

对比语言图像预训练(CLIP)
虽然prompt-tuning用于textual inputs,但是建议CLIP Adapter在视觉或语言分支上使用功能适配器进行fine-tune
CLIPAdapter采用了一个额外的瓶颈层来学习新的特征,并将剩余的特征与原始的预训练特征进行混合。
为了更好地适应vision语言模型,使用功能适配器,而不是快速调整
1. Classifier Weight Generation for Few-Shot Learning
Co0P方法
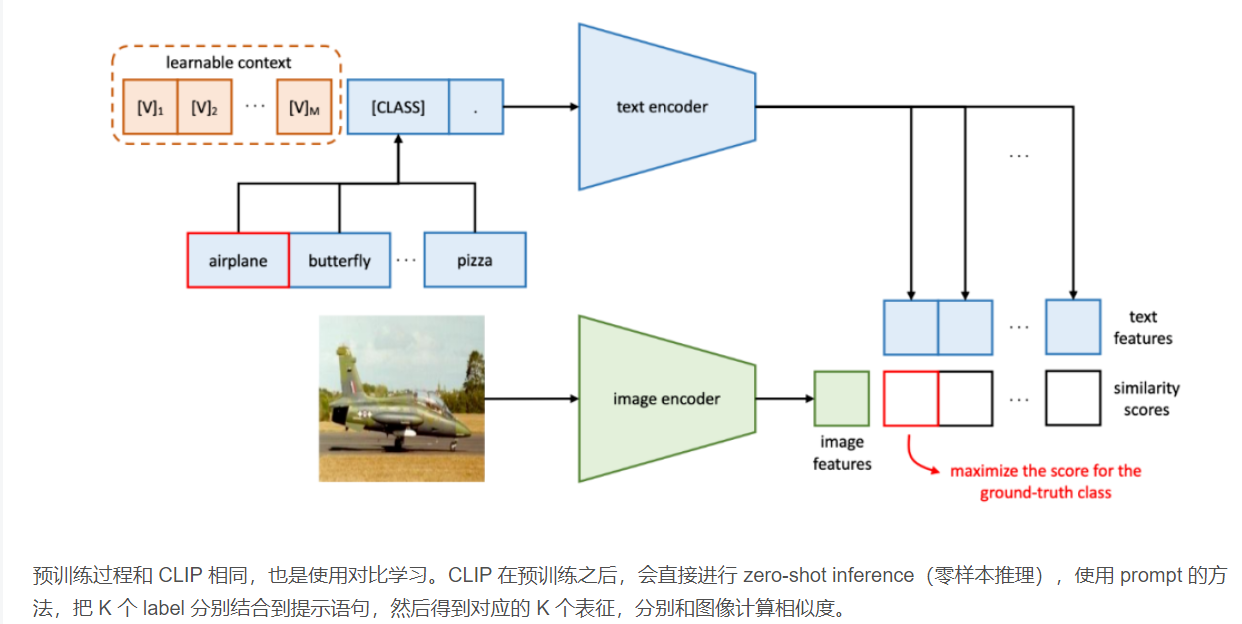

a classifier weight matrix W(D,K),D维度,K类别分类,得到K-维度 logit
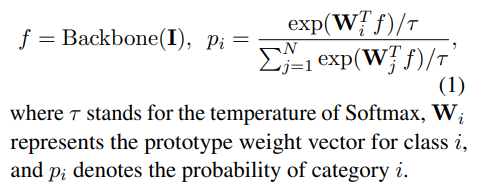
hard-prompt,pre-defined hard prompt template H.
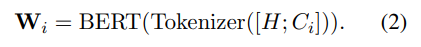
soft-prompt,random-initialized learnable soft tokens

2. CLIP Adapter
只在CLIP的语言和图像分支上附加少量可学习的瓶颈线性层,在few-shot , fine-tuning期间,保持原始clip主干冻结。
然而,使用附加层进行简单的微调在few-shot中仍然可能会陷入过度拟合。为了解决过拟合问题,提高CLIP-Adapter的鲁棒性,进一步采用残差连接,将微调后的知识与CLIP主干中的原始知识动态融合。
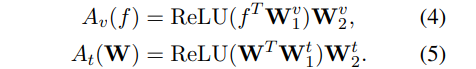
image feature f , classifier weight W
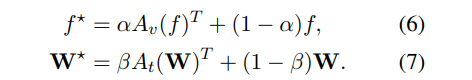

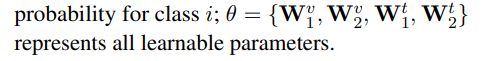






 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)