AtomGit开源社区
webdriver结合tesseract-ocr处理简单验证码
webdriver结合tesseract-ocr处理简单验证码

使用OCR自动化识别,一般识别率不是太高,处理一般简单验证码还是没问题,这里使用的是Tesseract-OCR,下载地址:http://pan.baidu.com/s/1kUGaw8R
怎么使用呢?
首先,环境变量path添加tesseract-ocr的安装路径,然后使用命令窗口查看:
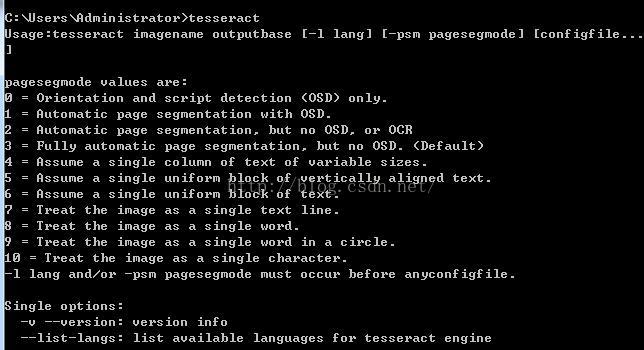
如果出现如上输出,表示安装正常。
我准备了一张验证码cp.png放在e盘tesseract目录下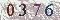 :
:

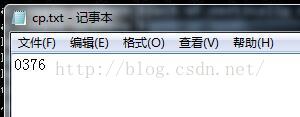
结果为:
现在,具体实践,先准备一份网页:
- <html>
- <head>
- <title>验证码</title>
- </head>
- <body>
- <form>
- <td>验证码:</td>
- <input id="cp" type="text"/>
- <img src="http://www.csti.cn/uc/index/verify.htm">
- </form>
- </body>
- </html>

要识别验证码,首先得取得验证码,首先获取整个页面的截图,然后找到页面元素坐标进行截取:
- //元素截图
- public static void captureElement(WebDriver driver, WebElement element, String path){
- // 截图整个页面
- File srcFile = ((TakesScreenshot) driver).getScreenshotAs(OutputType.FILE);
- try {
- // 获得元素的高度和宽度
- int width = element.getSize().getWidth();
- int height = element.getSize().getHeight();
- // 创建一个矩形使用上面的高度和宽度
- Rectangle rect = new Rectangle(width, height);
- // 得到元素的坐标
- Point p = element.getLocation();
- BufferedImage img = ImageIO.read(srcFile);
- BufferedImage dest = img.getSubimage(p.getX(), p.getY(), rect.width,rect.height);
- // 存为png格式
- ImageIO.write(dest, "png", srcFile);
- Thread.sleep(1000);
- FileUtils.copyFile(srcFile, new File(path));
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
截取完元素,就可以调用Tesseract-OCR生成text:
- Runtime rt = Runtime.getRuntime();
- rt.exec("cmd.exe /C tesseract e:\\tesseract\\cp.png e:\\tesseract\\cp");
- public static String readTextFile(String filePath) {
- String lineTxt = null;
- try {
- String encoding = "GBK";
- File file = new File(filePath);
- if (file.isFile() && file.exists()) { // 判断文件是否存在
- InputStreamReader read = new InputStreamReader(
- new FileInputStream(file), encoding);// 考虑到编码格式
- BufferedReader bufferedReader = new BufferedReader(read);
- while ((lineTxt = bufferedReader.readLine()) != null) {
- return lineTxt;
- }
- read.close();
- } else {
- System.out.println("找不到指定的文件");
- }
- } catch (Exception e) {
- System.out.println("读取文件内容出错");
- e.printStackTrace();
- }
- return lineTxt;
- }
- public static void main(String[] args) throws IOException, InterruptedException {
- WebDriver driver = new FirefoxDriver();
- driver.manage().window().maximize();
- driver.get("file:///E:/tesseract/cp.html");
- WebElement cp = driver.findElement(By.xpath("//img"));
- captureElement(driver, cp, "e:\\tesseract\\cp.png");
- Runtime rt = Runtime.getRuntime();
- rt.exec("cmd.exe /C tesseract e:\\tesseract\\cp.png e:\\tesseract\\cp");
- Thread.sleep(1000);
- String cp2 = readTextFile("e:\\tesseract\\cp.txt");
- driver.findElement(By.id("cp")).sendKeys(cp2);
- //driver.quit();
- }

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。



 1154
1154 0
0 0
0- 0

扫一扫分享内容
- 分享
 已为社区贡献1条内容
已为社区贡献1条内容

回到
顶部
顶部
所有评论(0)