
Scaling Vision Transformers to 22 Billion Parameters
Scaling Vision Transformers to 22 Billion Parameters
主要贡献
-
Vision Transformer(ViT)的大规模扩展:尽管Transformer架构在自然语言处理(NLP)领域取得了巨大成功,但在计算机视觉(CV)领域,尤其是图像和视频建模方面,尚未实现与语言模型相当的规模扩展。论文提出了ViT-22B,这是一个具有220亿参数的Vision Transformer模型,是目前最大的密集ViT模型。
-
训练稳定性和效率:在扩展ViT模型到22亿参数的过程中,作者遇到了训练不稳定性的问题。为了解决这个问题,他们提出了一些架构上的改进,如并行层、查询/键(QK)归一化以及省略某些偏置项,这些改进使得模型能够在保持训练稳定性的同时,实现高效的并行训练。
-
下游任务的性能提升:通过在各种下游任务上的广泛实验,论文展示了ViT-22B在图像分类、语义分割、单目深度估计和视频分类等任务上的性能提升。特别是,即使在作为冻结特征提取器的情况下,ViT-22B也能在ImageNet上达到89.5%的准确率。
-
模型的公平性、鲁棒性和人类视觉对齐:论文还探讨了模型规模增加对模型公平性、鲁棒性和与人类视觉感知对齐的影响。研究发现,随着模型规模的增加,ViT-22B在这些方面的表现有所改善,例如在形状/纹理偏差方面达到了前所未有的87%。
-
模型的可解释性和透明度:论文通过使用特征归因分析方法,如集成梯度(Integrated Gradients),来理解ViT-22B如何做出预测,这有助于提高模型的透明度和可解释性。
Method
论文通过以下几个关键步骤解决了在计算机视觉领域扩展Vision Transformer(ViT)模型的问题:
- 架构改进:
-
并行层:将注意力和多层感知器(MLP)块并行处理,而不是顺序处理,以实现额外的并行化。
y ′ = LayerNorm ( x ) , y = x + MLP ( y ′ ) + Attention ( y ′ ) . \begin{aligned}&y^{\prime}=\text{LayerNorm}(x),\\&y=x+\text{MLP}(y^{\prime})+\text{Attention}(y^{\prime}).\end{aligned} y′=LayerNorm(x),y=x+MLP(y′)+Attention(y′).
-
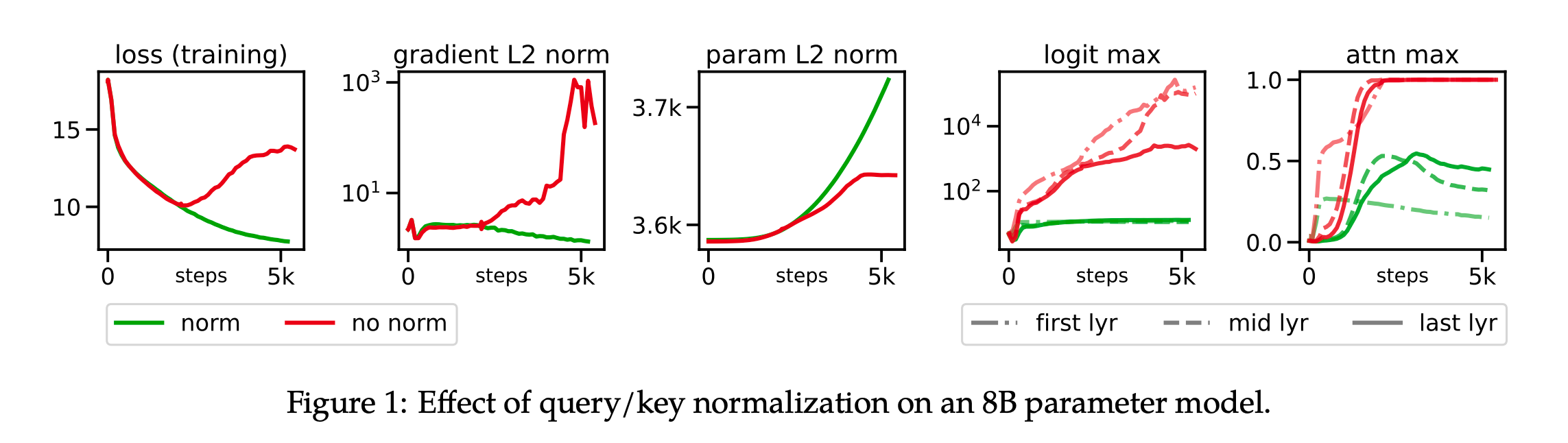
QK-Norm:在计算注意力权重之前,对查询(Q)和键(K)进行LayerNorm归一化,以防止注意力权重的发散,从而提高训练稳定性。
1 s o f t m a x [ 1 d L N ( X W Q ) ( L N ( X W K ) ) T ] , \begin{aligned}\mathbf{1}\\\mathbf{softmax}\left[\frac{1}{\sqrt{d}}\mathrm{LN}(XW^{Q})(\mathrm{LN}(XW^{K}))^{T}\right],\end{aligned} 1softmax[d1LN(XWQ)(LN(XWK))T],

- 省略偏置项:在QKV投影和LayerNorms中移除偏置项,以提高硬件利用率,同时保持或提高模型质量。

- 训练基础设施和效率:
-
使用JAX和FLAX库实现ViT-22B,利用模型和数据并行来处理大规模模型。
-
开发异步并行线性操作,以最大化矩阵乘法单元的利用率,同时最小化通信开销。
-
参数分片,允许在多个设备上分布模型参数,以适应更大的模型和批量大小。
- 实验和评估:
-
在大规模数据集(如扩展的JFT数据集)上训练ViT-22B,并在多种下游任务上评估其性能。
-
使用线性探测、锁定图像调整(Locked-image Tuning)和冻结图像特征提取器等技术,将ViT-22B应用于图像分类、语义分割、单目深度估计和视频分类任务。
-
分析模型在公平性、人类视觉对齐、鲁棒性、可靠性和校准方面的表现。
- 模型蒸馏:
- 通过知识蒸馏技术,将ViT-22B的知识压缩到较小的ViT模型中,以提高模型的可用性和部署效率。
- 通过这些方法,论文成功地训练了一个规模达到220亿参数的ViT模型,并在多个视觉任务上展示了其有效性。此外,论文还探讨了模型规模增加带来的其他好处,如改善公平性、提高与人类视觉感知的对齐程度以及增强模型的鲁棒性。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)