Python+Tesseract实现自己的OCR无限次识别(保姆级)
·
本文创建自己的OCR,实现无限次图片识别,没一个字废话
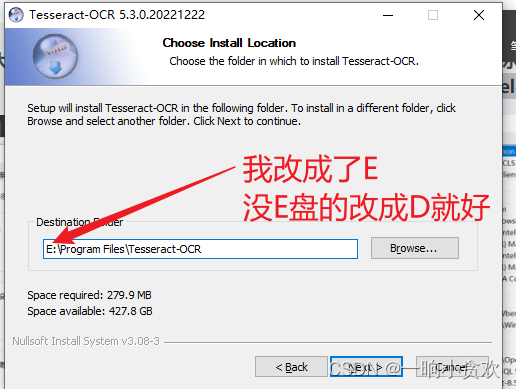
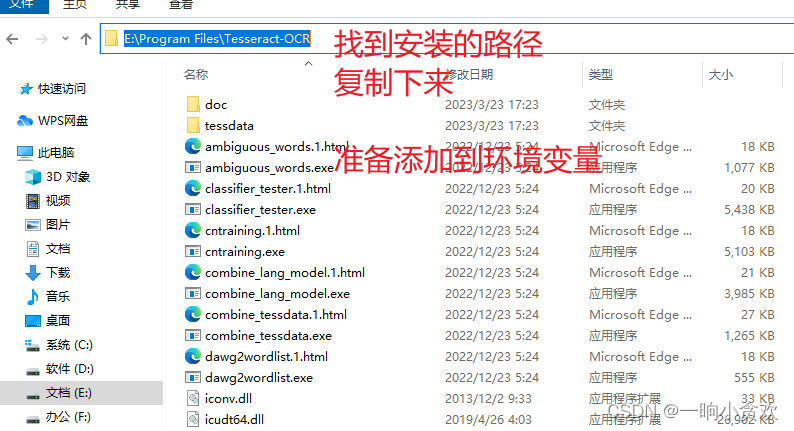
第 1 步、下载安装 Tesseract,官方链接:点我
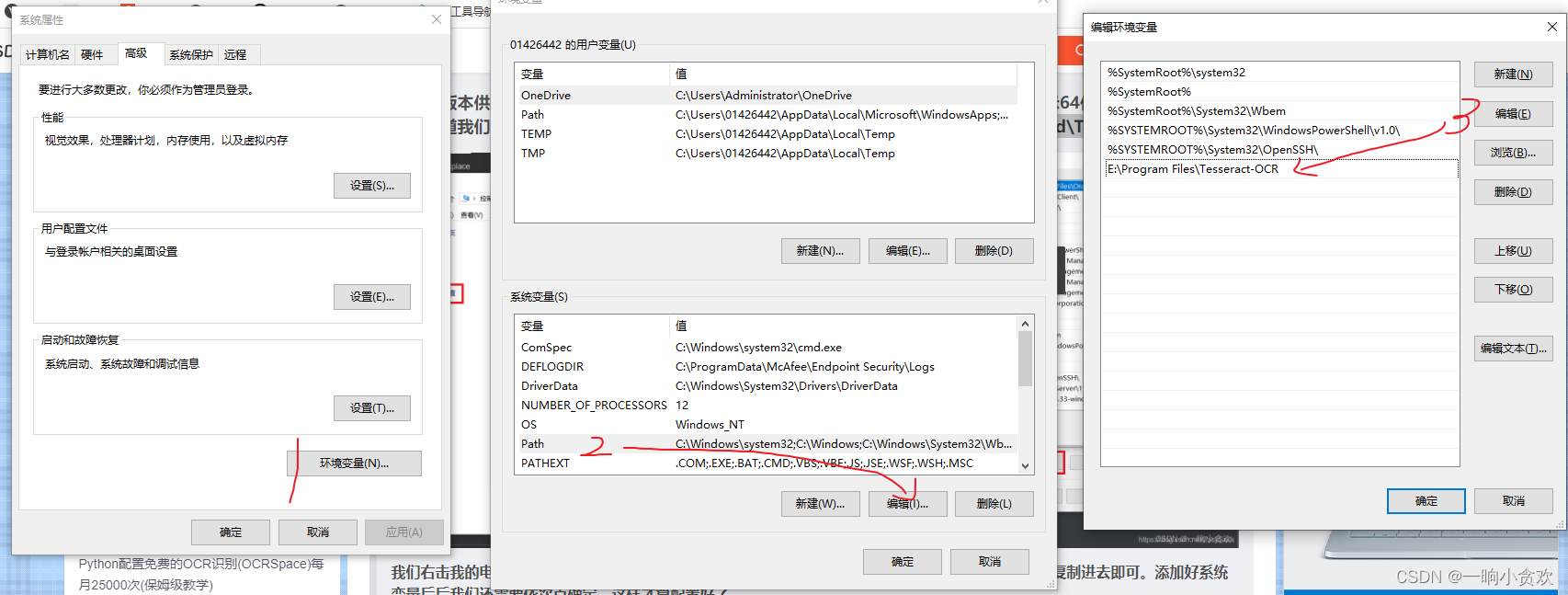
第 2 步准备添加环境变量
