
Swin Transformer论文精读( Hierarchical Vision Transformer using Shifted Windows)
0、前言
本文主要结合博主自己看的一些Swin Transformer相关的视频和文章,对其中的核心思想和模块做一定的解释说明,下方给出Swin Transformer的原文链接和李沐老师视频课的链接:
1.原文链接: Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
2.论文讲解: Swin Transformer论文精读
1、摘要
(存在问题)Transformer以前是处理文本数据的,现在被用来处理图像会遇到两个问题:
- 视觉实体(目标)的尺度规模变化很大,并不像处理文本那样(词汇的向量都是固定比例的),比如在一个场景中有人有汽车,尺度相差较大。
- 用Transformer处理图像复杂度过高,一般与图像尺寸大小程平方倍增长。
(解决方案)因此为了解决这两个问题,这篇论文的核心贡献:
- Swin Transformer其实就是Shifted windows(移动窗口)的缩写,这篇文章的主要贡献也是这个移动窗口机制。
Swin Transformer 注意力机制是在这种移动窗口内算的,所以模型复杂度和图像大小是呈线性增长的,注意力序列大大降低,通过移动的操作,还可以让相邻的两个窗口之间有交互,变相达到了全局建模的能力,进而有了下面的Hierarchical 层级式。 - Hierarchical 层级式,可以让Transformer像卷积网络一样也能够分成几个block,做层级式的特征提取,从而使提取出来的特征有多尺度的概念
以前的Transformer中无法将图像分为很小的块,因为分成特别小的块之后,块与块之间没有交互,就失去Transformer全局建模的初衷了。但是有了 移动窗口 这个“工具”后,Transformer可以把图像分为很小的块后,块与块之间存在交互,因此进而可以实现类似于CNN中的下采样操作,进而出现了 层级式 的结构,在减少运算量的同时,融合多尺度的信息。
在后文中倒着来介绍,首先给出层级式的理念,再详述移动窗口等细节部分。
2、具体实现
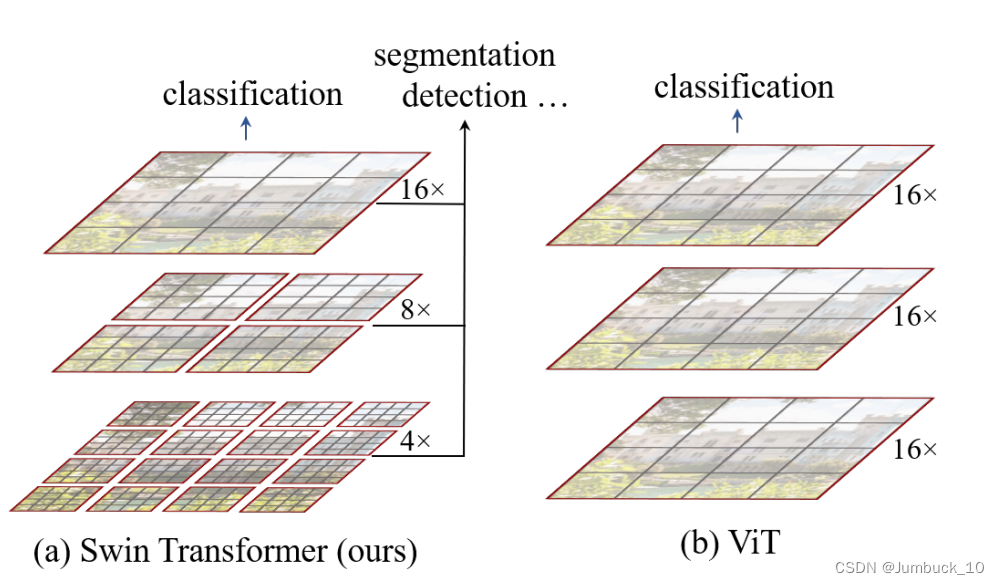
1、不同特征图的感受野融合理念(层级式)

如上图(b),以前的ViT里边从始至终处理的都是16倍下采样率过后的特征,所以它不适合处理密集预测型(目标有大有小)的任务。而且它始终是对全局进行建模,因此它的复杂度和随着图像尺寸的增加呈平方倍的增长。
分析以前一些经典的卷积神经网络:
- FPN每个阶段卷积出来的特征图感受野是不一样的,不同特征图能抓住物体不同尺寸的特征,从而能够很好处理物体不同尺寸的问题。

- UNet,上采样的时候不光是取Bottleneck里的特征图,还要去取下采样过程中的特征图。

因此,结合这些以前CNN的经典理念,如果能够在Transformer中引入不同大小的尺度图,那么它将能够解决特征尺度不丰富的问题。而卷积中能够有这么多尺度的特征图是因为它有Pooling下采样操作。
所以本篇文章的Transformer也提出了一个类似于池化的操作,叫做patch merging:把相邻的小patch合成一个大patch。所以合成的一个大patch就能看到之前四个小patch的内容,感受野就增加了,同时还能够抓到不同尺度的特征。
2、下采样理念(patch merging)
在每次完成Swin Transformer注意力运算后会进行一次patch merging“下采样”操作,将特征图宽和高变为原来的1/2,channel数变成原来的两倍。
图中上方蓝色部分即为Patch Merging操作,假设一阶段Swin-T输出后的结果为如图所示的HW样式的特征图,那首先把特征图中数字1、2、3、4即隔块取样一下,得到四个特征图,再把这四个特征图合并一下,得到(H/2)(W/2)C,的特征图,接着在C这个维度上,使用一个1×1的卷积,得到最终的结果。

3、移动窗口机制

首先按照常规的蓝色四方格,将原图分为四份,如上图中左图,接着把四方格向右下角移动,就把原图分为九份了。如果每次都像左图那么分,那么使用注意力机制的时候,每个小窗口里边的内容就无法和别的窗口里边的进行交互了,达不到使用Transformer的初衷。
而且以前只有四个窗口,现在变成了九个窗口且窗口的大小不一,因此需要一种特殊的计算方式。所以引出下文基于掩码的方式。


如上图,首先对特征图再进行一次循环移位cyclic shift,把原来的ABC位置从左上角换到右下角,如上图所示,红框变蓝框。
但现在新的问题又来了,特征图的左上角是可以做自注意力机制的,但是右边和下边的特征图都是从别的很远的地方搬过来的,它们之间不应该有太大的联系,加入C本来在上面,在图像中是天空区域,但是搬到下面跟地面拼接到了一起,求自注意力机制显然不符合常理,因此引出下文掩码操作。

上图演示了特征图左下角位置(3、6区域)的掩码操作,先将其压缩,再将其进行转置,转置前后的特征相乘得到右边这样的形式,图中的右边33、66是我们想要的注意力机制结果,而36和63则为不同区域相乘得到的结果,使我们不想要的,因此给出绿色框让它与我们得到的结果相加,最后36和63位置-100后经过ReLU操作后就变为0了。别的区域与这个操作原理也想通,就不过多赘述了。
下图为原文作者给出的可视化形式,也比较直观

3、总结
本文按照博主自己的理解介绍了Swin Transformer这篇论文,文章的核心思想其实就是围绕想实现CNN中的层级结构来展开的,为了实现这一目的,进一步设计了移动窗口Swin和patch merging下采样等操作。
Swin Transformer绝对是视觉Transformer中里程碑式的存在,还是值得大家深入理解一下论文的。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)