
Jmeter使用tesseract识别图片验证码
tesseract
tesseract-ocr/tesseract: 是一个开源的光学字符识别(OCR)引擎,适用于从图像中提取和识别文本。特点是可以识别多种语言,具有较高的识别准确率,并且支持命令行和API调用。
项目地址:https://gitcode.com/gh_mirrors/te/tesseract
·
准备
-
将tess4j-3.4.8.jar 文件复制到jmeter的 lib/ext 文件夹下
链接:百度网盘 请输入提取码
提取码:5suc
-
解压Tess4J-3.4.8-src.zip文件,将文件中的 Tess4J/lib 文件夹的jar包复制到jmeter的lib 文件夹下(注意:如果文件夹下已存在可以不需要复制)
 https://download.csdn.net/download/radar333/88629544
https://download.csdn.net/download/radar333/886295443、解压后的 Tess4J\tessdata 文件夹,放到自己需要使用的文件目录,后面代码会使用到
识别方法
方法1:验证码让程序员帮忙处理,写死固定的验证码
方法2:通过图片识别(本文主要说明该方法)
使用
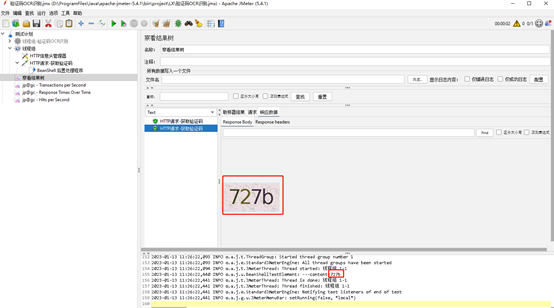
打卡Jmeter,创建线程组和请求,这里已获取验证码接口为请求,添加后置处理器,后置处理器填写如下代码
后置处理器脚本:
import java.io.*;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
String projectPath = System.getProperty("user.dir");
String imgPath= projectPath + "/project/LX/yanzhengma.jpg";//将验证码保存到本地文件中
byte[] responseBody = prev.getResponseData();
File imageFile = new File(imgPath);
FileOutputStream out = new FileOutputStream(imageFile);
out.write(responseBody);
out.flush();
out.close();
File imageFile1 = new File(imgPath);//读取图片数字
//Tesseract instance = new Tesseract();
ITesseract instance = new Tesseract();
instance.setDatapath(projectPath + "/project/LX/tessdata"); //上面第3步的目录
instance.setLanguage("eng");//英文库识别数字比较准确
content = instance.doOCR(imageFile1).replace("\n", "");
content = content.replace(" ", "");
log.info("---content:" + content);
vars.put("yanzhengma",content);执行测试

tesseract-ocr/tesseract: 是一个开源的光学字符识别(OCR)引擎,适用于从图像中提取和识别文本。特点是可以识别多种语言,具有较高的识别准确率,并且支持命令行和API调用。
最近提交(Master分支:1 个月前 )
bc490ea7
Don't check for a directory, because a symbolic link is also allowed.
Signed-off-by: Stefan Weil <sw@weilnetz.de>
2 个月前
2991d36a - 3 个月前

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)