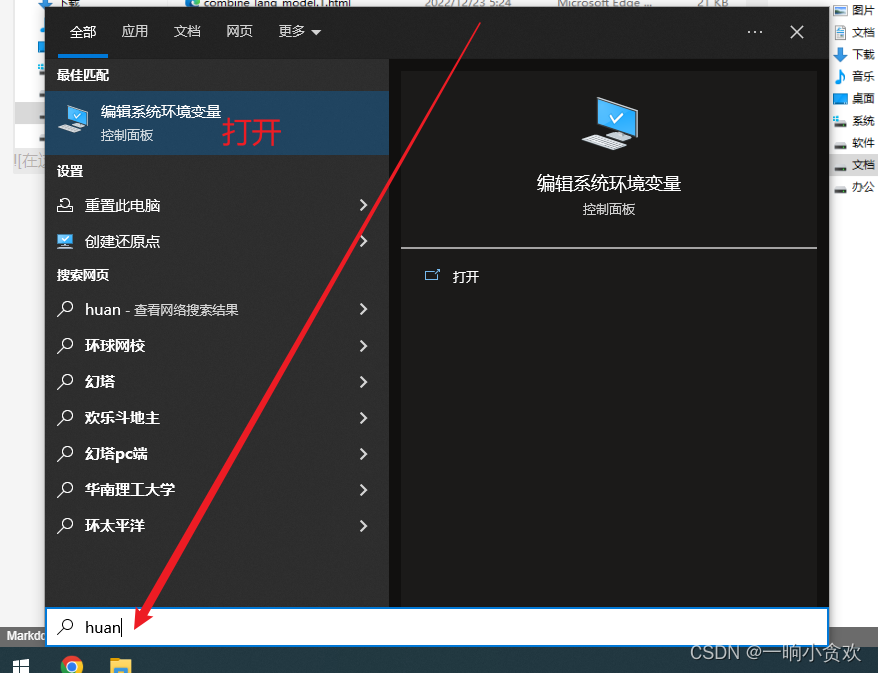
添加好后,点击确定
第 3 步,下载语言包,默认不持支中文,中文包下载:点我
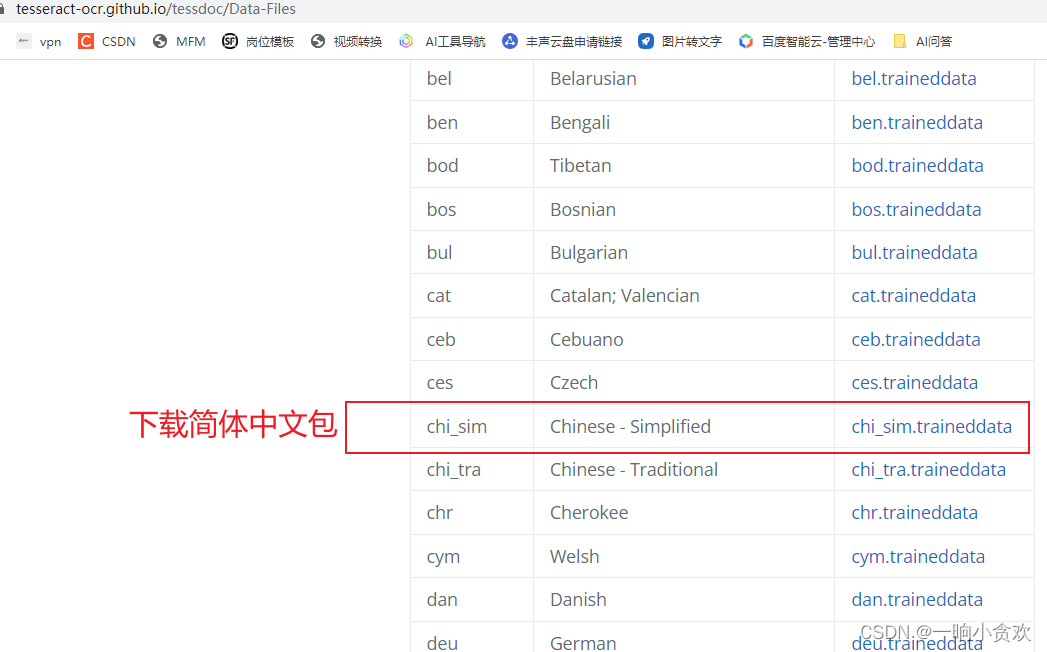
下载成功

下载慢的,或者下载不了的,能不能关注+收藏+点赞,然后我就会给你
重要的一步:
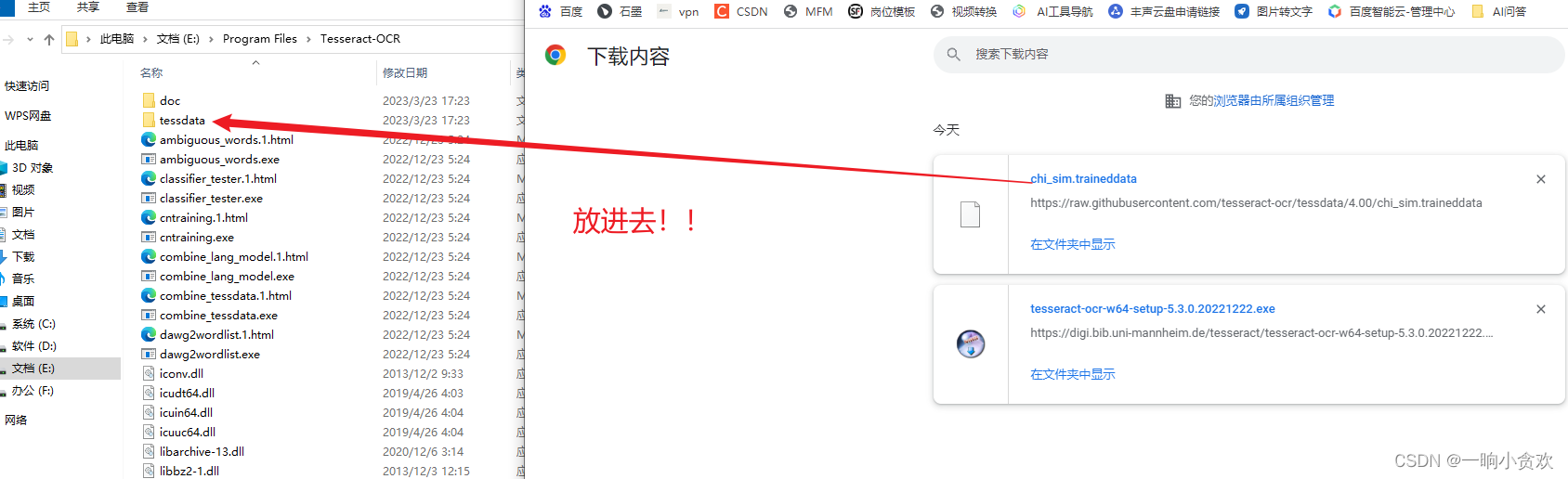
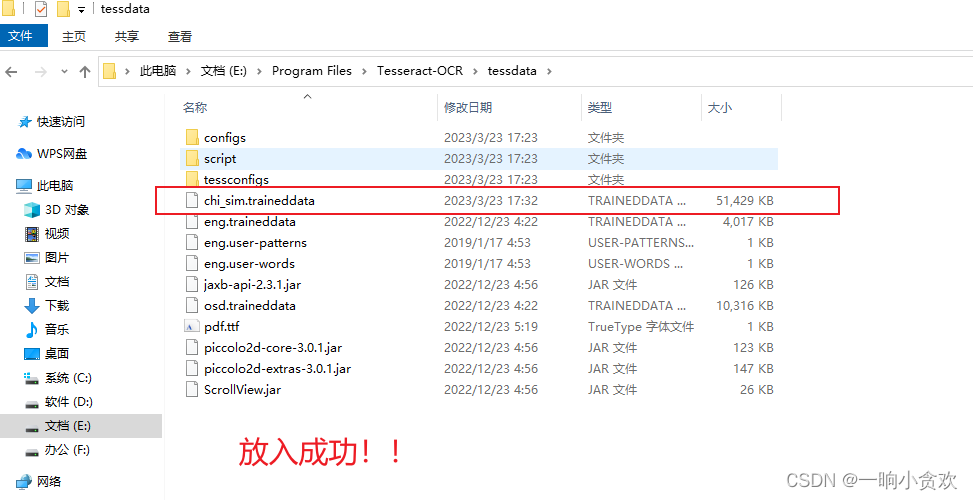
