简单使用 springboot + Tesseract OCR 图片文字识别
Tesseract 是一个 OCR 库, Tesseract 是目前公认最优秀、最精确的开源 OCR 系统,除了极高的精确度,Tesseract 也具有很高的灵活性。它可以通过训练识别出任何字体,也可以识别出任何 Unicode 字符。
1.安装Tesseract-OCR
1) 首先根据需求下载需要的Tesseract版本(3.0以上支持中文),本文以 tesseract-ocr-w64-setup-v4.0.0.20181030.exe 为例
Tesseract下载: Tesseract各版本下载
a) 下载完毕后运行 .exe 文件,按提示进行安装 ;假设安装位置为: “C:\Program Files (x86)\Tesseract-OCR”
b) 增加系统变量 TESSDATA_PREFIX ,值为Tesseract-OCR 文件中的 tessdata 路 径;此处为 “C:\Program Files (x86)\Tesseract-OCR\tessdata”
c) 在 cmd 中输入 tesseract -v ,能正常显示版本信息则安装成功
2) 下载对应版本的字库
字库地址:各版本字库
下载简体中文字库 chi_sim.traineddata ,英文字库 eng.traineddata
将文件放到 tessdata 文件夹中
2.在springboot中使用
1)引入依赖
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.0.0</version>
</dependency>2)示例代码
package com.example.demo.controller;
import com.alibaba.fastjson.JSONObject;
import com.example.demo.service.TessdataServer;
import net.sourceforge.tess4j.TesseractException;
import org.springframework.web.bind.annotation.*;
import javax.annotation.Resource;
import java.io.IOException;
@RestController
@RequestMapping("/tessdata")
@CrossOrigin(value = "*", maxAge = 3600)
public class TessdataController {
@Resource
private TessdataServer server;
@RequestMapping(method = RequestMethod.POST)
public JSONObject tessdata(@RequestBody JSONObject get) throws TesseractException, IOException {
JSONObject output = new JSONObject();
String fileName = get.getString("fileName");
Boolean flag = server.dosoc(fileName);
if (flag) {
output.put("msg", "succeed");
} else {
output.put("msg", "failed");
}
return output;
}
}import org.springframework.stereotype.Service;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
@Service
public class TessdataServer {
public boolean dosoc(String fileName) throws TesseractException, IOException {
try {
File file = new File(fileName);
Tesseract tesseract = new Tesseract();
tesseract.setDatapath("E://work//Tesseract-OCR//tessdata");
tesseract.setLanguage("chi_sim");
String result = tesseract.doOCR(file);
writeObj(result);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
public void writeObj(String result) throws IOException {
String newFileName = "E:/work/test/result.txt";
try {
// 防止文件建立或读取失败,用catch捕捉错误并打印,也可以throw
/* 写入Txt文件 */
File writename = new File(newFileName);// 相对路径,如果没有则要建立一个新的output。txt文件
writename.createNewFile(); // 创建新文件
BufferedWriter out = new BufferedWriter(new FileWriter(writename, true));
out.write(result);
System.out.println("写入成功!");
out.flush(); // 把缓存区内容压入文件
out.close(); // 最后记得关闭文件
} catch (Exception e) {
e.printStackTrace();
}
}
}3)内容测试

使用 postman 进行测试
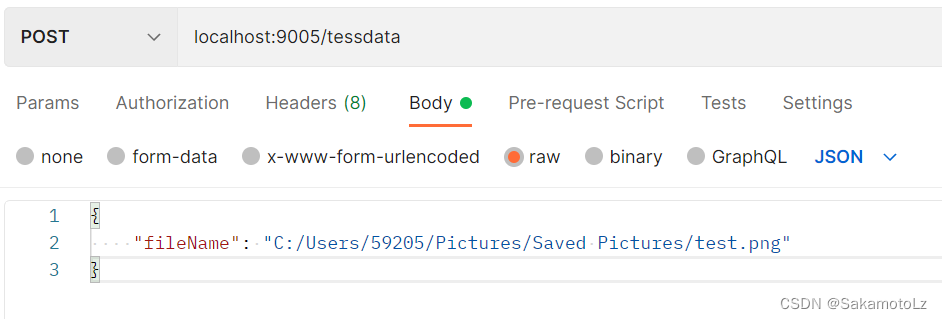
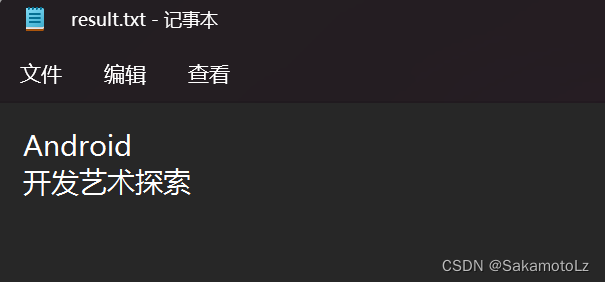
3.问题
简单使用已有字库文件进行识别的话,很多情况下识别的准确率会比较低,所以我们需要训练自己的字库文件以提高识别准确率,具体方法可以参考这篇文章 使用tesseract训练自己的字库提高识别率_SeventhBlue的博客-CSDN博客_tesseract训练自己的字库

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)