

1.下载工具jTessBoxEditor.
https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/ 下载jTessBoxEditor-1.7.3.zip
2. 获取样本图像。用画图工具绘制了5张0-9的文样本图像(当然样本越多越好),如下图所示:
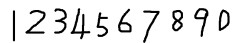
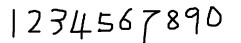
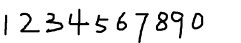
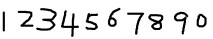
3.合并样本图像。运行jTessBoxEditor 点击Tools--->Merge TIFF。 选择多张样本图像,合并成num.font.exp0.tif文件。
4. 生成Box File文件。 打开命令行,执行命令:
1 tesseract.exe num.font.exp0.tif num.font.exp0 batch.nochop makebox
生成的BOX文件为num.font.exp0.box,BOX文件为Tessercat识别出的文字和其坐标。
注:Make Box File的命令格式为:
1 tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
其中lang为语言名称,fontname为字体名称,num为序号,可以随便定义。
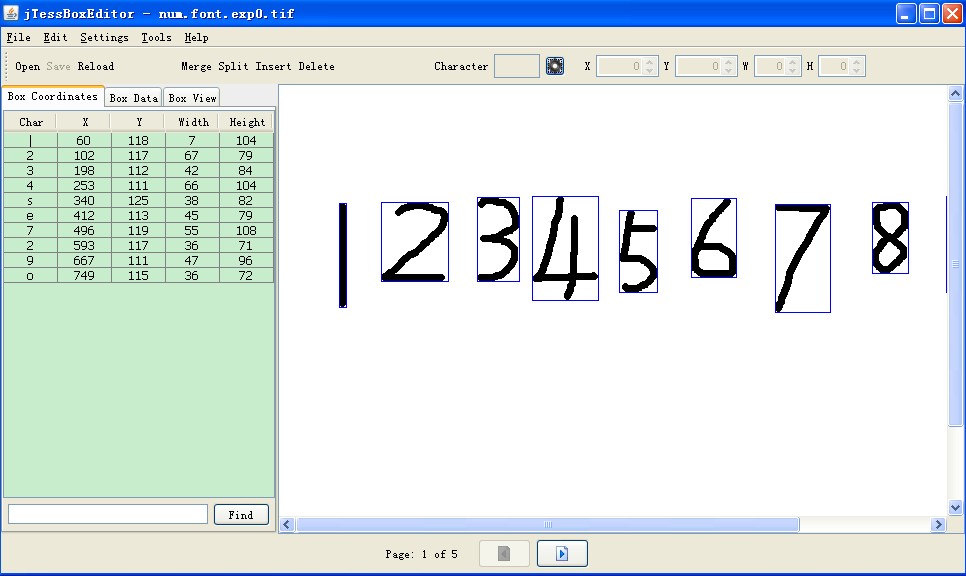
5.文字校正。运行jTessBoxEditor 打开num.font.exp0.tif(必须将上一步生成的.box和.tif样本文件放在同一目录) 手动对每张图片中识别错误的字符进行校正。校正完成后保存。
6.定义字体特征文件。Tesseract-OCR3.01以上的版本在训练之前需要创建一个名称为font_properties的字体特征文件。
font_properties不含有BOM头,文件内容格式如下:
1 <fontname> <italic> <bold> <fixed> <serif> <fraktur>
fontname为字体名称,必须与[lang].[fontname].exp[num].box中的名称保持一致。<italic> 、<bold> 、<fixed> 、<serif>、 <fraktur>的取值为1或0,表示字体是否具有这些属性。
这里在样本图片所在目录下创建一个名称为font_properties的txt文件,用记事本打开,输入以下下内容:
1 font 0 0 0 0 0
这里全取值为0,表示字体不是粗体、斜体等等。
7.生成语言文件。在样本图片所在目录下创建一个批处理文件,输入如下内容。
1 rem 执行改批处理前先要目录下创建font_properties文件
2
3 echo Run Tesseract for Training..
4 tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
5
6 echo Compute the Character Set..
7 unicharset_extractor.exe num.font.exp0.box
8 mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
9
10 echo Clustering..
11 cntraining.exe num.font.exp0.tr
12
13 echo Rename Files..
14 rename normproto num.normproto
15 rename inttemp num.inttemp
16 rename pffmtable num.pffmtable
17 rename shapetable num.shapetable
18
19 echo Create Tessdata..