下载完成后我们需要将文件内chi_sim.traineddata放到Tesseract的路径下的tessdata目录下
实践出真知
| 库 | 安装 |
|---|---|
| pytesseract | pip install pytesseract |
import pytesseract
from PIL import Image
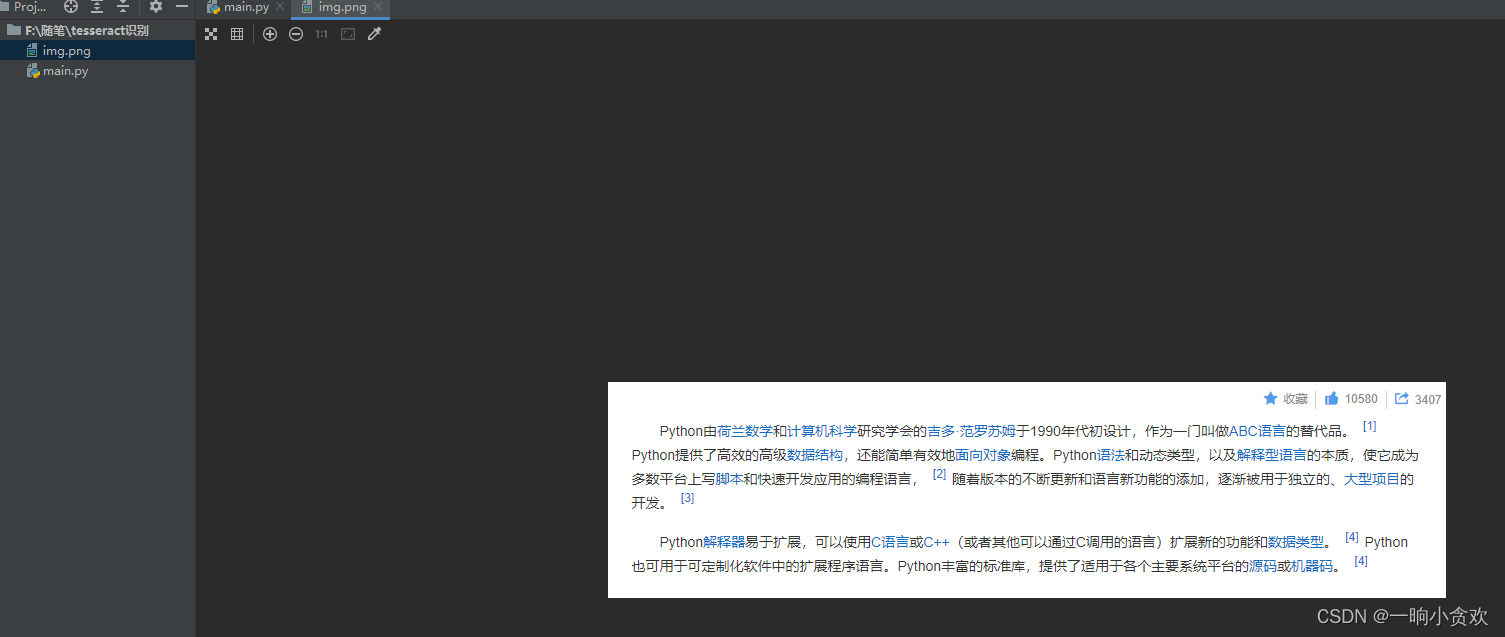
