
Java OCR tesseract 图像智能字符识别技术 Java代码实现
公司有需求啊,所以就得研究哈,最近公司需要读验证码,于是就研究起了图像识别,应该就是传说中的(OCR:光学字符识别OCR),下面把今天的收获整理一个给大家做个分享。
本人程序用的tesseract,官方地址:https://code.google.com/p/tesseract-ocr/,不为别的,谁让它支持我们的天朝的文字呢~哈
下载好程序后解压:
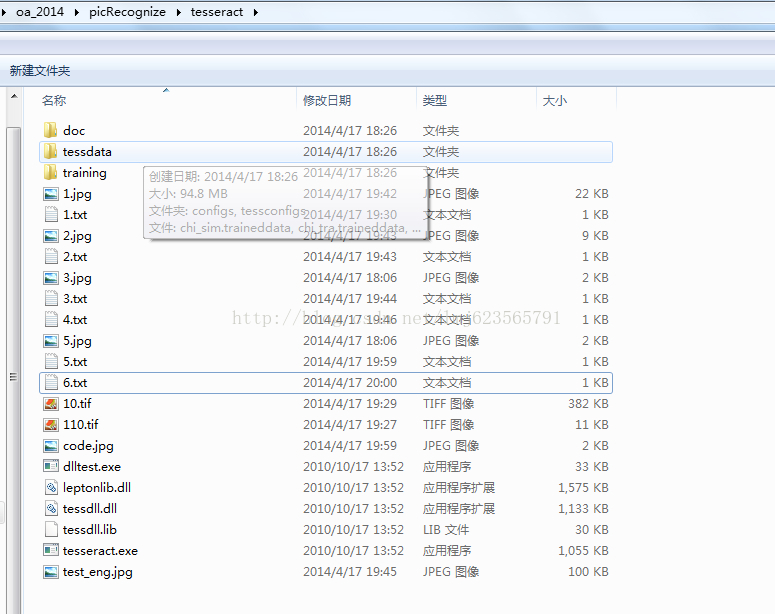
大概可以看到这样一个目录,别见怪楼主里面一堆测试文件。
然后就开始我们的测试之旅:
tesseract的用法:
参数1:需要识别的文件
参数2:输出的文件名称,输出的是文本文件,里面保存了识别的信息
识别英文这两个参数就可以了,下面做个实验:

我们在命令行输入:tesseract 5.jpg 6 ,可以看到程序生成了一个6.txt ,里面保存着识别后的文本,怎么样简单又给力~
上面说道tesseract 是支持中文的,所以么,接下来看看如何使用tesseract 实现我们中文的识别,下面继续介绍其他参数
参数3:-l
参数4: 使用的语言库
参数3 -l应该是知道参数4所使用的语言库,默认英文,也就是为什么上面识别英文的例子,并没有输入参数3和参数4,也实现了识别。
下面继续我们的实验:
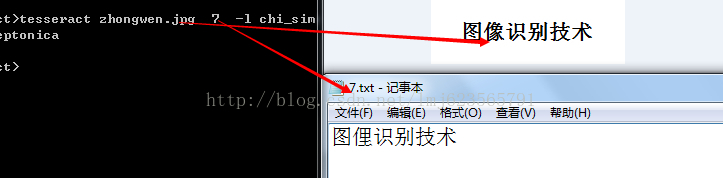
我们准备了一张图片,然后使用tesseract zhongwen.jpg 7 -l chi_sim 指明了中文语言,然后效果图上,还是很不错的,毕竟我们的中文是如此的博大精深,并且tesseract可以经过训练,然后识字的能力就会大幅度提升。
好了,由于一行代码没写,就不上传代码了,大家自己去官网下载。接下来我会使用Java带大家实现这样的小程序。
接着上一篇OCR所说的,上一篇给大家介绍了tesseract 在命令行的简单用法,当然了要继承到我们的程序中,还是需要代码实现的,下面给大家分享下Java实现的例子。

