path = arg
elif opt in ("-o", "--output_file"):
file_txt = arg
if img_path == "":
#print("必须指定一个图片文件")
sys.exit()
img_result = file_txt[:file_txt.rindex('.')+1]+"jpg"
#print('输入图片文件为:', img_path)
#print('输出txt文件为: ', file_txt)
#print('输出result文件为: ', img_result)
exe_ocr(img_path,file_txt,img_result)
if __name__ == '__main__':
main(sys.argv)
五、创建shell脚本文件
- 创建一个shell脚本文件,名为 ocr.sh 并填充以下内容
#!/bin/env bash
# copy from https://aistudio.baidu.com/aistudio/projectdetail/5665249
# 定义一个文件基本路径,假设用户名是 pi,临时文件放在主目录下的ocrtemp下
SCR="/home/pi/ocrtemp/temp"
# 获取一个截图
# 这里用到了gnome-screenshot,需要先安装好:sudo apt install gnome-screenshot
gnome-screenshot -a -f ${SCR}.png
# 放大图片
# 如果觉得效果不好,可以尝试把图片放大
# 需要先安装一个软件包:sudo apt install imagemagick
# mogrify -modulate 100,0 -resize 400% ${SCR}.png
# OCR by paddleocr
python3 ocr.py -i ${SCR}.png -o ${SCR}.txt
# 打开文件
# 调用系统默认程序分别打开:原始图片、检测结果、识别出来的文本
xdg-open ${SCR}.png
xdg-open ${SCR}.jpg
xdg-open ${SCR}.txt
# 把文本复制到剪切板
# 需要先安装软件包:sudo apt install xclip
# 由于ocr结果一般都会有各种问题,其实并不能直接使用
# cat ${SCR}.txt | xclip -selection clipboard
# 退出
exit
六、准备目录
- 在主目录下创建临时文件夹:mkdir ocrtemp
- 把ocr.py和ocr.sh 两个文件放到主目录下
七、配置快捷键
- 在Ubuntu的系统设置里面,找到“键盘”,再找到“键盘快捷键”,然后点开“查看及自定义快捷键”
- 点开“自定义快捷键”
- 点加号新建一个快捷键
- 设置好名称和快捷键,命令指向ocr.sh
- 然后就可以使用自定义的快捷启动截屏并OCR提取文字了



总结
- 这个方案的优点是易于实现,而且代码量很小,只要照抄我的代码即可
- 由于使用的是python进行推理,速度略慢
- 第一次使用时,因为要先下载模型文件,速度会比较慢,之后就快多了
- 使用的预训练模型,效果只能说还可以,但比tesseract是强多了
- 这里为了快速使用,直接用的默认参数和模型,其实还有其他模型和参数可用,可以根据自己需要调整
- 如果有兴趣,还可以自己收集数据用PaddleOCR训练一个专属模型用用,效果会更好
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
此文章为搬运
原项目链接
Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices)
最近提交(Master分支:4 个月前 )
0d41ffc9
9 天前
d523388e
* add ppformulanet
* rename loss
* modify doc
* add export code
* modify yaml for global ref 10 天前

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 4
4 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)