img = Image.open("img.png")
string = pytesseract.image_to_string(img, lang='chi_sim')
print(string)
print("----------------------------------------------------------------")
# print(path+img)
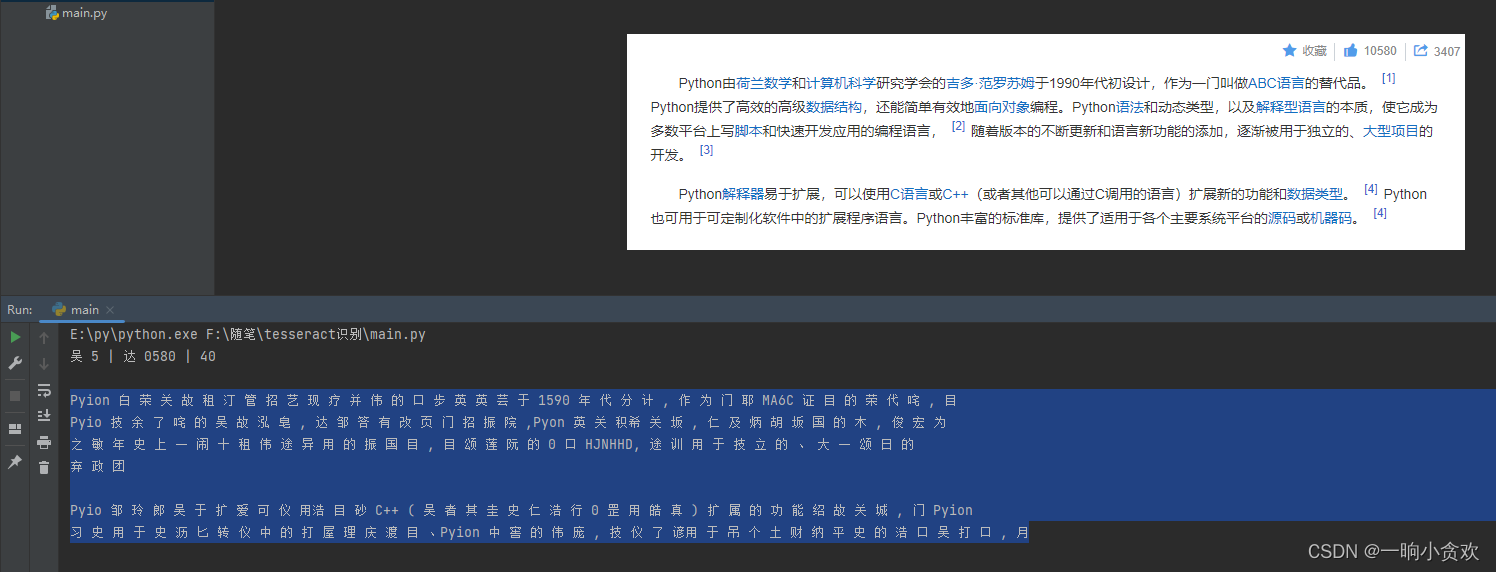
识别效果:“一坨屎”,垃圾
失望
我有后路
调用百度OCR的在这篇文章:点我
调用OCRSpace的在这篇文章:点我
希望对大家有帮助
致力于办公自动化的小小程序员一枚
致力于写出最清楚的博客
都看到这了,关注+点赞+收藏=不迷路!!

新一代开源开发者平台 GitCode,通过集成代码托管服务、代码仓库以及可信赖的开源组件库,让开发者可以在云端进行代码托管和开发。旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)