拿代码扫描上面的图片,然后输出结果。主要思想就是利用Java调用系统任务。
下面是核心代码:
代码很简单,中间那部分ProcessBuilder其实就类似Runtime.getRuntime().exec("tesseract.exe 1.jpg 1 -l chi_sim"),大家不习惯的可以使用Runtime。
测试代码:
输出结果:
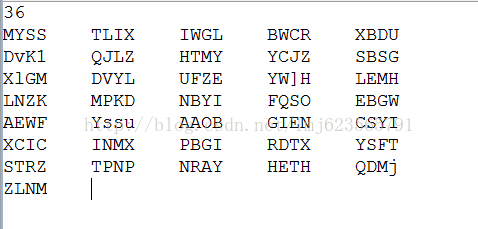
对比第一张图片,是不是很完美~哈哈 ,当然了如果你只需要实现验证码的读写,那么上面就足够了。下面继续普及图像处理的知识。
-------------------------------------------------------------------我的分割线--------------------------------------------------------------------
当然了,有时候图片被扭曲或者模糊的很厉害,很不容易识别,所以下面我给大家介绍一个去噪的辅助类,绝对碉堡了,先看下效果图。
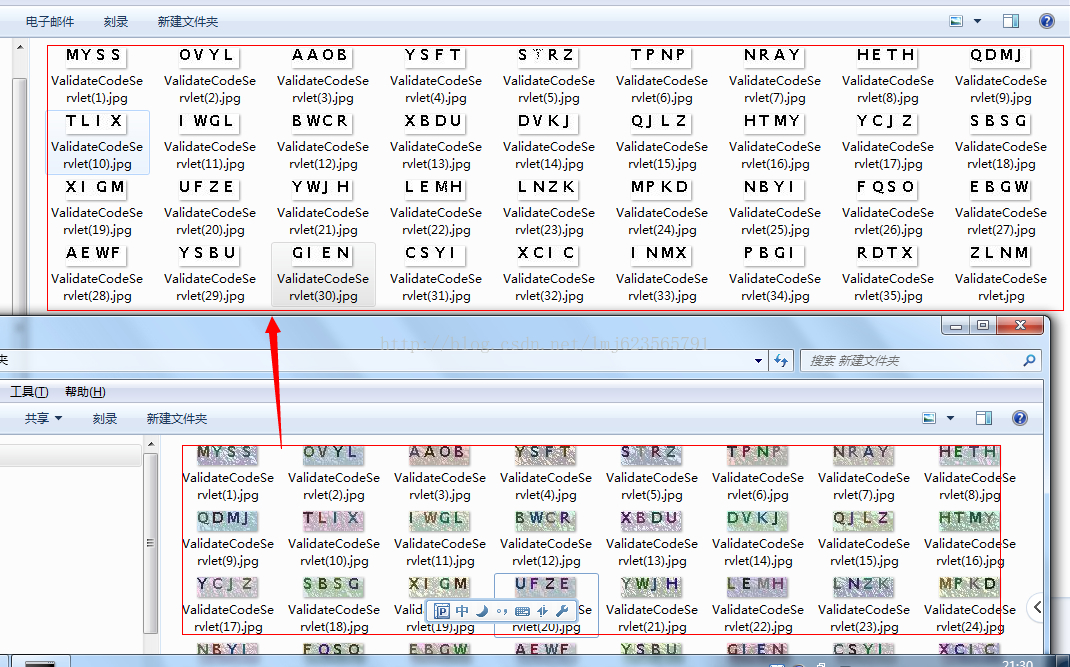
来张特写:

