Java OCR tesseract 图像智能字符识别技术
公司有需求啊,所以就得研究哈,最近公司需要读验证码,于是就研究起了图像识别,应该就是传说中的(OCR:光学字符识别OCR),下面把今天的收获整理一个给大家做个分享。
本人程序用的tesseract,官方地址:https://code.google.com/p/tesseract-ocr/,不为别的,谁让它支持我们的天朝的文字呢~哈
下载好程序后解压:
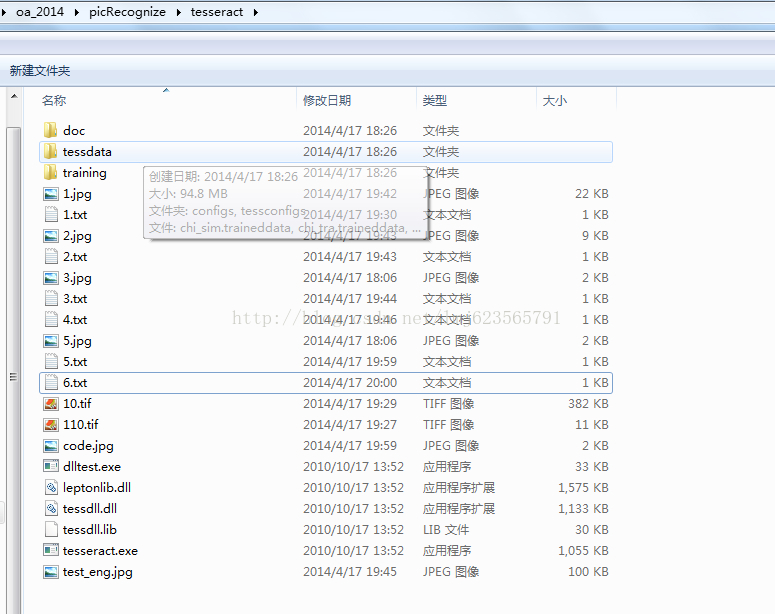
大概可以看到这样一个目录,别见怪楼主里面一堆测试文件。
然后就开始我们的测试之旅:
tesseract的用法:
参数1:需要识别的文件
参数2:输出的文件名称,输出的是文本文件,里面保存了识别的信息
识别英文这两个参数就可以了,下面做个实验:

我们在命令行输入:tesseract 5.jpg 6 ,可以看到程序生成了一个6.txt ,里面保存着识别后的文本,怎么样简单又给力~
上面说道tesseract 是支持中文的,所以么,接下来看看如何使用tesseract 实现我们中文的识别,下面继续介绍其他参数
参数3:-l
参数4: 使用的语言库
参数3 -l应该是知道参数4所使用的语言库,默认英文,也就是为什么上面识别英文的例子,并没有输入参数3和参数4,也实现了识别。
下面继续我们的实验:
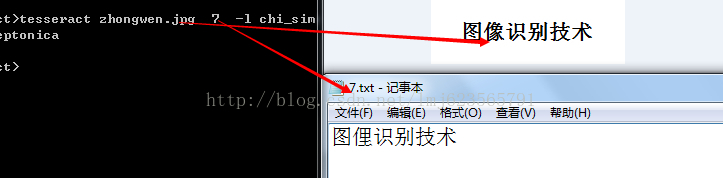
我们准备了一张图片,然后使用tesseract zhongwen.jpg 7 -l chi_sim 指明了中文语言,然后效果图上,还是很不错的,毕竟我们的中文是如此的博大精深,并且tesseract可以经过训练,然后识字的能力就会大幅度提升。
好了,由于一行代码没写,就不上传代码了,大家自己去官网下载。接下来我会使用Java带大家实现这样的小程序。
如果这篇文章对你有用,就赞一个~欢迎大家留言,多交流~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)