20 combine_tessdata.exe num.
1.产生字符特征文件
tesseract num.font.exp0.tif num.font.exp0 nobatch box.train
这一步将会产生 num.font.exp0.tr文件和一个num.font.exp0.txt文件,txt文件貌似没什么用,看看而以。
2.计算字符集
unicharset_extractor num.font.exp0.box
3.这一步会产生一个unicharset字符集文件.
定义字体特征文件,---Tesseract-OCR3.01以上的版本在训练之前需要创建一个名称为font_properties.txt的字体特征文件
4.手工建立一个文件font_properties.txt
内容如:num 0 0 0 0 0
注意:这里必须与训练名中的名称保持一致,填入下面内容 ,这里全取值为0,表示字体不是粗体、斜体等等。
5.聚集字符特征
1) shapeclustering -F font_properties.txt -U unicharset num.font.exp0.tr 注意:如果font_properties不加扩展名.txt,可能会报错
2) mftraining -F font_properties.txt -U unicharset -O num.unicharset num.font.exp0.tr
使用上一步产生的字符集文件unicharset,来生成当前新语言的字符集文件num.unicharset。同时还会产生图形原型文件inttemp和每个字符所对应的字符
特征数文件pffmtable。最重要的就是这个inttemp文件了,他包含了所有需要产生的字的图形原型。
3)cntraining num.font.exp0.tr
这一步产生字符形状正常化特征文件normproto。
6.把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件前面都加上num.
7.执行combine_tessdata num.
然后把num.traineddata放到tessdata目录
执行后的结果如下:
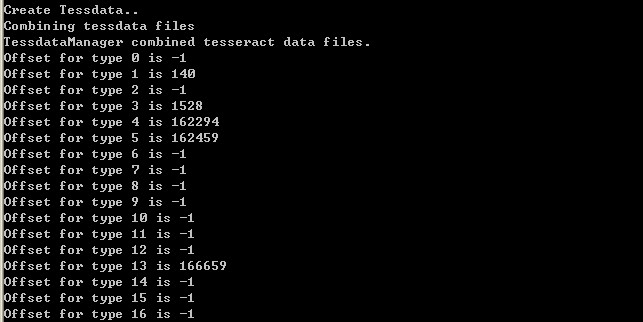
需确认打印结果中的Offset 1、3、4、5、13这些项不是-1。这样,一个新的语言文件就生成了。
num.traineddata便是最终生成的语言文件,将生成的num.traineddata拷贝到Tesseract-OCR-->tessdata目录下。可以用它来进行字符识别了。
A.ImageMagick是什么?
ImageMagick是一个用于查看、编辑位图文件以及进行图像格式转换的开放源代码软件套装
我在这里之所以提到ImageMagick是因为某些图片格式需要用这个工具来转换。
B.Leptonica 是什么?
Leptonica 是一图像处理与图像分析工具,tesseract依赖于它。而且不是所有的格式(如jpg)都能处理,所以我们需要借助imagemagick做格式转换。
Here's a summary of compression support and limitations:
- All formats except JPEG support 1 bpp binary.
- All formats support 8 bpp grayscale (GIF must have a colormap).
- All formats except GIF support 24 bpp rgb color.
- All formats except PNM support 8 bpp colormap.
- PNG and PNM support 2 and 4 bpp images.
- PNG supports 2 and 4 bpp colormap, and 16 bpp without colormap.
- PNG, JPEG, TIFF and GIF support image compression; PNM and BMP do not.
- WEBP supports 24 bpp rgb color.
C.提高图片质量?
识别成功率跟图片质量关系密切,一般拿到后的验证码都得经过灰度化,二值化,去噪,利用imgick就可以很方便的做到.
convert -monochrome foo.png bar.png #将图片二值化
D.我只想识别字符和数字?
结尾仅需要加digits
命令实例:tesseract imagename outputbase digits
E.训练你的tesseract
不得不说,tesseract英文识别率已经很不错了(现有的tesseract-data-eng),但是验证码识别还是太鸡肋了。但是请别忘记,tesseract的智能识别是需要训练的.
F.命令执行出现empty page!!错误
严格来说,这不是一个bug(tesseract 3.0),出现这个错误是因为tesseract搞不清图像的字符布局
转载:http://blog.csdn.net/firehood_/article/details/8433077 作者:firehood
转载:http://blog.csdn.net/liulina603/article/details/45071485 作者:liulina603





 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)