一个类,不依赖任何jar,把图像中的干扰线消灭了,是不是很给力,然后再拿这样的图片去识别,会不会效果更好呢,嘿嘿,大家自己实验~
代码:
--------------------------------------------------------------------------------另外一篇文章-------------------------------------------------------------------------------------------------------------------------------------
Tesseract,这里就在这里分享下。
1、Tesserac-ocr简介[一个Google支持的开源的OCR图文识别开源项目。去持多语言(当前3.02 版本支持包括英文,简体中文,繁体中文),支持Windows,Linux,Mac OSX 多平台。使用中Tesseract 的识别率非常高。可以在项目网站下载:http://code.google.com/p/tesseract-ocr,新版本支持中文,中文语言包定义http://code.google.com/p/tesseract-ocr/downloads/detail?name=chi_sim.traineddata.gz。]
2、Tesseract安装+ U2 E4 O# `2 [+ @这里使用的版本为Tesseract3.02。直接点击上面的链接,下载windows下的安装文件tesseract-ocr-setup-3.02.02.exe。由于上面的链接经常很难打开,因此在这里提供百度云链接:http://pan.baidu.com/s/1mg21nMK
安装tesseract-ocr-setup-3.02.02.exe。安装成功后会在相应磁盘上生成一个Tesseract-OCR目录。如图我是安装到了如下位置

安装完成打开命令行,输入tesseract,展现如下图说明已经安装成功

3、命令行测试使用
接下来就可以使用tesseract进行图片识别了。准备一副待识别的图像,这里用画图工具随便写了一段字,然后定义成1.jpg

在命令行中定位到图片路径然后输入命令:

tesseract 1.jpg result -l eng
其中result表示输出结果文件txt名称,eng表示用以识别的语言文件为英文。会发现图片当前目录下生成了1个result.txt文件里面结果为

4、增加中文语言库
安装目录下的tessdata目录存放的是语言识别包,如果想增加中文识别功能,可以将中文的语言库放到此目录下,下载链接在下面地址:http://pan.baidu.com/s/1hqnGq4c,下载后将解压出的chi_sim.traineddata放到此目录下。然后调用的时候指明语言库即可,例如:tesseract xxx.jpg result -l chi_sim
照样,我们搞一个2.jpg图片,来测试下中文识别下的识别率怎么样。

执行后结果

,可以看到,识别率并不是十分令人满意。而且这边使用的例子都是十分正规的字体。如果遇到验证码那种不规则的字体,识别率也会大打折扣的。
当然可以参考网上的相关资料进行对Tesseract字符识别进行样本训练,通过使用训练后的语言库会提高识别精度。这里就不做演示了。参考地址:
http://blog.csdn.net/yasi_xi/article/details/8763385 。但是遗憾的是使用的工具jTessBoxEditor不支持中文训练。附带jTessBoxEditor1.0 下载地址:http://pan.baidu.com/s/1sjBe5el
5、使用java调用tesseract
那如何使用java程序调用相应的tesseract进行操作呢?
这里介绍2种方式。
一种是使用cmd方式,另外一种就是使用tess4j。tess4j的源码地址 http://sourceforge.jp/projects/sfnet_tess4j/ 中文首页
感兴趣的自己下载查看源代码。
由于范例代码较多就不一一贴出来了,会在文章结尾提供一个下载链接,大概讲下结构,

如上图,tess4j包下是使用tess4j调用tesseract,src下的dll文件是需要使用到的。同时,加载的语言库文件也要放到tessdata目录下。而cmd 包下是使用cmd方式调用的范例,额外需要swingx-1.6.1.jar,调用时直接配置使用的安装的路径,并配置语言库即可。

代码下载地址,由于附带了data文件,jar包等,所以会比较大,接近50M。导入到工程即可。各个包下都有测试的Test类,直接右键就可以运行。前提是对应目录下有相应图片。
在cmd包下ClearImageHelper这个类是对图片进行处理的类,比如灰度转换,二值化,缩放等等,对于复杂图片可以先进行处理,来提高图片识别率。而tess4j下也封装了图片处理的工具类,基本都包含这些功能,例子中也给出了部分样例。
Bty,话说使用原生态识别调用,跟tess4j得到的结果还是有所差别的。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)